Gaussian Distribution
가우시안 분포(gaussian distribution)는 continuous-valued random variables에 대해 가장 연구가 잘 되어 있는 확률 분포입니다. 이 분포는 정규 분포(normal distribution)이라고도 불립니다. 가우시안 분포는 계산상 편리한 속성들이 많다는 사실 때문에 중요하며, 이는 차차 알아가보도록 하겠습니다. 가우시안 분포는 linear regression(Ch9)에 대한 likelihood와 prior를 정의하거나 density estimation(Ch11)의 a mixture of Gaussian을 고려할 때 사용됩니다.
가우시안 분포를 사용하여 이점을 얻을 수 있는 머신러닝의 분야는 많습니다. 예를 들어, Gaussian processes, variational inference, reinforcement learning이 있습니다. 또한, signal processing(e.g., Kalman filter), control(e.g., linear quadratic regulator), statistics(e.g., hypothesis testing)과 같은 어플리케이션에서도 널리 사용됩니다.
Univariate random variable의 경우, 가우시안 분포의 density는 다음과 같이 주어집니다.
\[p(x|\mu,\sigma^2) = \frac{1}{\sqrt{2\pi\sigma^2}}\exp\left(-\frac{(x-\mu)^2}{2\sigma^2}\right) \tag{6.62}\]Multivariate Gaussian Distribution 은 mean vector $\boldsymbol{\mu}$ 와 covariance matrix $\boldsymbol{\Sigma}$ 를 사용하여 다음과 같이 정의됩니다 ($\boldsymbol{x}\in\mathbb{R}^D$).
\[p(\boldsymbol{x}|\boldsymbol{\mu},\boldsymbol{\Sigma}) = (2\pi)^{-\frac{D}{2}}|\boldsymbol{\Sigma}|^{-\frac{1}{2}}\exp\left(-\frac{1}{2}(\boldsymbol{x}-\boldsymbol{\mu})^\top\boldsymbol{\Sigma}^{-1}(\boldsymbol{x}-\boldsymbol{\mu})\right) \tag{6.63}\]가우시안 분포는 $p(\boldsymbol{x}) = \mathcal{N}(\boldsymbol{x}|\boldsymbol{\mu},\boldsymbol{\Sigma})$ 또는 $X\sim\mathcal{N}(\boldsymbol{\mu},\boldsymbol{\Sigma})$ 로 표기합니다.
아래 그림은 bivariate Gaussian에 대한 그래프이며, 대응되는 contour plot을 보여줍니다.
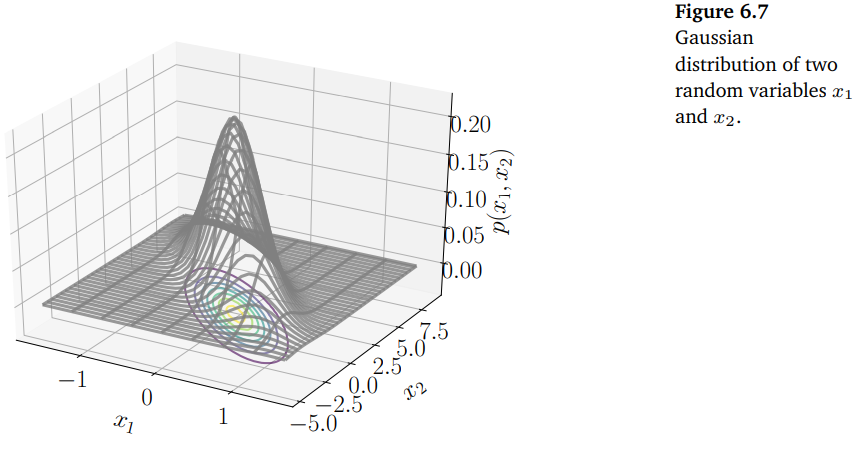
아래 그림은 univariate Gaussian과 bivariate Gaussian을 보여줍니다.
