Convex Optimization
7.3장에서는 global optimality를 보장하는 특별한 optimization problems를 집중적으로 살펴보겠습니다. $f(\cdot)$ 이 convex function 이고, $g(\cdot)$ 과 $h(\cdot)$ 을 포함하는 제약(constraints)이 convex sets 일 때, 이를 convex optimization problem 이라고 부릅니다.
이러한 조건에서는 strong duality를 갖는데, 이는 dual problem의 최적해가 primal problem의 최적해와 같다는 것을 의미합니다. Convex function과 convex sets는 머신러닝 문헌에서 엄격히 구분되지는 않지만 문맥을 통해서 내재된 의미를 추론할 수 있습니다.
Definition 7.2. Any $x, y\in\mathcal{C}$ 와 any scalar $\theta$ (with $0\leq\theta1$) 에 대해서, 아래의 식 (7.29)를 만족한다면 집합 $\mathcal{C}$ 는 convex set 입니다.
\[\theta x + (1-\theta)y \in \mathcal{C} \tag{7.29}\]
Convex sets은 집합의 두 요소를 연결하는 직선이 그 집합 내에 존재하는 집합입니다. 아래의 Figure 7.5와 7.6은 각각 convex set과 non-convex set 입니다.
(참고: link)

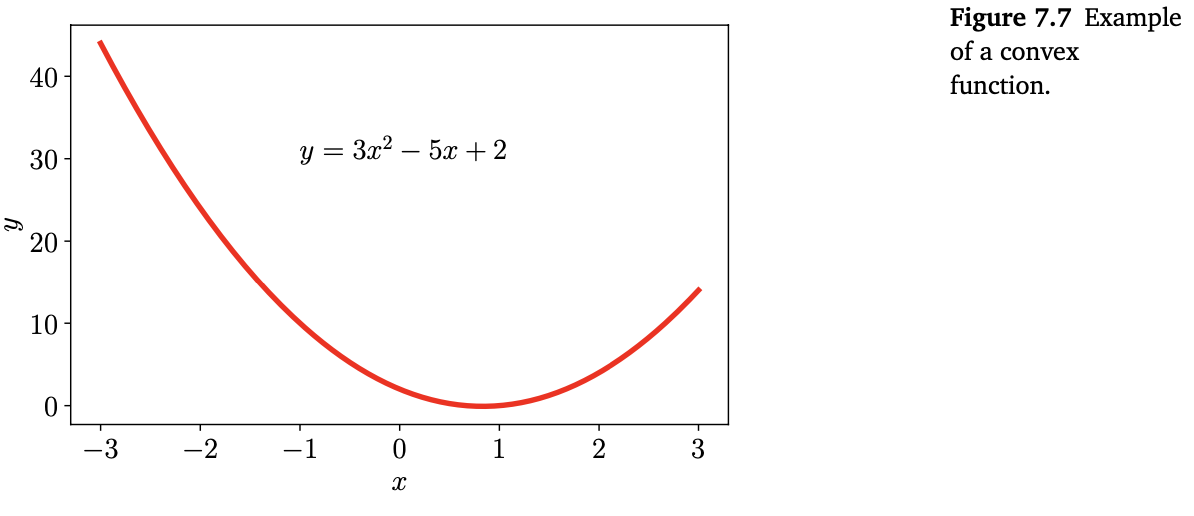
Convex functions은 함수의 어떤 두 점 간의 직선이 그 함수 위에 놓여 있는 함수입니다. Figure 7.2(7.0. Intro 참조) 의 함수가 바로 non-convex function 입니다. 임의의 두 점을 연결했을 때 함수 위쪽에 놓여지지 않는 직선이 존재합니다. Figure 7.3(7.1장 참조) 의 함수는 convex function 입니다. 또 다른 convex function의 예로는 아래의 Figure 7.7이 있습니다.
(참고: link)
Definition 7.3. 함수 $f:\mathbb{R}^D\rightarrow\mathbb{R}$ 의 domain이 convex set이라고 합시다. 만약 $f$ 의 domain에 있는 모든 $\boldsymbol{x},\boldsymbol{y}$ 그리고 모든 scalar $\theta$ (with $0\leq\theta\leq1$ ) 에 대해, 다음이 성립한다면,
\[f(\theta\boldsymbol{x} + (1-\theta)\boldsymbol{y}) \leq \theta f(\boldsymbol{x}) + (1-\theta)f(\boldsymbol{y}) \tag{7.30}\]함수 $f$ 는 convex function 입니다.
