Maximum Likelihood as Orthogonal Projection
이번 장에서는 MLE의 기하학적 해석에 대해서 살펴보겠습니다. 우선 간단한 linear regresion에 대해 살펴봅니다.
\[y = x\theta + \epsilon,\quad \epsilon\sim\mathcal{N}(0, \sigma^2) \tag{9.65}\]여기서 linear functions $f:\mathbb{R}\rightarrow\mathbb{R}$ 은 원점을 지난다고 간주합니다. 파라미터 $\theta$ 는 선의 기울기를 결정합니다.
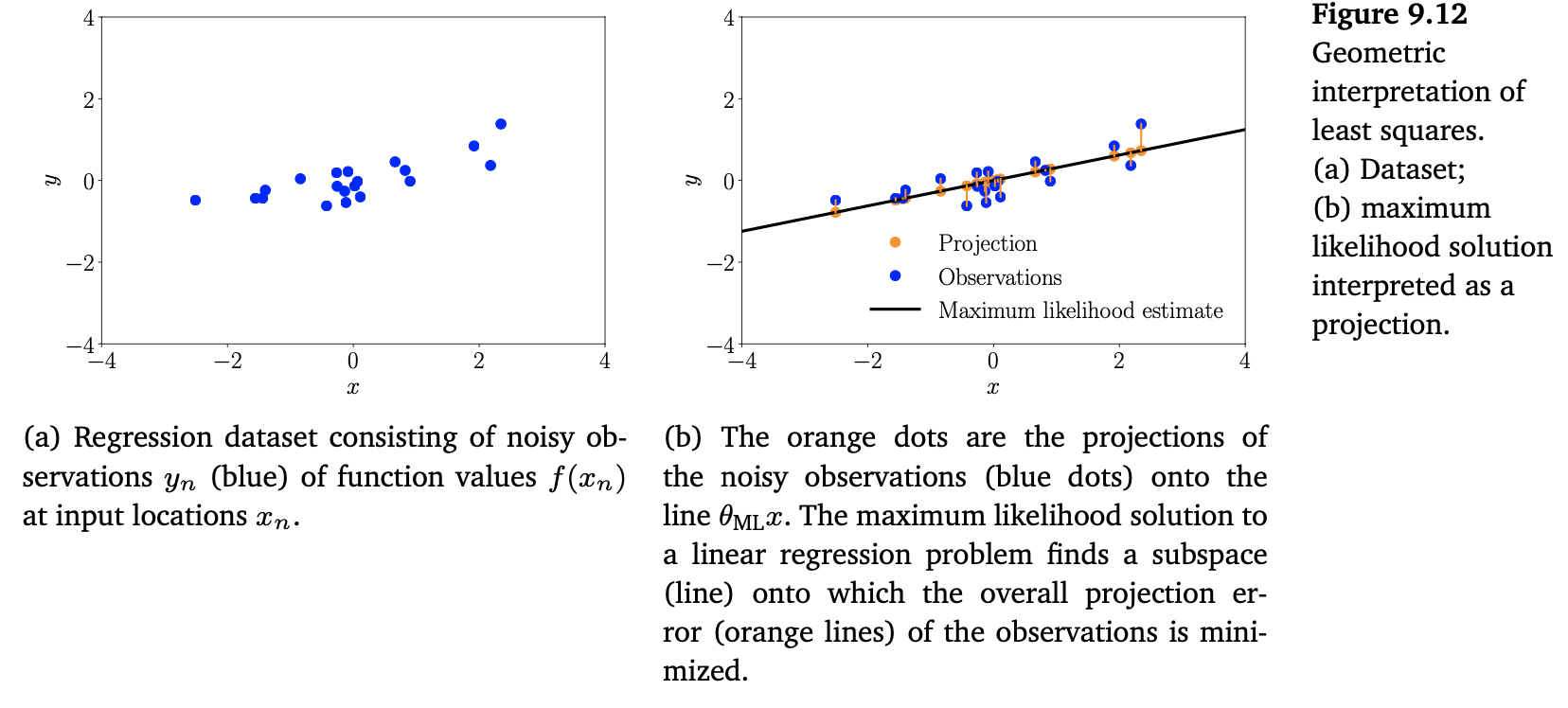
위의 Figure 9.12(a)는 1차원의 dataset을 보여줍니다.
Training data set ${(x_1,y_1),\dotsc,(x_N, y)N)}$ 을 가지고, 9.2.1장의 내용을 떠올려보면, 기울기 파라미터에 대한 MLE는 다음과 같이 얻을 수 있습니다.
\[\theta_{\text{ML}} = (\boldsymbol{X}^\top\boldsymbol{X})^{-1}\boldsymbol{X}^\top\boldsymbol{y} = \frac{\boldsymbol{X}^\top\boldsymbol{y}}{\boldsymbol{X}^\top\boldsymbol{X}}\in\mathbb{R} \tag{9.66}\]여기서 $\boldsymbol{X}=[x_1,\dotsc,x_N]^\top\in\mathbb{R}^N$, $\boldsymbol{y} = [y_1,\dotsc,y_N]^\top\in\mathbb{R}$ 입니다.