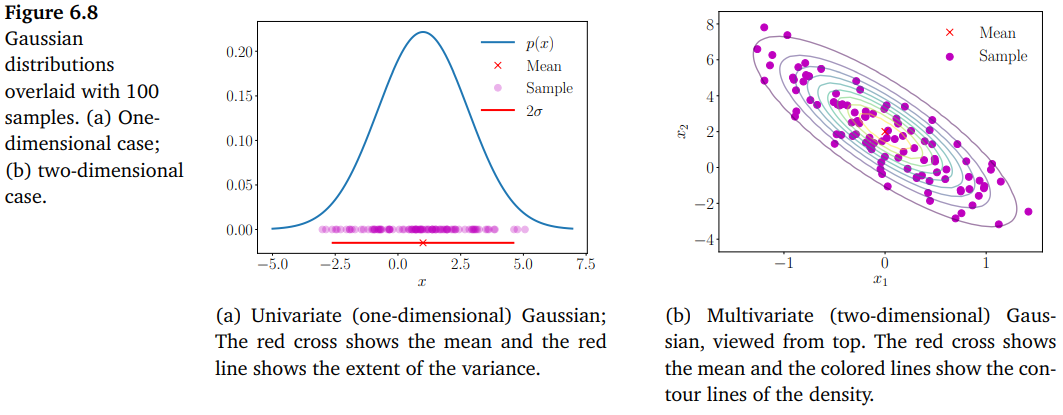
평균이 0이고 분산이 1인 가우시안 분포, 즉, $\boldsymbol{\mu} = \boldsymbol{0}$ 그리고 $\boldsymbol{\Sigma} = \boldsymbol{I}$ 인 가우시안 분포는 special case이며 표준 정규 분포(standard normal distribution)이라고 부릅니다.
가우시안은 marginal/conditional 분포에 대해 closed-form의 표현식을 갖기 때문에 통계적 추정(statistical estimation)과 머신러닝에서 널리 사용됩니다. 9장에서는 linear regression에서 이러한 closed-form expressions를 사용합니다.
가우시안 확률 변수를 사용하여 모델링할 때 얻을 수 있는 주요한 이점은 variable transformation(6.7장)이 종종 필요하지 않다는 점입니다. 가우스 분포는 평균과 공분산만으로 결정되기 때문에 확률 변수의 평균과 공분산에 대해 변환을 적용하면 변환된 분포를 쉽게 얻을 수 있습니다.
Marginals and Conditionals of Gaussians are Gaussians
이어서 일반적인 multivariate random variables에서 marginalization과 conditioning을 표현해보도록 하겠습니다. 만약 조금 복잡하게 느껴진다면, 우선 2개의 univariate random variables로 고려해보는 것이 도움이 됩니다. $X$ 와 $Y$, 2개의 multivariate random variables가 있다고 한다면, 이들은 서로 차원이 다를 수 있습니다. 확률의 sum rule과 conditioning을 적용하기 위해서 명시적으로 가우시안 분포를 아래와 같이 concatenated states $[\boldsymbol{x}^\top, \boldsymbol{y}^\top]$ 의 항으로 표현하겠습니다.
\[p(\boldsymbol{x},\boldsymbol{y}) = \mathcal{N}\left(\begin{bmatrix} \boldsymbol{\mu}_x \\ \boldsymbol{\mu}_y \end{bmatrix}, \begin{bmatrix} \boldsymbol{\Sigma}_{xx} & \boldsymbol{\Sigma}_{xy} \\ \boldsymbol{\Sigma}_{yx} & \boldsymbol{\Sigma}_{yy} \end{bmatrix}\right) \tag{6.64}\]여기서 $\boldsymbol{\Sigma}_{xx} = \text{Cov}[\boldsymbol{x},\boldsymbol{x}]$ , $\boldsymbol{\Sigma}_{yy} = \text{Cov}[\boldsymbol{y},\boldsymbol{y}]$ 는 각각 $\boldsymbol{x}, \boldsymbol{y}$ 의 marginal covariance matrix 이며, $\boldsymbol{\Sigma}_{xy} = \text{Cov}[\boldsymbol{x},\boldsymbol{y}]$ 는 $\boldsymbol{x}$ 와 $\boldsymbol{y}$ 사이의 cross-covariance matrix 입니다.
