Parameter Estimation
8.2장에서 우리는 명시적으로 probability distributions(확률 분포)을 사용하여 problem을 모델링하지 않았습니다. 8.3장에서는 observation process로 인한 불확실성과 predicators의 파라미터에서의 불확실성을 모델링하기 위해서 확률 분포를 사용하는 방법에 대해서 살펴볼 예정입니다. 8.3.1장에서는 8.2.2장에서 살펴본 empirical risk minimization의 loss function과 유사한 개념인 likelihood를 살펴봅니다. 8.3.2장에서는 regularization(8.2.3장 참조)와 유사한 개념인 priors를 살펴봅니다.
Maximum Likelihood Estimation
Maximum likelihood estimation (MLE) 의 이면에 있는 아이디어는 데이터에 잘 맞는 모델을 찾을 수 있도록 해주는 파라미터의 function을 정의하는 것입니다. 이 estimation problem은 likelihood function에 초점을 맞추는데, 좀 더 정확하게는 likelihood function에 음의 로그를 취한 함수에 초점을 맞춥니다. 확률 변수 $\boldsymbol{x}$ 에 의해 표현되는 데이터와 $\boldsymbol{\theta}$ 로 매개변수화되는 확률 밀도 $p(\boldsymbol{x}|\boldsymbol{\theta})$ family에 대해, negative log-likelihood 는 다음과 같이 주어집니다.
\[\mathcal{L}_{\boldsymbol{x}}(\boldsymbol{\theta}) = -\log p(\boldsymbol{x}|\boldsymbol{\theta}) \tag{8.14}\]$\mathcal{L}_{\boldsymbol{x}}(\boldsymbol{\theta})$ 표기는 파라미터 $\boldsymbol{\theta}$ 가 변하고, 데이터 $\boldsymbol{x}$ 는 고정되어 있다는 것을 강조합니다. Negetive log-likelihood는 실제로 $\boldsymbol{\theta}$ 에 대한 함수이기 때문에 일반적으로 $\boldsymbol{x}$ 를 빼버리는데, 문맥상 데이터에서 불확실성을 나타내는 확률 변수가 명확할 때 $\mathcal{L}(\boldsymbol{\theta})$ 로 씁니다.
확률 밀도 $p(\boldsymbol{x}|\boldsymbol{\theta})$ 가 고정된 $\boldsymbol{\theta}$ 에 대해 모델링하는 것을 해석해보도록 하겠습니다. 이는 주어진 파라미터에 대해 데이터의 불확실성을 모델링하는 분포입니다. 주어진 dataset $\boldsymbol{x}$ 에 대해, likelihood는 파라미터 $\boldsymbol{\theta}$ 의 다양한 설정에 대한 선호도를 표현할 수 있고, 데이터를 생성할 가능성이 더 높은 파라미터를 선택할 수 있도록 합니다.
Complementary 관점에서 만약 data가 고정되어 있다고(관측된 값이기 때문) 간주하고 파라미터 $\boldsymbol{\theta}$ 를 변경한다면, $\mathcal{L}(\boldsymbol{\theta})$ 가 말하는 것은 무엇일까요? 이는 특정 $\boldsymbol{\theta}$ 가 관측치(observations) $\boldsymbol{x}$ 에 대해 얼마나 가능성이 있는지 알려줍니다. 이러한 관점을 기반으로, MLE는 우리에게 데이터 집합에 대한 가장 가능성 있는 파라미터 $\boldsymbol{\theta}$ 를 알려주게 됩니다.
$\boldsymbol{x}_n\in\mathbb{R}^D$ 와 labels $y_n\in\mathbb{R}$ 을 사용한 pairs $(\boldsymbol{x}_1,y_1),\dotsc,(\boldsymbol{x}_N,y_N)$ 을 얻는 supervised learning setting에 대해 고려해보도록 하겠습니다. 우리는 feature vector $\boldsymbol{x}_n$ 을 input으로 사용하고 prediction $y_n$ 을 output으로 생성하는 predictor를 구성하는데 관심이 있습니다. 즉, vector $\boldsymbol{x}_n$ 가 주어지면 label $y_n$ 의 확률 분포를 얻길 원합니다. 다시 말하면, examples가 주어졌을 때, 특정 파라미터 $\boldsymbol{\theta}$ 에 대한 labels의 조건부 확률 분포(conditional probability distribution)를 지정합니다.