위의 (7.28) 식에서 $g(\cdot)$ 과 $h(\cdot)$ 을 포함하는 제약은 스칼라 값에서 함수를 잘라서 집합을 만듭니다. Convex functions과 convex sets의 또 다른 관계로는 convex function을 채워(filling in) 집합을 얻는 것으로 간주하는 것입니다. Convex function은 bowl과 같은 object이고, 이를 채우기 위해 물을 붓는 것에 비유할 수 있습니다. 이렇게 채워진 집합은 convex function의 epigraph 라고 부르며, 이 집합은 convex set 입니다 (참고: link).
만약 $f:\mathbb{R}^n\rightarrow\mathbb{R}$ 이 미분 가능하다면, f의 gradient $\nabla_{\boldsymbol{x}}f(\boldsymbol{x})$ 의 term으로 convexity를 특정할 수 있습니다. 만약 모든 어떤 두 점 $\boldsymbol{x},\boldsymbol{y}$ 에 대해 아래의 식이 성립한다면(if and only if),
\[f(\boldsymbol{y}) \geq f(\boldsymbol{x}) + \nabla_{\boldsymbol{x}}(\boldsymbol{x})^\top(\boldsymbol{y}-\boldsymbol{x}) \tag{7.31}\]함수 $f(\boldsymbol{x})$ 는 convex 입니다.
또한 함수 $f(\boldsymbol{x})$ 가 두 번 미분 가능, 즉, $\boldsymbol{x}$ 의 domain에서 모든 값들에 대해 Hessian (5.147)이 존재한다는 것을 알고 있을 때, $\nabla^2_{\boldsymbol{x}}f(\boldsymbol{x})$ 가 positive semidefinite라면(if and only if), 함수 $f(\boldsymbol{x})$ 는 convex 입니다.
Example 7.3
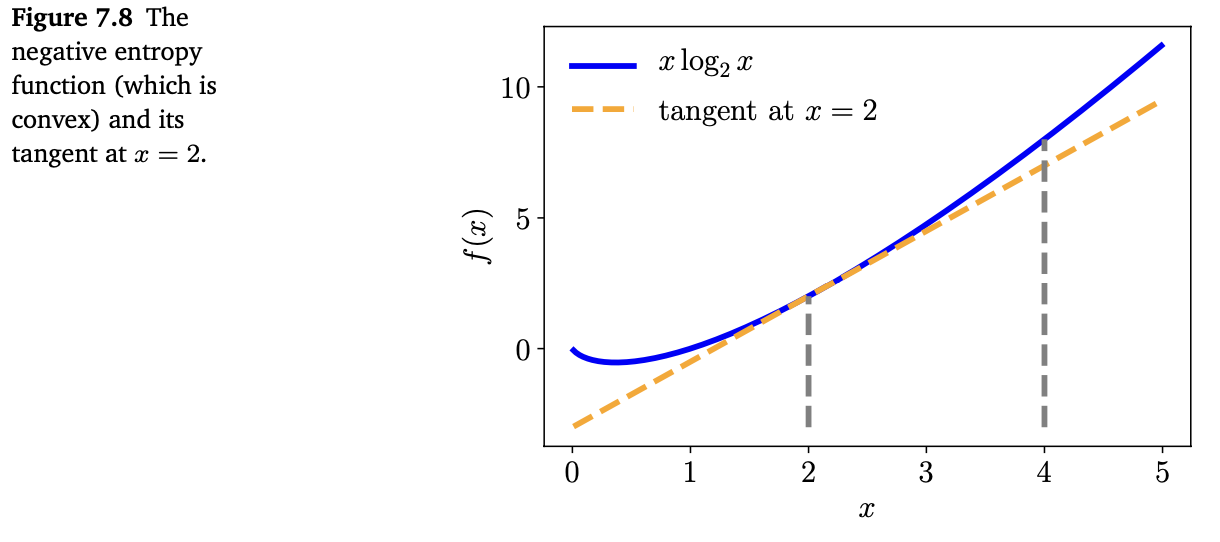
Negetive entropy $f(x) = x\log_2 x$ 는 $x>0$ 에서 convex 입니다. 이 함수를 시각화하면 아래의 Figure 7.8과 같습니다.