조건부 분포 $p(\boldsymbol{x}|\boldsymbol{y})$ 또한 가우시안(아래의 Figure 6.9(c) 참조)이며, 다음과 같습니다.
\[\begin{align*} p(\boldsymbol{x}|\boldsymbol{y}) &= \mathcal{N}(\boldsymbol{\mu_{x|y}}, \boldsymbol{\Sigma}_{x|y}) \tag{6.65} \\ \boldsymbol{\mu}_{x|y} &= \boldsymbol{\mu}_x + \boldsymbol{\Sigma}_{xy}\boldsymbol{\Sigma}_{yy}^{-1}(\boldsymbol{y}-\boldsymbol{\mu}_y) \tag{6.66} \\ \boldsymbol{\Sigma}_{x|y} &= \boldsymbol{\Sigma}_{xx} - \boldsymbol{\Sigma}_{xy}\boldsymbol{\Sigma}_{yy}^{-1}\boldsymbol{\Sigma}_{yx} \tag{6.67} \end{align*}\](6.66)의 평균 계산에서, $\boldsymbol{y}$ 의 값은 관측된 값(observation)이며, 더 이상 랜덤한 값이 아니라는 것에 주의합니다.
- The Kalman filter : 신호처리에서 state estimation을 위한 핵심 알고리즘 중 하나이며, joint distribution의 Gaussian conditionals 만을 계산합니다.
- Gaussian processes : 가우시안 프로세스는 함수에 대한 분포를 실제적으로 구현한 것입니다. 가우시안 프로세스에서 확률 변수의 joint gaussiantity을 가정합니다. 또한, 관측된 데이터에 대해 conditioning을 통해 함수에 대한 사후 분포(posterior distribution)을 결정할 수 있습니다.
- Latent linear Gaussian models : 이러한 모델에는 probabilistic principal component analysis(PPCA)가 포함됩니다. PPCA는 10.7장에서 조금 더 자세히 살펴볼 예정입니다.
Joint Gaussian distribution $p(\boldsymbol{x},\boldsymbol{y})$ 의 marginal distribution $p(\boldsymbol{x})$ 는 그 자체로 가우시안이며, (6.20)의 sum rule을 적용하여 계산될 수 있습니다. Marginal distribution은 다음과 같습니다.
\[p(\boldsymbol{x}) = \int p(\boldsymbol{x},\boldsymbol{y})\mathrm{d}\boldsymbol{y} = \mathcal{N}(\boldsymbol{x}|\boldsymbol{\mu}_x, \boldsymbol{\Sigma}_{xx}) \tag{6.68}\]위 결과는 $p(\boldsymbol{y})$ 에도 동일하게 적용되는데, 이는 $\boldsymbol{x}$ 에 대한 marginalization(주변화)를 통해 얻을 수 있습니다. 직관적으로 (6.64)에서 나타나는 joint distribution을 살펴보면, 관심있는 것들을 제외한 나머지는 모두 무시(즉, integrate out)하는 것입니다. 이는 아래쪽에 있는 Figure 6.9(b)에 해당합니다.