Example 8.4
자우 사용되는 예제에서는 주어진 examples에서 labels의 조건부 확률로 가우스 분포(Gaussian distribution)를 사용합니다. 다시 말해, 우리는 평균이 0인 independent Gaussian noise(6.5장 참조)으로 observation uncertainty를 설명할 수 있다고 가정합니다. 또한, linear model $\boldsymbol{x}_n^\top\boldsymbol{\theta}$ 가 예측에 사용된다고 가정합니다. 이는 각 example label pair $(\boldsymbol{x}_n,y_n)$ 에 대한 Gaussian likelihood 를 아래와 같이 정의할 수 있다는 것을 의미합니다.
\[p(y_n|\boldsymbol{x}_n,\boldsymbol{\theta}) = \mathcal{N}(y_n|\boldsymbol{x}_n^\top\boldsymbol{\theta},\sigma^2) \tag{8.15}\]주어진 파라미터 $\boldsymbol{\theta}$ 에 대한 Gaussian likelihood는 아래 그림 Figure 8.3에서 보여줍니다.
9.2장에서는 가우스 분포의 관점에서 위의 표현식을 확장하는 법에 대해 살펴봅니다.
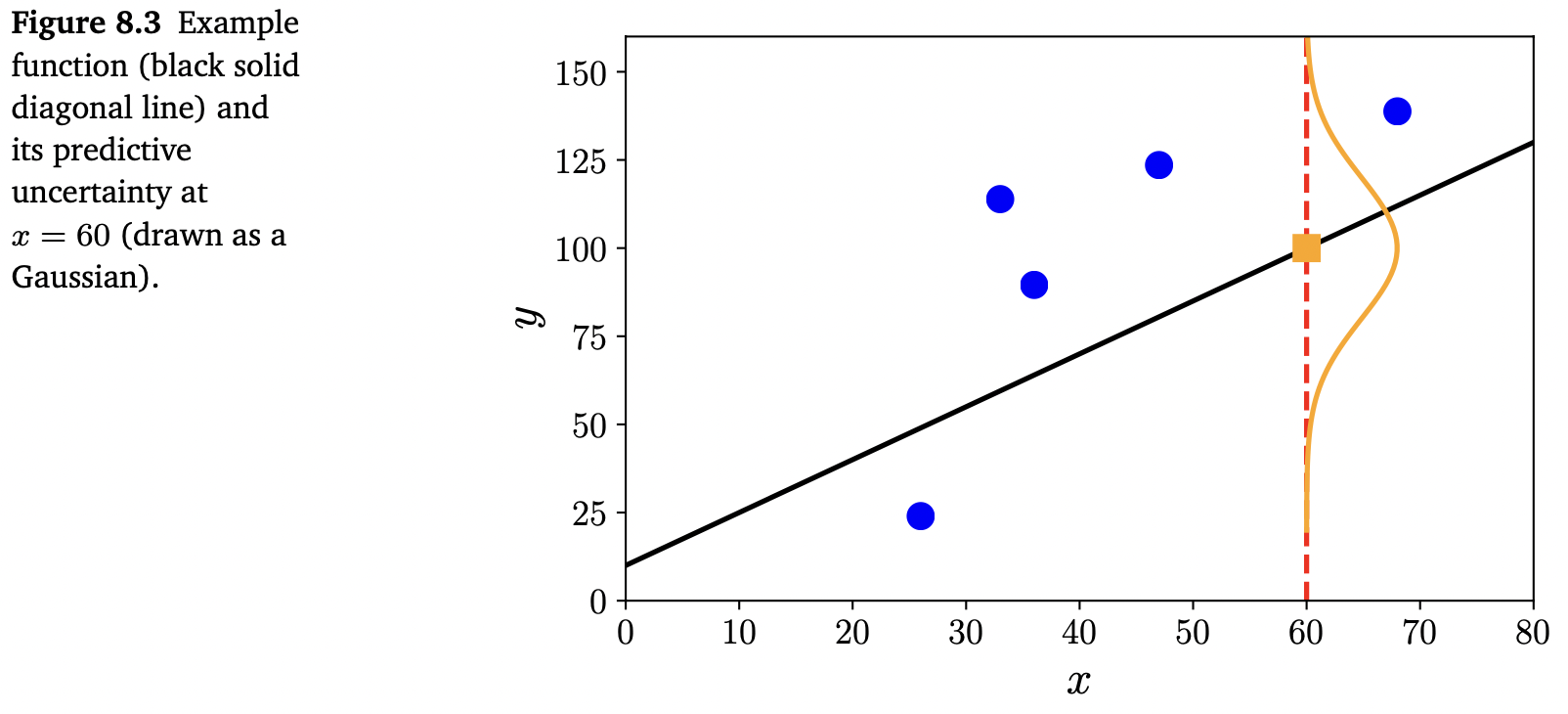
우리는 examples 집합이 i.i.d.(independent and identically distributed) 라고 가정합니다. “Independent”는 전체 dataset($\mathcal{Y}={y_1,\dotsc,y_N}$ and $\mathcal{X}={\boldsymbol{x}_1,\dotsc,\boldsymbol{x}_N}$) 를 포함하는 likelihood가 각 개별 example의 likelihood들의 곱으로 분해될 수 있다는 것을 의미합니다.
