Discrete and Continuous Probabilities
Target space가 discrete인지 continuous인지에 따라, 분포를 참조하는 방법이 다릅니다. Target space $\mathcal{T}$ 가 discrete 할 때, 확률 변수 $X$ 는 특정 값 $x\in\mathcal{T}$ 를 취할 확률을 지정할 수 있으며, 이는 $P(X=x)$ 로 표기합니다. 이산 확률 변수(discrete random variable) $X$ 에 대한 표현 $P(X=x)$ 는 probability mass function(질량 밀도 함수)이라고 합니다.
Target space $\mathcal{T}$ 이 continous 하다면, 즉, $\mathcal{T}$ 가 real line $\mathcal{R}$ 일 때, 확률 변수 $X$ 에 대한 확률을 $P(a\leq X\leq b)$ ($a<b$) 와 같이 구간으로 표현하는 자연스럽습니다. 관습적으로 확률 변수 $X$ 가 특정 값 $x$ 보다 작을 확률로 지정하며, $P(X\leq x)$ 로 표기합니다. 연속 확률 변수(continuous random variable) $X$ 에 대한 표현 $P(X\leq x)$ 는 cumulative distribution function(누적 분포 함수) 라고 합니다.
Discrete Probabilities
Target space가 discrete할 때, 여러 확률 변수들의 확률 분포를 아래 그림과 같이 숫자들의 다차원 배열을 채우는 것으로 생각할 수 있습니다.
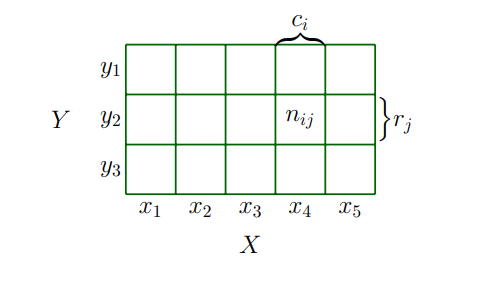
Target space의 joint probability(결합 확률)은 각 확률 변수의 target space의 cartesian product 입니다. Joint probability 는 다음과 같이 두 값을 함께 입력하는 것으로 정의합니다.
\[P(X=x_i, Y=y_j) = \frac{n_{ij}}{N} \tag{6.9}\]여기서 $n_{ij}$ 는 state가 $x_i, y_j$ 인 사건의 수이며, $N$ 은 모든 사건들의 수 입니다. Joint probability는 두 사건의 교집합에 대한 확률이며, 다음과 같습니다.
\[P(X=x_i, Y=y_j) = P(X = x_i \cap Y=y_j)\]Figure 6.2는 이산 확률 분포의 probability mass function (pmf)에 대해 설명해줍니다. 두 확률 변수 $X, Y$ 에 대해, $X=x, Y=y$ 인 확률은 $p(x, y)$ 라고 표기하며, 이는 joint probability(결합 확률)이라고 부릅니다. $p(x, y)$ 는 state $x$ 와 $y$ 를 받아서 real number를 리턴하는 함수로 생각할 수 있습니다.
확률 변수 $Y$ 에 관계없이 $X$ 가 값 $x$ 를 취하는 marginal probability 를 $p(x)$ 로 표기합니다. 확률 변수 $X$ 가 $p(x)$ 에 따라 분포한다는 것을 나타내기 위해서 $X \sim p(x)$ 으로 표기합니다.
$X = x_0$ 일 때, $Y=y$ 인 경우의 확률을 conditional probability(조건부 확률) 라고 하며 $p(y|x_0)$ 로 표기합니다.
Example 6.2
위 그림과 같이 $X$ 가 5개의 가능한 states를 가지고 $Y$ 는 3개의 가능한 states를 가지는 두 확률 변수 $X, Y$ 에 대해 고려해보겠습니다. $n_{ij}$ 는 state $X=x_i$ 와 state $Y=y_j$ 의 사건의 수 이고, $N$ 은 모든 사건의 수 입니다.