Example 6.6
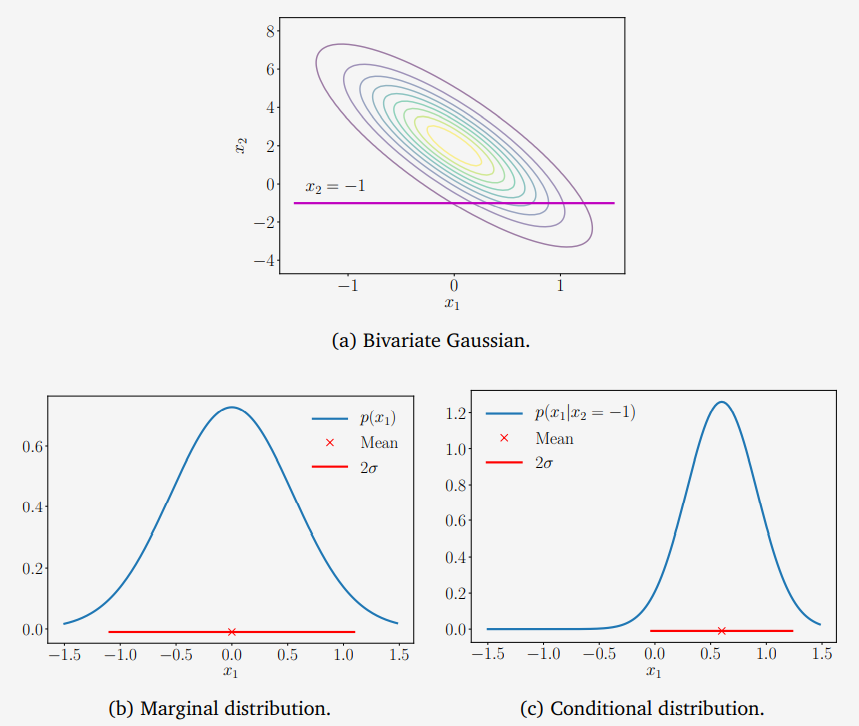
Figure 6.9위 그림 Figure 6.9에서 설명하는 bivariate Gaussian distribution에 대해 살펴보겠습니다.
\[p(x_1, x_2) = \mathcal{N}\left(\begin{bmatrix}0\\2\end{bmatrix},\begin{bmatrix}0.3&-1\\-1&5\end{bmatrix}\right) \tag{6.69}\]$x_2 = -1$ 라는 조건에 대해 Univariate Gaussian의 파라미터, 즉, 평균과 분산을 구하기 위해 식 (6.66)과 (6.67)을 적용합니다.
\[\begin{align*} \mu_{x_1|x_2=-1} &= 0 + (-1)\cdot 0.2\cdot(-1-2) = 0.6 \tag{6.70} \\ \sigma_{x_1|x_2=-1}^2 &= 0.3 - (-1)\cdot0.2\cdot(-1) = 0.1 \tag{6.71} \end{align*}\]따라서, conditional gaussian은 다음과 같이 주어집니다.
\[p(x_1|x_2=-1) = \mathcal{N}(0.6,0.1) \tag{6.72}\]이와 대조적으로 marginal distribution $p(x_1)$ 은 (6.68)을 적용하여 얻을 수 있는데, 근본적으로 확률 변수 $x_1$ 의 평균과 분산을 사용한 결과입니다.
\[p(x_1) = \mathcal{N}(0, 0.3) \tag{6.73}\]
Product of Gaussian Densities
Linear regression(Ch9)에 대해 다룰 때, Gaussian likelihood를 계산해야 합니다. 게다가, Gaussian prior(가우시안 사전 확률)을 가정할 수도 있습니다. Bayes’ Theorem을 사용하여 사후확률(posterior)를 계산할 수 있는데, 그 결과는 likelihood와 prior의 곱이며, 즉, 두 Gaussian densities의 곱으로 나타납니다. 두 가우시안의 곱 $\mathcal{N}(\boldsymbol{x}|\boldsymbol{a},\boldsymbol{A})\mathcal{N}(\boldsymbol{x}|\boldsymbol{b},\boldsymbol{B})$ 는 $c\in\mathbb{R}$ 로 스케일되는 Gaussian distribution이며 $c\mathcal{N}(\boldsymbol{x}|\boldsymbol{c},\boldsymbol{C})$ 로 주어집니다.