\[p(\mathcal{Y}|\mathcal{X},\boldsymbol{\theta}) = \prod_{n=1}^N p(y_n|\boldsymbol{x}_n,\boldsymbol{\theta}) \tag{8.16}\]여기서 $p(y_n|\boldsymbol{x}_n,\boldsymbol{\theta})$ 는 특정 분포(Example 8.4에서의 가우스 분포)입니다.
“Identically distributed”라는 표현은 (8.16)의 각 항이 동일한 분포를 갖고, 모두 동일한 파라미터를 공유한다는 것을 의미합니다. 최적화 관점에서는 보통 더 간단한 함수의 합으로 분해될 수 있는 함수를 계산하는 것이 더 쉽습니다. 따라서, 머신러닝에서는 보통 negative log-likelihood를 사용합니다.
\[\mathcal{L}(\boldsymbol{\theta}) = -\log p(\mathcal{Y}|\mathcal{X},\boldsymbol{\theta}) = -\sum_{n=1}^N \log p(y_n|\boldsymbol{x}_n,\boldsymbol{\theta}) \tag{8.17}\]식 (8.15)에서 $\boldsymbol{\theta}$ 가 $p(y_n|\boldsymbol{x}_n,\boldsymbol{\theta})$ 에서 조건 오른쪽에 있다는 사실로 인해 관측되고 고정된 것으로 해석되어야 하지만, 이 해석은 잘못되었습니다. Negetive log-likelihood $\mathcal{L}(\boldsymbol{\theta})$ 는 $\boldsymbol{\theta}$ 에 대한 함수입니다. 그러므로, data $(\boldsymbol{x}_1,y_1),\dotsc,(\boldsymbol{x}_n,y_n)$ 을 잘 설명하는 good parameter vector $\boldsymbol{\theta}$ 를 찾으려면 $\boldsymbol{\theta}$ 에 대한 negative log-likelihood $\mathcal{L}(\boldsymbol{\theta})$ 를 최소화합니다.
Example 8.5
Gaussian likelihood (8.15)의 예제를 이어서 살펴보겠습니다. Negative log-likelihood는 아래와 같이 다시 작성됩니다.
\[\begin{align*} \mathcal{L}(\boldsymbol{\theta}) &= -\sum_{n=1}^N \log p(y_n|\boldsymbol{x}_n,\boldsymbol{\theta}) = -\sum_{n=1}^N \log\mathcal{N}(y_n|\boldsymbol{x}_n^\top\boldsymbol{\theta}, \sigma^2) \tag{8.18a} \\ &= -\sum_{n=1}^N \log\frac{1}{\sqrt{2\pi\sigma^2}}\exp\left(-\frac{(y_n-\boldsymbol{x}_n^\top\boldsymbol{\theta})^2}{2\sigma^2}\right) \tag{8.18b} \\ &= -\sum_{n=1}^N \log\exp\left(-\frac{(y_n-\boldsymbol{x}_n^\top\boldsymbol{\theta})^2}{2\sigma^2}\right) - \sum_{n=1}^N\log\frac{1}{\sqrt{2\pi\sigma^2}} \tag{8.18c} \\ &= \frac{1}{2\sigma^2}\sum_{n=1}^N(y_n-\boldsymbol{x}_n^\top\boldsymbol{\theta})^2 - \sum_{n=1}^N\log\frac{1}{\sqrt{2\pi\sigma^2}} \tag{8.18d} \end{align*}\]$\sigma$ 가 주어지면, (8.18c)의 두 번째 항은 상수이므로, $\mathcal{L}(\boldsymbol{\theta})$ 를 최소화하는 것은 least-squares problem(첫 번째 항)을 푸는 것과 같습니다 (식 (8.8)과 비교).