위 그래프를 보면, 함수가 convex라는 것을 확인할 수 있습니다. 위에서 정의한 convexity를 설명하기 위해서, $x=2, y=4$ 인 두 점에서의 계산을 확인해보겠습니다. 실제 $f(x)$ 가 convex하다는 것을 증명하려면 모든 점 $x\in\mathbb{R}$ 을 확인해야 합니다.
Definition 7.3을 떠올려봅시다. 두 점의 중간에 위치한 점(즉, $\theta =0.5$)에서 식 (7.30)의 좌항은 $f(0.5\cdot2+0.5\cdot4) = 3\log_2 3\approx4.75$ 입니다. 우항은 $0.5(2\log_2 2)+0.5(4\log_2 4) = 1 + 4 = 5$ 입니다. 따라서, Definition 7.3을 만족시킵니다.
$f(x)$ 는 미분 가능하므로, 식 (7.31)을 대신 사용할 수 있습니다. $f(x)$ 의 도함수를 계산하면 다음과 같습니다.
\[\nabla_x(x\log_2x) = 1\cdot\log_2x + x\cdot\frac{1}{x\log_e2} = \log_2x + \frac{1}{\log_e2} \tag{7.32}\]동일하게 두 점 $x=2, x=4$ 을 사용하면, (7.31)의 좌항은 $f(4) = 8$ 입니다. 우항은
\[\begin{align*} f(\boldsymbol{x}) + \nabla_{\boldsymbol{x}}^\top(\boldsymbol{y}-\boldsymbol{x}) &= f(2) + \nabla f(2)\cdot(4-2) \tag{7.33a} \\ &= 2 + (1+\frac{1}{\log_e2})\cdot2 \approx 6.9 \tag{7.33b} \end{align*}\]입니다. 즉, 조건을 만족합니다.
위에서 정의한 것들을 사용하여 함수나 집합이 convex한 지 체크할 수 있습니다. 실제로, 특정 함수나 집합이 convex한 지 확인하기 위해서 convexity를 유지하는 연산에 의지하는 경우가 많습니다. 세부적인 내용은 다르지만, 이는 2장에서 살펴본 vector spaces의 closure(닫힘) 개념과 같습니다 (참고: link).
Example 7.4
Convex 함수들의 nonnegative weighted sum 또한 convex 입니다. $f$ 가 convex function이고, $\alpha\geq 0$ 이 non-negative scalar이면, 함수 $\alpha f$ 도 convex 입니다. 이는 definition 7.3의 양 변에 $\alpha$ 를 곱하여 확인할 수 있습니다.
만약 $f_1$ 과 $f_2$ 가 convex functions라면, 정의에 의해서 다음이 성립합니다.
\[\begin{align*} f_1(\theta\boldsymbol{x} + (1-\theta)\boldsymbol{y}) \leq \theta f_1(\boldsymbol{x}) + (1-\theta)f_1(\boldsymbol{y}) \tag{7.34} \\ f_2(\theta\boldsymbol{x} + (1-\theta)\boldsymbol{y}) \leq \theta f_2(\boldsymbol{x}) + (1-\theta)f_2(\boldsymbol{y}) \tag{7.35} \end{align*}\]두 식을 합하면, 다음의 식이 됩니다.
\[\begin{align*} &f_1(\theta\boldsymbol{x} + (1-\theta)\boldsymbol{y}) + f_2(\theta\boldsymbol{x} + (1-\theta)\boldsymbol{y}) \\ &\leq \theta f_1(\boldsymbol{x}) + (1-\theta)f_1(\boldsymbol{y}) + \theta f_2(\boldsymbol{x}) + (1-\theta)f_2(\boldsymbol{y}) \tag{7.36} \end{align*}\]여기서 우항은 다음과 같이 정리될 수 있습니다.
\[\theta(f_1(\boldsymbol{x}) + f_2(\boldsymbol{x})) + (1-\theta)(f_1(\boldsymbol{y}) + f_2(\boldsymbol{y})) \tag{7.37}\]따라서, convex 함수들의 합 또한 convex 이라는 것이 증명됩니다.
위의 두 가지 증명을 결합하면, $\alpha,\beta \geq 0$ 에서 $\alpha f_1(\boldsymbol{x}) + \beta f_2(\boldsymbol{x})$ 또한 convex 라는 것을 확인할 수 있습니다. 이러한 closure property 는 둘 이상의 convex 함수들의 non-negative weighted sum 에도 적용됩니다.