\[\begin{align*} \boldsymbol{C} &= (\boldsymbol{A}^{-1}+\boldsymbol{B}^{-1})^{-1} \tag{6.74} \\ \boldsymbol{c} &= \boldsymbol{C}(\boldsymbol{A}^{-1}\boldsymbol{a} + \boldsymbol{B}^{-1}\boldsymbol{b}) \tag{6.75} \\ c &= (2\pi)^{-\frac{D}{2}}|\boldsymbol{A}+\boldsymbol{B}|^{-\frac{1}{2}}\exp\left( -\frac{1}{2}(\boldsymbol{a}-\boldsymbol{b})^\top(\boldsymbol{A}+\boldsymbol{B})^{-1}(\boldsymbol{a}-\boldsymbol{b}) \right) \tag{6.76} \end{align*}\]Scaling constant $c$ 는 그 자체로 Gaussian density 형태이며, “inflated” covariance matrix $\boldsymbol{A}+\boldsymbol{B}$ 를 가지는 $\boldsymbol{a}$ 또는 $\boldsymbol{b}$ 에서의 Gaussian density 입니다. 즉, $c = \mathcal{N}(\boldsymbol{a}|\boldsymbol{b},\boldsymbol{A}+\boldsymbol{B}) = \mathcal{N}(\boldsymbol{b}|\boldsymbol{a},\boldsymbol{A}+\boldsymbol{B})$ 입니다.
Sums and Linear Transformations
만약 $X, Y$ 가 독립(independent)인 가우시안 확률 변수(즉, joint distribution이 $p(\boldsymbol{x},\boldsymbol{y}) = p(\boldsymbol{x})p(\boldsymbol{y})$ 로 주어지는 경우) 이고 $p(\boldsymbol{x}) = \mathcal{N}(\boldsymbol{x}|\boldsymbol{\mu}_x,\boldsymbol{\Sigma}_x)$ , $p(\boldsymbol{y}) = \mathcal{N}(\boldsymbol{y}|\boldsymbol{\mu}_y,\boldsymbol{\Sigma}_y)$ 라면, $\boldsymbol{x} + \boldsymbol{y}$ 또한 가우시안 분포를 따르며 다음과 같이 주어집니다.
\[p(\boldsymbol{x}+\boldsymbol{y}) = \mathcal{N}(\boldsymbol{\mu}_x+\boldsymbol{\mu}_y, \boldsymbol{\Sigma}_x + \boldsymbol{\Sigma}_y) \tag{6.78}\]$p(\boldsymbol{x}+\boldsymbol{y})$ 가 가우시안이므로, 평균(mean)과 공분산 행렬(covariance matrix)는 식 (6.46) ~ (6.49)를 이용하여 바로 구할 수 있습니다. 이러한 속성은 9장에서 linear regression의 경우와 같이 확률 변수에 작용하는 i.i.d.인 Gaussian noise를 고려할 때 매우 중요합니다.
Example 6.7
기댓값(expectations)는 linear operations 이므로, 독립인 가우시안 확률 변수의 가중합(weighted sum)을 얻을 수 있습니다.
\[p(a\boldsymbol{x}+b\boldsymbol{y}) = \mathcal{N}(a\boldsymbol{\mu}_x+b\boldsymbol{\mu}_y, a^2\boldsymbol{\Sigma}_x + b^2\boldsymbol{\Sigma}_y) \tag{6.79}\]
아래의 Theorem 6.12에서 확률 변수 $x$ 는 두 밀도(densities) $p_1(x)$ 와 $p_2(x)$ 가 혼합된 밀도로부터 $\alpha$ 만큼 가중됩니다. Expectation의 linearity가 multivariate random variables에도 성립하므로, 이 theorem은 multivariate random variable case로 일반화됩니다. 다만, 확률 변수의 제곱은 $\boldsymbol{xx}^\top$ 으로 대체됩니다.
Theorem6.12
다음과 같은 두 확률 변수의 혼합(mixture)를 고려해봅시다.
\[p(x) = \alpha p_1(x) + (1-\alpha)p_2(x) \tag{6.80}\]여기서 스칼라 $0<\alpha<1$ 은 mixture weight 이고, $p_1(x)$ 과 $p_2(x)$ 는 다른 파라미터를 갖는, 즉 $(\mu_1,\sigma_1^2) \neq (\mu_2, \sigma_2^2)$ 인 univariate Gaussian densities 입니다.