Gaussian likelihood의 경우, maximum likelihood estimation에 해당하는 최적화 문제는 closed-form solution을 가집니다. 이에 대해서는 9장에서 더 자세히 살펴보겠습니다. Figure 8.5는 regression dataset과 MLE에 의해 유도된 함수를 보여줍니다.
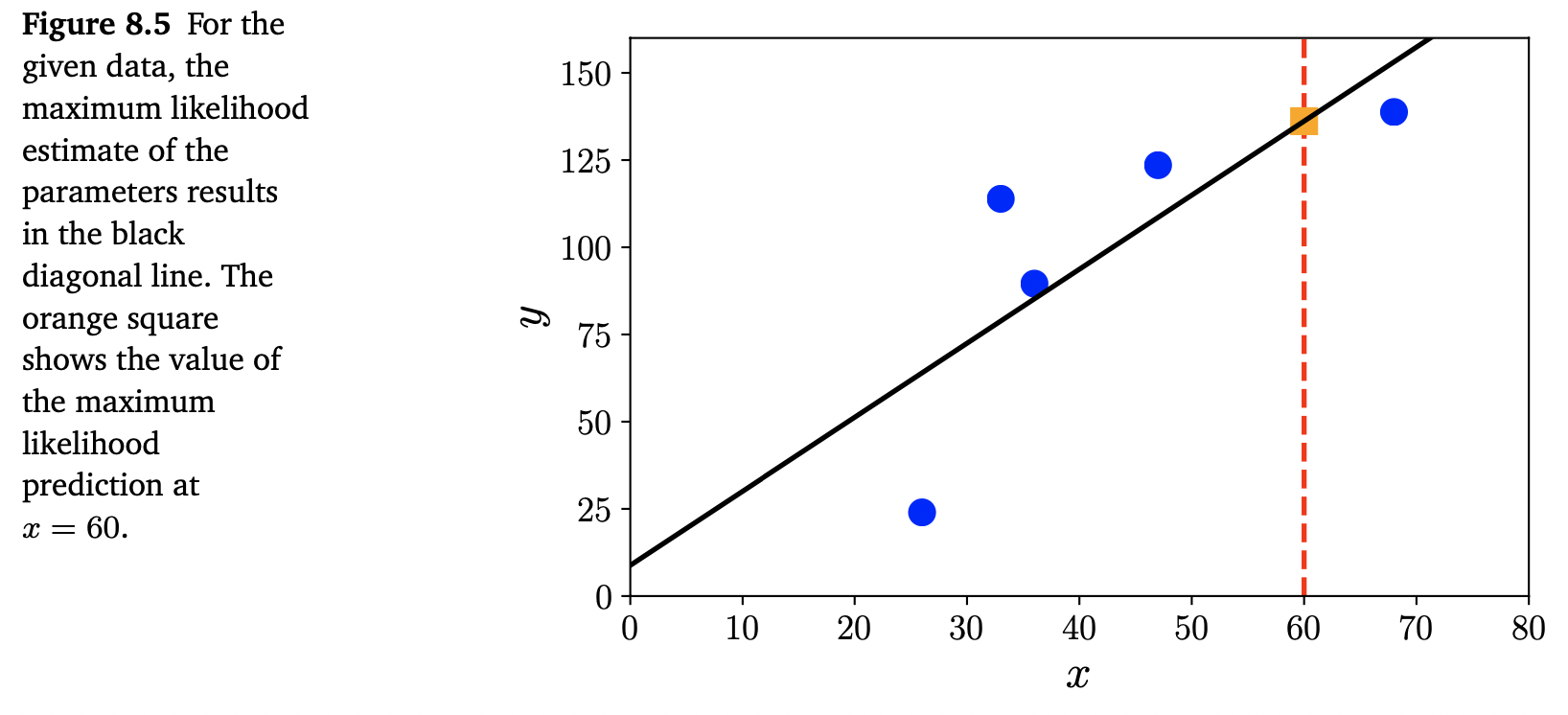
MLE는 비정규화된(unregularized) empirical risk minimization과 유사하게 overfitting(8.3.3장 참조)을 겪을 수 있습니다. 다른 likelihood function, 즉, 만약 non-Gaussian distributions로 noise를 모델링하는 경우, MLE에는 closed-form analytic solution이 없을 수도 있습니다. 이러한 경우에는 7장에서 논의했던 numerical optimization methods를 통해 해를 구합니다.