$c_i$ 값은 i번째 column의 각 빈도수들의 합이며, $c_i = \sum_{j=1}^3 n_{ij}$ 입니다. 비슷하게 $r_j$ 는 row sum이며, $r_j = \sum_{i=1}^5 n_{ij}$ 입니다.
이렇게 정의한 것들을 사용하여, $X$ 와 $Y$ 의 분포를 간결하게 표현할 수 있습니다.
각 확률 변수의 확률 분포, 즉, marginal probability는 아래와 같이 row 또는 column의 합으로 표현할 수 있습니다.
\[\begin{align*} P(X=x_i) &= \frac{c_i}{N} = \frac{\sum_{j=1}^3 n_{ij}}{N} \tag{6.10} \\ P(Y=y_j) &= \frac{r_j}{N} = \frac{\sum_{i=1}^5 n_{ij}}{N} \tag{6.11} \end{align*}\]위 식에서 $c_i$ 와 $r_j$ 는 각각 probability table의 i번째 column과 j번째 row 입니다. 관례로, 유한한 수의 사건이 있는 이산 확률 변수에 대해서 확률의 합이 1이라고 가정합니다. 즉, 다음과 같습니다.
\[\sum_{i=1}^5 P(X=x_i) = 1 \quad \text{and} \quad \sum_{j=1}^3 P(Y=y_j) = 1 \tag{6.12}\]Conditional probability는 특정 cell에 있는 row 또는 column의 비율입니다. 예를 들어, $X$ 가 주어졌을 때(given $X$), $Y$ 의 conditional probability는
\[P(Y=y_j|X=x_i) = \frac{n_{ij}}{c_i} \tag{6.13}\]이고, $Y$ 가 주어졌을 때(given $Y$), $X$ 의 conditional probability는 아래와 같습니다.
\[P(X=x_i|Y=y_j) = \frac{n_{ij}}{r_j} \tag{6.14}\]
머신러닝에서는 이산 확률 분포를 사용하여 categorical variable, 즉, unordered values의 유한한 집합을 취하는 변수를 모델링합니다. 급여를 예측하기 위해 대학에서 취득한 학위와 같이 categorical features나 필기체 인식을 위한 알파벳 문자와 같은 categorical labels이 categorical variable에 해당합니다.
이산 분포는 유한한 수의 연속 분포를 결합하는 확률 모델을 구성할 때도 종종 사용됩니다 (11장 참조).
Continuous Probabilities
이번에는 real-valued random variables에 대해 살펴보겠습니다. 즉, real line $\mathcal{R}$ 의 구간으로 표현되는 target spaces에 대해 고려합니다.
이 책에서는 real random variables에 대해 유한한 states를 가진 discrete probability spcaes인 것처럼 연산을 수행할 수 있다고 가정합니다. 하지만, 이러한 단순화는 두 가지 상황에서 정확하지 않습니다.
첫 번째 상황은 머신러닝에서 generalization errors에 논의할 때이고(8장 참조), 두 번째 상황은 Gaussian(6.5장)과 같은 continuous distribution에 대해 논의할 때 입니다.
Remark. Continuous spaces에서는 직관적이지 않은 두 가지의 추가적인 technicalities가 있습니다. 첫째, 모든 subsets의 집합(6.1장에서 event space $\mathcal{A}$ 를 정의할 때 사용)이 충분히 제대로 동작하지 않는다는 점입니다. 여집합(complements), 교집합(intersections), 합집합(unions)에서 잘 동작하려면 $\mathcal{A}$ 는 잘 동작해야 합니다. 둘째, 집합의 크기(discrete spaces에서는 카운팅하여 얻을 수 있음)를 알아내기가 까다롭습니다. 집합의 크기는 measure 이라고 부릅니다. 예를 들어, discrete set의 cardinality, $\mathbb{R}$ 에서 interval의 길이, $\mathbb{R}^d$ 에서 영역의 부피는 모두 measures 입니다. 집합 연산이 잘 동작하고, 추가로 topology를 가진 집합을 Borel $\sigma$ -algebra 라고 부릅니다.