이는 training inputs $\boldsymbol{X}$ 에 대해 최적의 (maximum likelihood) reconstruction of the training targets을 다음과 같이 얻는다는 것을 의미합니다.
\[\boldsymbol{X}\theta_{\text{ML}} = \boldsymbol{X}\frac{\boldsymbol{X}^\top\boldsymbol{y}}{\boldsymbol{X}^\top\boldsymbol{X}} = \frac{\boldsymbol{X}\boldsymbol{X}^\top}{\boldsymbol{X}^\top\boldsymbol{X}}\boldsymbol{y} \tag{9.67}\]즉, $\boldsymbol{y}$ 와 $\boldsymbol{X}\theta$ 간의 minimum least-squares error를 통한 근사를 얻습니다.
$\boldsymbol{y} = \boldsymbol{X}\theta$ 의 해를 찾을 때, 이 문제를 선형방정식을 푸는 linear regression으로 생각할 수 있습니다. 따라서, 2장과 3장에서 살펴봤던 선형대수와 기하학 개념을 연관시킬 수 있습니다. 특히 (9.67) 식을 자세히 살펴보면, (9.65)에서 ML estimator $\theta_{\text{ML}}$ 이 $\boldsymbol{X}$ 에 의해 span되는 1차원 usbspace에 projection되는 $\boldsymbol{y}$ 의 orthogonal projection을 효과적으로 수행한다는 것을 알 수 있습니다. 3.8장의 orthogonal projection의 결과를 떠올려보면, $\frac{\boldsymbol{X}\boldsymbol{X}^\top}{\boldsymbol{X}^\top\boldsymbol{X}}$ 를 projection matrix로 생각할 수 있고, $\theta_{\text{ML}}$ 을 $\boldsymbol{X}$ 에 의해 span되는 $\mathbb{R}^N$ 의 1차원 subspace로의 coordinates of the projection과 같습니다.
그러므로, ML solution은 관측값 $\boldsymbol{y}$ 에 가장 가까운 $\boldsymbol{X}$ 에 대해 span되는 subspace에서 벡터를 찾는 기하학적 최적 솔루션을 제공합니다. 여기서 가깝다는 의미는 함수값 $y_n$ 에서 $x_n\theta$ 의 가장 짧은 (squared) distance라는 것을 의미합니다. 이는 orthogonal projections으로 얻을 수 있습니다. Figure 9.12(b)는 원래의 dataset과 이의 projection 간의 suqred distance를 최소화하는 subspace 위로의 noisy sbservations의 projection을 보여줍니다. 그리고 이는 ML solution에 대응됩니다.
일반적인 vector-valued features $\phi(\boldsymbol{x})\in\mathbb{R}^K$ 가 있는 linear regression 케이스
\[y=\phi^\top(\boldsymbol{x})\boldsymbol{\theta}+\epsilon,\quad\epsilon\sim\mathcal{N}(0,\sigma^2) \tag{9.68}\]에서 maximum likelihood의 결과를 feature matrix $\boldsymbol{\Phi}$ 에 의해 span 되는 $\mathbb{R}^N$ 의 K 차원 subspace로의 projection으로 해석할 수 있습니다.
\[\begin{align*} \boldsymbol{y}&\approx \boldsymbol{\Phi\theta}_{\text{ML}} \tag{9.69} \\ \boldsymbol{\theta}_{\text{ML}} &= (\boldsymbol{\Phi}^\top\boldsymbol{\Phi})^{-1}\boldsymbol{\Phi}^\top\boldsymbol{y} \tag{9.70} \end{align*}\]Feature matrix $\boldsymbol{\Phi}$ 를 구성하는데 사용하는 feature functions $\phi_k$ 가 orthonormal인 경우, $\boldsymbol{\Phi}$ 의 columns가 orthonormal basis인 특별한 케이스를 얻습니다. 따라서, $\boldsymbol{\Phi}^\top\boldsymbol{\Phi} = \boldsymbol{I}$ 입니다. 이를 다음의 projection을 유도합니다.
\[\boldsymbol{\Phi}(\boldsymbol{\Phi}^\top\boldsymbol{\Phi})^{-1}\boldsymbol{\Phi}^\top\boldsymbol{y} = \boldsymbol{\Phi\Phi}^\top\boldsymbol{y} = \left(\sum_{k=1}^K \phi_k\phi_k^\top\right)\boldsymbol{y} \tag{9.71}\]따라서, maximum likelihood projection은 단순하 각 basis vector $\phi_k$ ($\boldsymbol{\Phi}$ 의 columns) 에 대한 $\boldsymbol{y}$ 의 projections의 합입니다. 게다가, orthogonality of the basis 덕분에 다른 features 간의 결합이 사라졌습니다. 신호 처리에서 많이 사용되는 basis function은 orthogonal basis functions 입니다. Basis가 만약 orthogonal이 아니라면, Gram-Schmidt 방법을 사용하여 선형적으로 독립인 orthogonal basis로 변환할 수 있습니다.