Maximum A Posteriori Estimation
만약 파라미터 $\boldsymbol{\theta}$ 의 분포에 대해 사전 지식(prior knowledge)이 있다면, likelihood 에 추가 항을 곱할 수 있습니다. 이 추가 항은 파라미터 $p(\boldsymbol{\theta})$ 에 대한 사전 확률 분포(prior probability distribution) 입니다. 주어진 prior에 대해, 어떤 데이터 $\boldsymbol{x}$ 를 관측한 이후에는 어떻게 $\boldsymbol{\theta}$ 의 분포를 업데이트할 수 있을까요? 다시 말하자면, 데이터 $\boldsymbol{x}$ 를 관측한 후 $\boldsymbol{\theta}$ 에 대해 더 구체적인 지식을 가지고 있다는 사실을 어떻게 표현할 수 있을까요? 6.3장에서 논의한 Bayes’ theorem은 확률 변수의 확률 분포를 업데이트하기 위한 principled tool을 제공합니다. 이를 통해 일반적인 사전 진술(prior statements) $p(\boldsymbol{\theta})$ 및 매개변수 $\boldsymbol{\theta}$ 와 관측된 데이터 $\boldsymbol{x}$ 연결해야 하는 함수 $p(\boldsymbol{x}|\boldsymbol{\theta})$ (called the likelihood) 로부터 파라미터 $\boldsymbol{\theta}$ 에 대한 사후 확률(posterior distribution) $p(\boldsymbol{\theta}|\boldsymbol{x})$ (the more specific knowledge) 를 계산할 수 있습니다.
\[p(\boldsymbol{\theta}|\boldsymbol{x}) = \frac{p(\boldsymbol{x}|\boldsymbol{\theta})p(\boldsymbol{\theta})}{p(\boldsymbol{x})} \tag{8.19}\]우리는 Posterior를 최대화하는 파라미터 $\boldsymbol{\theta}$ 를 찾는 데 관심이 있습니다. 분포 $p(\boldsymbol{x})$ 는 $\boldsymbol{\theta}$ 에 대해 의존하지 않기 때문에, 최적화를 위해 위 식 (8.19)에서 분모의 값을 무시하여 아래의 식을 얻을 수 있습니다.
\[p(\boldsymbol{\theta}|\boldsymbol{x}) \propto p(\boldsymbol{x}|\boldsymbol{\theta})p(\boldsymbol{\theta}) \tag{8.20}\]위 식의 비율 관계는 추정하기 어려운 데이터의 밀도 $p(\boldsymbol{x})$ 를 숨깁니다. Negative log-likelihood의 최솟값을 추정하는 대신, 이제 최대 사후 추정 maximum a posterior estimation (MAP estimation) 이라 칭하는 negative log-posterior의 최솟값을 추정합니다. Zero-mean Gaussian prior 를 추가하는 효과를 아래 Figure 8.6에서 보여주고 있습니다.