이와 관련하여 조금 더 자세한 내용은 link를 참조하시길 바랍니다.
이 책에서는 real-valued random variables에 대응되는 Borel $\sigma$-algebra 와 함께 real-valued random variables를 고려합니다.
Definition 6.1 (Probability Density Function)
아래의 두 조건을 만족하는 함수 $f : \mathbb{R}^D \rightarrow \mathbb{R}$ 를 probability density function (pdf) 이라고 부릅니다.
\[\int_{\mathbb{R}^D} f(\boldsymbol{x})\mathrm{d}\boldsymbol{x}= 1 \tag{6.15}\]
- $\forall\boldsymbol{x}\in\mathbb{R}^D : f(\boldsymbol{x}) \geq 0$
- 적분이 존재하고 다음을 만족함
이산 확률 변수의 probability mass functions(pmf)는 (6.12)와 같이 (6.15)에서 integral이 sum으로만 바뀌면 됩니다.
Non-negative이면서 적분 결과가 1인 모든 함수 $f$ 는 pdf로 볼 수 있습니다. 이러한 함수 $f$ 를 확률 변수 $X$ 를 다음과 같이 연관시킬 수 있습니다.
\[P(a\leq X\leq b) = \int_a^b f(x)\mathrm{d}x \tag{6.16}\]위 식에서 $a, b\in\mathbb{R}$ 이고, $x\in\mathbb{R}$ 은 연속 확률 변수 $X$ 의 결과(outcomes) 입니다. State $\boldsymbol{x}\in\mathbb{R}^D$ 는 벡터 $x\in\mathbb{R}$ 을 고려하여 유사하게 정의됩니다. (6.16)은 law or distribution of the random variable $X$ 라고 부릅니다.
Definition 6.2 (Cumulative Distribution Function)
Multivariate real-valued random variable $X$ (with states $\boldsymbol{x}\in\mathbb{R}^D$) 의 cumulative distribution function (cdf) 는 다음과 같이 정의됩니다.
\[P_X(\boldsymbol{x}) = P(X_1\leq x_1, \dotsc, X_D\leq x_D) \tag{6.17}\]이때, $X = \lbrack X_1,\dotsc,X_D\rbrack^\top$ , $\boldsymbol{x} = \lbrack x_1,\dotsc,x_D\rbrack^\top$ 이며, (6.17)의 우항은 $x_i$ 보다 작거나 같은 값들을 취하는 확률 변수 $X_i$ 의 확률을 나타냅니다.
CDF 는 확률 밀도 함수(probability density function) $f(\boldsymbol{x})$ 의 적분으로도 표현할 수 있습니다.
\[F_X(\boldsymbol{x}) = \int_{-\infty}^{x_1}\cdots\int_{-\infty}^{x_D} f(z_1,\dotsc,z_D)\mathrm{d}z_1\cdots\mathrm{d}z_D \tag{6.18}\]이 책의 대부분에서 pdf와 cdf를 구분할 필요가 없기 때문에 $f(x)$ 와 $F_X(x)$ 표기법을 사용하지는 않습니다. 하지만, 6.7장에서는 pdf와 cdf에 대해 주의를 기울여야 합니다.