요약하면, 제약있는 최적화 문제(constrained optimization problem)은 아래의 조건이 성립할 때,
\[\begin{align*} \min_{\boldsymbol{x}}\quad&f(\boldsymbol{x}) \\ \text{subject to}\quad&g_i(\boldsymbol{x}) \leq 0 \quad \text{for all}\quad i = 1,\dotsc,m \\ &h_j(\boldsymbol{x}) = 0 \quad \text{for all}\quad j = 1,\dotsc,n \\ \text{where all functions }& f(\boldsymbol{x}) \text{ and } g_i(\boldsymbol{x}) \text{ are convex functions,} \\ \text{and all } &h_j(\boldsymbol{x}) = 0 \text{ are convex sets.} \end{align*} \tag{7.38}\]convex optimization problem 이라고 부릅니다.
7.3장의 나머지 부분에서는 널리 사용되는 convex optimization problems 두 개를 살펴보도록 하겠습니다.
Linear Programming
위에서 살펴봤던 함수들이 모두 linear라고 간주한다면, 다음과 같이 표현할 수 있습니다.
\[\begin{align*} \min_{\boldsymbol{x}\in\mathbb{R}^d}\quad&\boldsymbol{c}^\top\boldsymbol{x} \tag{7.39} \\ \text{subject to}\quad&\boldsymbol{Ax}\leq\boldsymbol{b} \end{align*}\]위 식에서 $\boldsymbol{A}\in\mathbb{R}^{m\times d}$ 그리고 $\boldsymbol{b}\in\mathbb{R}^m$ 입니다. 이를 linear program(선형계획법) 이라고 합니다. 여기서는 $d$ 개의 변수와 $m$ 개의 선형 제약(linear constaints)를 가지고 있습니다.
위 문제에 Lagrangian은 다음과 같이 주어집니다.
\[\mathfrak{L}(\boldsymbol{x},\boldsymbol{\lambda}) = \boldsymbol{c}^\top\boldsymbol{x} + \boldsymbol{\lambda}^\top(\boldsymbol{Ax}-\boldsymbol{b}) \tag{7.40}\]여기서 $\boldsymbol{\lambda}\in\mathbb{R}^m$ 은 non-negative인 라그랑주 승수의 벡터입니다. $\boldsymbol{x}$ 에 대응되는 항들로 정리하면 다음과 같습니다.
\[\mathfrak{L}(\boldsymbol{x},\boldsymbol{\lambda}) = (\boldsymbol{c}+\boldsymbol{A}^\top\boldsymbol{\lambda})^\top\boldsymbol{x} - \boldsymbol{\lambda}^\top\boldsymbol{b} \tag{7.41}\]위 식을 통해 $\boldsymbol{x}$ 에 대한 $\mathfrak{L}(\boldsymbol{x},\boldsymbol{\lambda})$ 의 도함수를 구하고, 0과 같다고 설정하면 다음의 식을 얻을 수 있습니다.
\[\boldsymbol{c} + \boldsymbol{A}^\top\boldsymbol{\lambda} = \boldsymbol{0} \tag{7.42}\]따라서, dual Lagrangian 은 $\mathfrak{D}(\boldsymbol{\lambda}) = -\boldsymbol{\lambda}^\top\boldsymbol{b}$ 입니다.
$\mathfrak{L}(\boldsymbol{x},\boldsymbol{\lambda})$ 의 도함수가 0이기 때문에 제약이 있을 뿐만 아니라, $\boldsymbol{\lambda}\geq\boldsymbol{0}$ 이므로 결국 다음과 같은 dual optimization problem 이 만들어집니다.
\[\begin{align*} \max_{\boldsymbol{\lambda}\in\mathbb{R}^m}\quad&-\boldsymbol{b}^\top\boldsymbol{\lambda} \tag{7.32} \\ \text{subject to}\quad&\boldsymbol{c} + \boldsymbol{A}^\top\boldsymbol{\lambda} = \boldsymbol{0} \\ &\boldsymbol{\lambda}\geq\boldsymbol{0} \end{align*}\]이 또한 $m$ 개의 변수를 갖는 선형계획법입니다. 여기서 $m$ 또는 $d$ 중에 어느 것이 더 큰지에 따라 (7.39)의 primal 이나 (7.43)의 dual 중 선택하여 풀면 됩니다. 여기서 $d$ 는 primal program 에서 변수의 갯수이며 $m$ 은 primal program에서 제약의 갯수입니다.