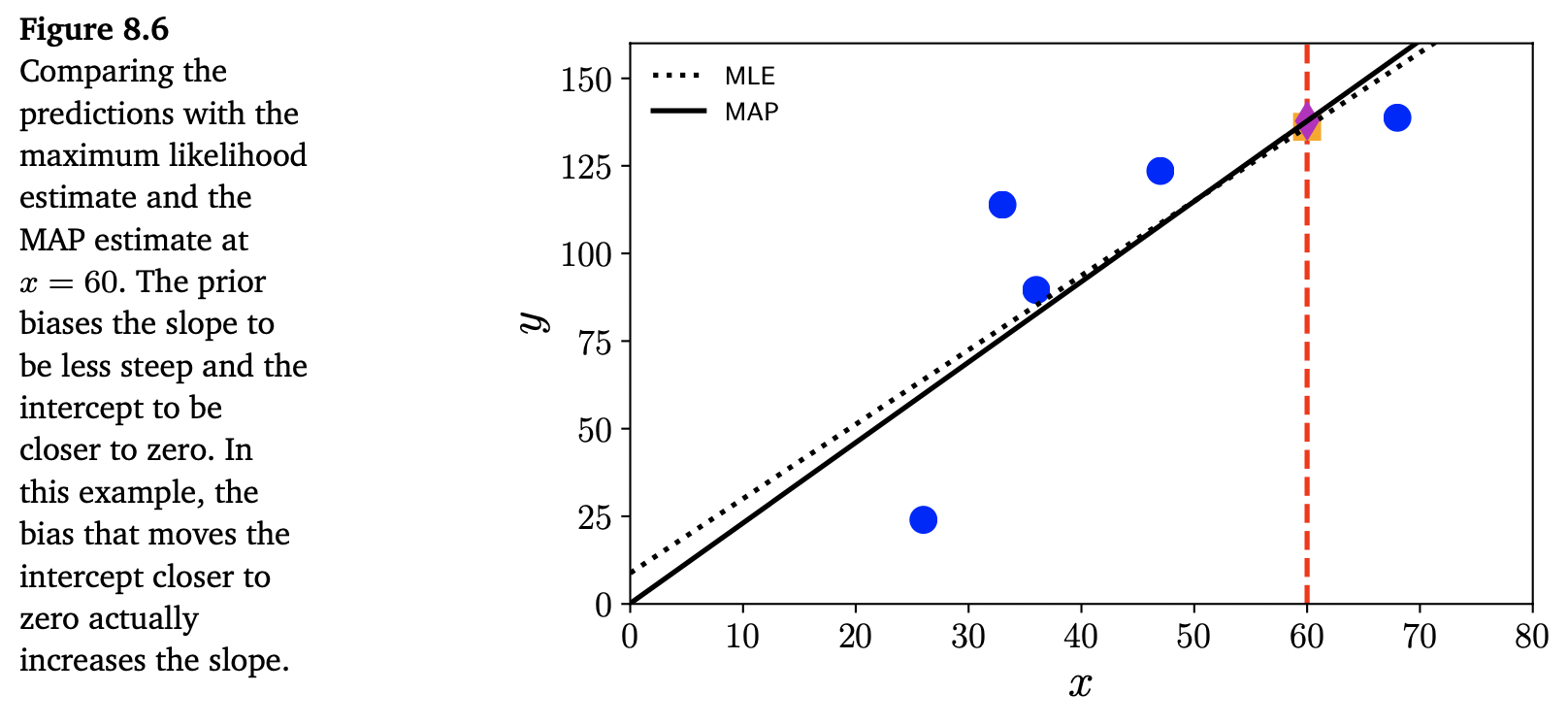
Example 8.6
이전 예제 Example 8.5에서의 Gaussian likelihood의 가정 외, 파라미터 벡터가 평균이 0인 다변량 가우시안(multivariate Gaussian)으로 분포되어 있다고 가정해보겠습니다. 즉, $p(\boldsymbol{\theta}) = \mathcal{N}(\boldsymbol{0},\boldsymbol{\Sigma})$ , 여기서 $\boldsymbol{\Sigma}$ 는 공분산 행렬(covariance matrix) 입니다. Gaussian의 conjugate prior 또한 Gaussian 이므로 우리는 posterior distribution 또한 Gaussian 이라는 것을 알 수 있습니다. MAP(maximum a posteriori) estimation은 9장에서 더 자세히 살펴볼 예정입니다.
Good parameter가 어디에 놓여있는 지에 대한 사전 지식을 포함하는 idea는 머신러닝에 널리 퍼져 있습니다. 8.2.3장 본 대안적 관점은 regularization의 idea인데, 이는 결과로 나오는 파라미터를 origin에 가깝게 편향시키는 추가 항을 도입합니다. MAP는 사전 확률의 필요성을 명시적으로 인정하지만, 여전히 파라미터의 point estimate만 생성하므로, non-probabilistic과 probabilistic worlds의 다리를 놓는 것이라고 간주할 수 있습니다.
- Asymptotic consistency: MLE는 무한히 많은 관측치의 극한에서의 true value로 수렴하고, 여기에 대략적으로 normal인 random error가 더해집니다.
- 이러한 속성들을 달성하는 데 필요한 sample의 크기는 상당히 클 수 있습니다.
- Error의 분산은 $1/N$ 으로 감소하는데, 여기서 $N$ 은 data point의 수 입니다.
- 특히, 작은 데이터 영역에서 MLE는 과적합(overfitting)으로 이어질 수 있습니다.
MLE (and MAP)의 원리는 데이터와 모델의 파라미터의 불확실성에 대해 추론하기 위해 probabilistic modeling을 사용합니다. 그러나, 아직 probabilistic modeling을 완전히 사용하지 않았습니다. 이번 섹션에서 training procedure 결과는 여전히 predictor의 point estimate를 생성합니다. 즉, 학습은 best predictor를 표현하는 하나의 파라미터 값들의 집합을 반환합니다. 8.4장에서는 매개변수의 값 또한 확률 변수로 취급되어야 한다는 관점을 가지고 해당 분포의 “best” value를 추정하는 대신 예측할 때 전체 파라미터 분포를 사용하도록 할 것입니다.