Contrasting Discrete and Continuous Distributions
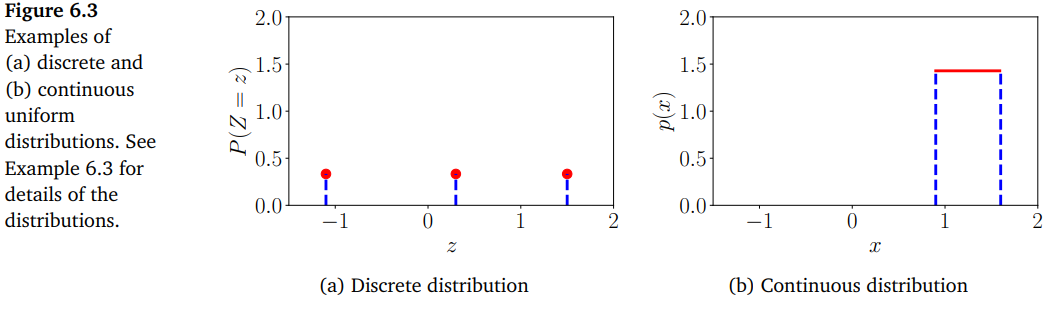
6.1.2장에서 확률은 양수이며 전체 확률의 합은 1이라고 했습니다. 이산 확률 변수(discrete random variables)에서, 이는 각 state의 확률 값이 반드시 [0, 1] 사이에 놓여있다는 것을 의미합니다. 그러나 연속 확률 변수(continuous random variables) normalization((6.15) 참고)는 밀도(density)의 값이 모든 값에 대해 1과 같거나 작다는 것을 의미하지 않습니다. 아래 그림 Figure 6.3은 uniform distribution 을 사용하여 이를 보여줍니다.
Example 6.3
이번 예제를 통해 uniform distribution의 두 가지 예제에 대해 살펴보겠습니다. Uniform distribution에서는 각 state가 발생할 가능성이 모두 동일합니다. 이 예제에서는 discrete와 continuous 분포가 어떻게 다른지 보여줍니다.
$Z$ 가 3가지의 state $\lbrace z=-1.1, z=0.3, z=1.5\rbrace$ 를 가지는 discrete uniform random variable이라고 한다면, probability mass function(PMF)는 다음과 같이 확률 값들의 표로 나타낼 수 있습니다.
또는, Figure 6.3의 (a)와 같이 그래프로 생각할 수도 있습니다. 이 그래프에서 x축은 각 state를 나타내며, y축은 특정 state의 확률을 나타냅니다.
이번에는 $X$ 를 continuous random variable 이고, Figure 6.3의 (b)와 같이 확률 변수 값의 범위가 $0.9\leq X\leq 1.6$ 이라고 가정해봅시다. 그래프에서 Density의 높이가 1보다 크다는 것을 볼 수 있습니다. 하지만, 이는 다음의 식을 만족시킵니다.
\[\int_{0.9}^{1.6}p(x)\mathrm{d}x = 1 \tag{6.19}\]

머신러닝 문헌에서는 일반적으로 sample space $\Omega$ , target space $\mathcal{T}$ 및 확률 변수 $X$ 를 구분하지 않는 notation(표기법)과 nomenclature(명명법)을 사용합니다. 보통 확률 변수 $X$ 의 가능한 결과(outcomes)들의 집합에서의 값 $x$ 에 대해, $x\in\mathcal{T}, p(x)$ 는 확률 변수 $X$ 가 $x$ 일 확률을 나타냅니다. 이산 확률 변수인 경우에는 $P(X = x)$ 라고 쓰며, 이는 probability mass function(PMF) 입니다. PMF는 보통 “distribution” 이라고 칭합니다.
연속 확률 변수의 경우에는 $p(x)$ 를 probability density function (보통 density, 밀도라고 칭합니다) 라고 부릅니다. 더 나아가, cumulative distribution function(누적 분포 함수) $P(X\leq x)$ 또한 “distribution” 이라고 칭합니다.
6장에서는 $X$ 라는 표기법을 사용하여 두 univariate/multivariate 확률 변수를 표현하며, univariate와 multivariate는 각각 $x$ 와 $\boldsymbol{x}$ 로 나타냅니다. 두 확률 변수에 대한 명명법은 다음과 같습니다.
| Type | “Point probability” | “Interval probability” |
|---|---|---|
| Discrete | $P(X=x)$ Probability mass function |
Not applicable |
| Continuous | $p(x)$ Probability density function |
$P(X\leq x)$ Cumulative distribution function |