그러면 mixture density $p(x)$ 의 평균(mean) 은 각 확률 변수의 평균들의 가중합으로 주어집니다.
\[\mathbb{E}[x] = \alpha\mu_1 + (1-\alpha)\mu_2 \tag{6.81}\]Mixture density $p(x)$ 의 분산(variance)는 다음과 같이 주어집니다.
\[\mathbb{V}[x] = [\alpha\sigma_1^2 + (1-\alpha)\sigma_2^2] + \left([\alpha\mu_1^2 + (1-\alpha)\mu_2^2] - [\alpha\mu_1 + (1-\alpha)\mu_2]^2\right) \tag{6.82}\]
Proof ) Mixture density $p(x)$ 의 평균이 어떻게 각 확률 변수의 평균들의 가중합으로 계산되는지 증명해보도록 하겠습니다. 평균(mean)의 정의 (definitino 6.4)에 (6.80)을 적용하면 다음과 같습니다.
\[\begin{align*} \mathbb{E}[x] &= \int_{-\infty}^{\infty}xp(x)\mathrm{d}x \tag{6.83a} \\ &= \int_{-\infty}^{\infty}(\alpha xp_1(x) + (1-\alpha)xp_2(x))\mathrm{d}x \tag{6.83b} \\ &= \alpha\int_{-\infty}^{\infty}xp_1(x)\mathrm{d}x + (1-\alpha)\int_{-\infty}^{\infty}xp_2(x)\mathrm{d}x \tag{6.83c} \\ &= \alpha\mu_1 + (1-\alpha)\mu_2 \tag{6.83d} \end{align*}\]분산(variance)을 계산하려면 분산의 raw-score 버전 (6.44)를 사용할 수 있습니다. 여기서는 제곱된 확률 변수의 기댓값에 대한 표현식이 필요합니다. 확률 변수 제곱에 대한 기댓값의 정의(definition 6.3)를 사용하였습니다.
\[\begin{align*} \mathbb{E}[x^2] &= \int_{-\infty}^{\infty} x^2p(x)\mathrm{d}x \tag{6.84a} \\ &= \int_{-\infty}^{\infty} (\alpha x^2p_1(x) + (1-\alpha)x^2p_2(x))\mathrm{d}x \tag{6.84b} \\ &= \alpha\int_{-\infty}^{\infty} x^2p_1(x)\mathrm{d}x + (1-\alpha)\int_{-\infty}^{\infty}x^2p_2(x)\mathrm{d}x \tag{6.84c} \\ &= \alpha(\mu_1^2+\sigma_1^2) + (1-\alpha)(\mu_2^2 + \sigma_2^2) \tag{6.84d} \end{align*}\]여기서 마지막 등식은 raw-score 버전의 분산 (6.44)식을 통해 얻을 수 있는 $\sigma^2 = \mathbb{E}[x^2] - \mu^2$ 을 이용한 결과입니다. 이를 통해 제곱된 확률 변수의 기댓값이 평균의 제곱과 분산의 제곱의 합이 되도록 합니다.
따라서, (6.84d)에서 (6.83d)를 빼면 분산을 계산할 수 있습니다.
\[\begin{align*} \mathbb{V}[x] &= \mathbb{E}[x^2] - (\mathbb{E}[x])^2 \tag{6.85a} \\ &= \alpha(\mu_1^2+\sigma_1^2) + (1-\alpha)(\mu_2^2 + \sigma_2^2) - (\alpha\mu_1 + (1-\alpha)\mu_2)^2 \tag{6.85b} \\ &= [\alpha\sigma_1^2 + (1-\alpha)\sigma_2^2] + \left([\alpha\mu_1^2 + (1-\alpha)\mu_2^2] - [\alpha\mu_1+(1-\alpha)\mu_2]^2\right) \tag{6.85c} \end{align*}\]Mixture density에서 각 컴포넌트는 조건부 분포(conditional distributions)로 볼 수 있습니다. (6.85c) 식은 조건부 분산 공식의 한 예이며, 이는 law of total variance로 알려져 있습니다. 이는 일반적으로 두 개의 확률 변수 $X, Y$ 에 대해 $\mathbb{V}_X[x] = \mathbb{E}_Y[\mathbb{V}_X[x|y]] + \mathbb{V}_Y[\mathbb{E}_X[x|y]]$ 를 만족합니다. 즉, $X$ 의 (total) variance는 expected conditional variance + variance of a conditional mean 입니다.