Model Fitting
“Fitting”에 대해 이야기할 때, 일반적으로 모델의 매개변수를 최적화 및 학습하여 어떤 loss function(e.g., negative log-likelihood)을 최소화하는 것을 의미합니다. Maximum likelihood(ML)와 maximum a posterior(MAP) 추정에서 우리는 이미 model fitting에 일반적으로 사용되는 두 가지 알고리즘을 살펴봤습니다.
모델의 매개변수화(parameterization of the model)는 우리가 동작시킬 수 있는 model class $M_{\theta}$ 를 정의합니다. 예를 들어, linear regression에서 우리는 inputs $x$ 와 (noise-free) observations $y$ 사이의 관계를 $y=ax+b$ 로 정의할 수 있습니다. 이때 $\boldsymbol{\theta} := {a,b}$ 가 모델의 파라미터입니다. 이 경우 모델의 파라미터 $\boldsymbol{\theta}$ 는 affine function 계열이라는 것을 설명하는데, 즉, 기울기가 a이면서 0으로부터 b만큼 떨어진 직선입니다.
데이터가 우리가 모르는 모델 $M^*$ 으로부터 왔다고 가정해봅시다. 주어진 training dataset에서 우리는 $M_\theta$ 가 최대한 $M^*$ 에 가깝도록 $\boldsymbol{\theta}$ 를 최적화합니다. 여기서 가깝다(closeness)라는 뜻은 우리가 최적화할 목적 함수 (e.g., squared loss on the training data)에 의해 정의됩니다. 아래 그림 Figure 8.7은 작은 모델 클래스 (원으로 나타나는 $M_\theta$)과 데이터 생성 모델 $M^*$ 이 고려된 모델 집합의 외부에 놓여 있다는 것을 보여줍니다.
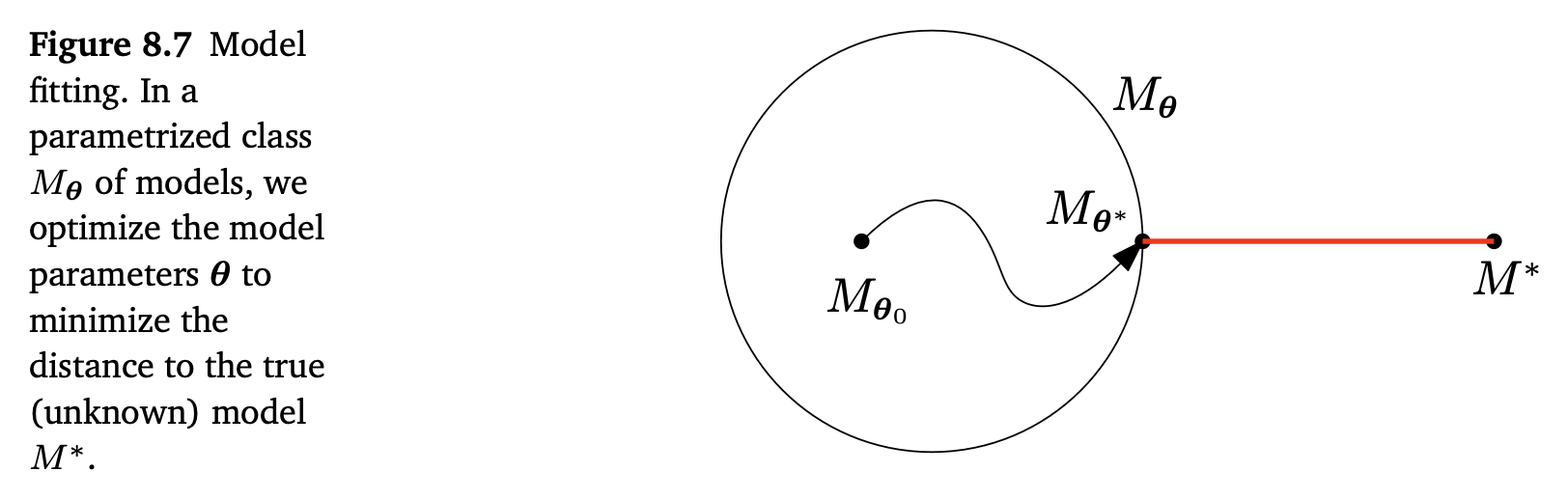
우리는 $M_\theta$ 에서부터 파라미터 탐색을 시작합니다. 최적화 이후, 즉, 우리가 가능한 best인 파라미터 $\boldsymbol{\theta}^*$ 를 찾았을 때, 우리는 3가지 다른 케이스들을 고려해야 합니다.