Example 6.17 에서는 bivariate standard Gaussian random variable $X$ 에 linear transformation $\boldsymbol{Ax}$ 를 수행합니다. 그 결과는 평균이 0이고 공분산이 $\boldsymbol{AA}^\top$ 인 Gaussian random variable 입니다. 상수 벡터를 추가하면 분산에 영향을 주지 않으면서 분포의 평균이 변경되는 것을 확인할 수 있습니다. 즉, 확률 변수 $\boldsymbol{x}+\boldsymbol{\mu}$ 는 평균이 $\boldsymbol{\mu}$ 이고 공분산은 변경되지 않는 가우시안입니다. 따라서, 가우스 확률 변수의 linear/affine transformation은 여전히 가우시안 분포입니다.
가우시안 분포의 확률 변수 $X\sim\mathcal{N}(\boldsymbol{\mu},\boldsymbol{\Sigma})$ 를 고려해봅시다. 적절한 모양의 행렬 $\boldsymbol{A}$ 가 주어졌을 때, $Y$ 를 $\boldsymbol{y} = \boldsymbol{Ax}$ 를 만족하는 $\boldsymbol{x}$ 에서 변형된 버전의 확률 변수라고 합시다. 이때 $\boldsymbol{y}$ 의 평균은 expectation이 linear operator (6.50)라는 사실을 활용하여 다음과 같이 계산될 수 있습니다.
\[\mathbb{E}[\boldsymbol{y}] = \mathbb{E}[\boldsymbol{Ax}] = \boldsymbol{A}\mathbb{E}[\boldsymbol{x}] = \boldsymbol{A\mu} \tag{6.86}\]이와 유사하게, $\boldsymbol{y}$ 의 분산은 (6.51) 식을 사용하여 구할 수 있습니다.
\[\mathbb{V}[\boldsymbol{y}] = \mathbb{V}[\boldsymbol{Ax}] = \boldsymbol{A}\mathbb{V}[\boldsymbol{x}]\boldsymbol{A}^\top = \boldsymbol{A\Sigma A}^\top \tag{6.87}\]따라서, 확률 변수 $\boldsymbol{y}$ 는 다음의 분포를 따릅니다.
\[p(\boldsymbol{y}) = \mathcal{N}(\boldsymbol{y} | \boldsymbol{A\mu},\boldsymbol{A\Sigma A}^\top) \tag{6.88}\]이제 reverse transformation에 대해 살펴보겠습니다. 주어진 full rank 행렬 $\boldsymbol{A}\in\mathbb{R}^{M\times N}$ ($M\geq N$) 에 대해, $\boldsymbol{y}\in\mathbb{R}^M$ 이 평균이 $\boldsymbol{Ax}$ 인 가우시안 확률 변수라고 합시다. 즉, 다음의 분포를 따릅니다.
\[p(\boldsymbol{y}) = \mathcal{N}(\boldsymbol{y}|\boldsymbol{Ax},\boldsymbol{\Sigma}) \tag{6.89}\]이때, 대응되는 확률 분포 $p(\boldsymbol{x})$ 는 무엇일까요? 만약 $\boldsymbol{A}$ 의 역행렬이 존재한다면, 우리는 $\boldsymbol{x} = \boldsymbol{A}^{-1}\boldsymbol{y}$ 로 쓸 수 있고 위에서 살펴본 것처럼 transformation을 적용할 수 있습니다. 그러나 일반적으로 $\boldsymbol{A}$ 는 invertible 하지 않습니다. 이런 경우에는 pseudo-inverse (3.57)과 비슷한 접근법을 사용합니다. 즉, 양쪽의 항에 $\boldsymbol{A}^\top$ 을 곱한 뒤, symmetric, positive definite인 $\boldsymbol{A}^\top\boldsymbol{A}$ 역행렬을 곱합니다. 즉, 다음과 같습니다.