- overfitting (과적합)
- underfitting (과소적합)
- fitting well
간단히 말하면, overfitting 은 매개변수화된 모델 클래스가 $M^*$ 에 의해 생성된 dataset을 모델링하기에 너무 과한 상황을 나타냅니다. 즉, $M_\theta$ 는 더 복잡한 datasets을 모델링할 수 있습니다. 예를 들어, 만약 datset이 linear function에 의해 생성되었고 $M_\theta$ 를 7차 다항식의 클래스로 정의했다면, linear function뿐만 아니라 2,3차 다항식까지 모델링할 수 있습니다. 과적합된 모델은 일반적으로 파라미터의 수가 많습니다. 종종 지나치게 유연한 모델 클래스 $M_\theta$ 가 traning error를 줄이기 위해서 모든 modeling power를 사용한다는 것을 발견하게 됩니다. 만약 training data에 노이즈가 있는 경우, 노이즈 자체에서 유용한 signal을 찾아내려고 합니다. 이는 training data로 학습할 때 큰 문제를 일으킵니다.
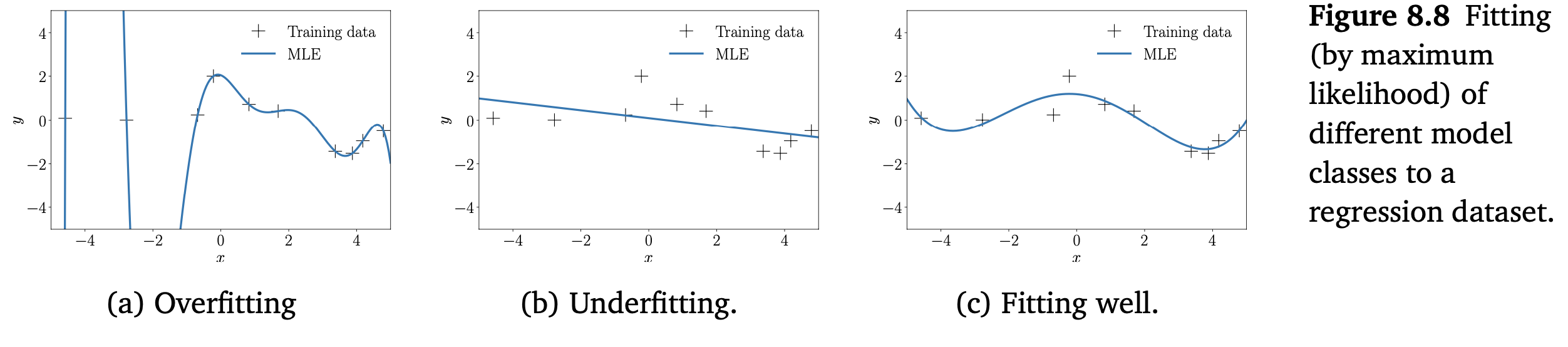
위 그림 Figure 8.8(a)는 regression(maximum likelihood를 통해 학습된 파라미터)에서의 과적합 예를 보여줍니다.
이와 반대의 문제인 underfitting 은 model class $M_\theta$ 가 rich하지 않는 경우입니다. 예를 들어, dataset이 sin 함수에 의해 생성되었지만, $\boldsymbol{\theta}$ 가 오직 직선으로 파라미터화되었다면, best optimization procedure은 true model에 근접하지 못합니다. 그러나 dataset을 모델링하는 최적의 직선을 찾으려고 파라미터를 최적화합니다. Figure 8.8(b)는 충분히 유연하지 못하여서 발생하는 과적합 모델의 예시를 보여줍니다. 이러한 모델은 일반적으로 적은 수의 파라미터를 갖습니다.
세 번째 케이스는 매개변수화된 model class가 적절한 상황입니다. 즉, overfitting도 아니고 underfitting도 아닙니다. 이는 주어진 dataset만을 표현할 만큼만 충분하다는 것을 의미합니다. Figure 8.8(c)에서 이러한 예를 잘 보여주고 있습니다. 이상적으로 일반화를 잘 하므로, 우리가 찾고자하는 모델입니다.
실제로는 보통 deep neural networks와 같이 많은 파라미터를 가진 매우 rich한 model class $M_\theta$ 를 정의합니다. 과적합 문제를 완화하기 위해서는 정규화(regularization) 또는 priors를 사용할 수 있습니다. Model class를 선택하는 방법에 대해서는 8.6장에서 살펴보도록 하겠습니다.