\[\boldsymbol{y}=\boldsymbol{Ax} \Longleftrightarrow (\boldsymbol{A}^\top\boldsymbol{A})^{-1}\boldsymbol{A}^\top\boldsymbol{y} = \boldsymbol{x} \tag{6.90}\]따라서, $\boldsymbol{x}$ 는 $\boldsymbol{y}$ 의 linear tranformation 이며, 다음과 같이 $p(\boldsymbol{x})$ 를 구할 수 있습니다.
\[p(\boldsymbol{x}) = \mathcal{N}(\boldsymbol{x}|(\boldsymbol{A}^\top\boldsymbol{A})^{-1}\boldsymbol{A}^\top\boldsymbol{y}, (\boldsymbol{A}^\top\boldsymbol{A})^{-1}\boldsymbol{A}^\top\boldsymbol{\Sigma A}(\boldsymbol{A}^\top\boldsymbol{A})^{-1}) \tag{6.91}\]Sampling from Multivariate Gaussian Distributions
컴퓨터에서의 무작위 샘플링을 할 때 복잡한 분포를 바로 샘플링하기는 어렵습니다. 이러한 경우, 간단한 분포, 예를 들어, uniform distribution 을 사용하여 난수를 뽑은 후, transformation을 통해 원하는 분포의 샘플링을 얻을 수 있습니다.
Multivariate Gaussian의 경우에는 세 단계의 프로세스를 통해 샘플링이 가능합니다.
- 먼저 [0, 1] 에서 uniform sample을 제공하는 pseudo-random numbers 소스가 필요합니다.
- Box-Muller transform과 같은 non-linear transformation을 사용하여 univariate Gaussian으로부터 샘플을 얻습니다.
- 이 샘플의 벡터를 수집하여 multivariate standard normal $\mathcal{N}(\boldsymbol{0},\boldsymbol{I})$ 로부터 샘플을 얻습니다.
일반적인 multivariate Gaussian, 즉, 평균이 0이 아니고 공분산이 항등행렬이 아닌 다변량 가우시안의 경우에는 가우시안 확률 변수의 linear transformation 속성을 이용합니다.
평균이 $\boldsymbol{\mu}$ , 공분산 행렬이 $\boldsymbol{\Sigma}$ 인 multivariate Gaussian distribution으로부터 샘플 $\boldsymbol{x}_i, i=1,\dotsc,n$ 을 생성한다고 가정해봅시다. 이런 경우에는 multivariate standard normal $\mathcal{N}(\boldsymbol{0},\boldsymbol{I})$ 로부터 샘플을 얻어서 원하는 샘플을 구성할 수 있습니다.
Multivariate normal $\mathcal{N}(\boldsymbol{\mu},\boldsymbol{\Sigma})$ 로부터 샘플을 얻기 위해서, 가우시안 확률 변수의 linear transformation 속성을 이용할 수 있습니다. 만약 $\boldsymbol{x}\sim\mathcal{N}(\boldsymbol{0},\boldsymbol{I})$ 라면 $\boldsymbol{y}=\boldsymbol{Ax}+\boldsymbol{\mu}$ (where $\boldsymbol{AA}^\top=\boldsymbol{\Sigma}$) 는 평균이 $\boldsymbol{\mu}$ 이고 공분산 행렬이 $\boldsymbol{\Sigma}$ 인 가우시안 분포입니다. $\boldsymbol{A}$ 를 선택하는 한 가지 편리한 방법은 공분산 행렬 $\boldsymbol{\Sigma} = \boldsymbol{AA}^\top$ 에 Cholesky decomposition (4.3장)을 사용하는 것입니다. Cholesky decomposition에서는 $\boldsymbol{A}$ 가 triangular 이기 때문에 연산 측면에서 효율적입니다.