Example 7.5 (Linear Program)
아래와 같이 주어진 2개의 변수를 갖는 linear program 을 살펴보겠습니다.
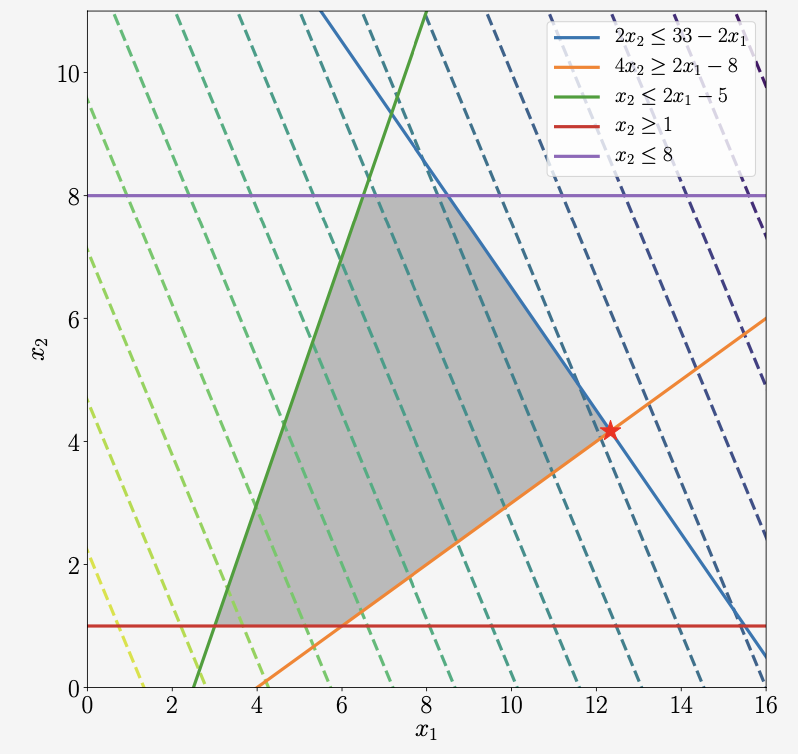
\[\begin{align*} \min_{\boldsymbol{x}\in\mathbb{R}^2}\quad&-\begin{bmatrix}5\\3\end{bmatrix}^\top\begin{bmatrix}x_1\\x_2\end{bmatrix} \\ \text{subject to}\quad&\begin{bmatrix}2&2\\2&-4\\-2&1\\0&-1\\0&1\end{bmatrix}\begin{bmatrix}x_1\\x_2\end{bmatrix} \leq \begin{bmatrix}33\\8\\5\\-1\\8\end{bmatrix} \end{align*} \tag{7.44}\]이 program은 아래의 Figure 7.9로 시각화됩니다.
목적 함수(objective function)가 linear 이므로, 선형인 등고선을 만듭니다. 표현 형태의 제약 집합은 legend로 변환됩니다. 최적값(optimal value)는 반드시 음영 처리된 영역에 있어야 하며, 이 문제의 최적값은 별표로 표시되어 있습니다.
Quadratic Programming
이번에는 제약 조건이 affine인 convex quadratic objective function 케이스를 살펴보도록 하겠습니다. 즉, 다음과 같습니다.
\[\begin{align*} \min_{\boldsymbol{x}\in\mathbb{R}^d}\quad&\frac{1}{2}\boldsymbol{x}^\top\boldsymbol{Qx} + \boldsymbol{c}^\top\boldsymbol{x} \tag{7.45} \\ \text{subject to}\quad&\boldsymbol{Ax}\leq\boldsymbol{b} \end{align*}\]여기서 $\boldsymbol{A}\in\mathbb{R}^{m\times d}, \boldsymbol{b}\in\mathbb{R}m$ 그리고 $\boldsymbol{c}\in\mathbb{R}^d$ 입니다.
Square symmetric matrix $\boldsymbol{Q}\in\mathbb{R}^{d\times d}$ 는 positive definite 이며, 따라서 목적 함수는 convex 입니다. 이를 quadratic program (2차계획법) 이라고 합니다. 여기에는 $d$ 개의 변수와 $m$ 개의 선형 제약이 있습니다.
Example 7.6 (Quadratic Program)
2개의 변수가 있는 quadratic program 문제를 살펴보겠습니다.
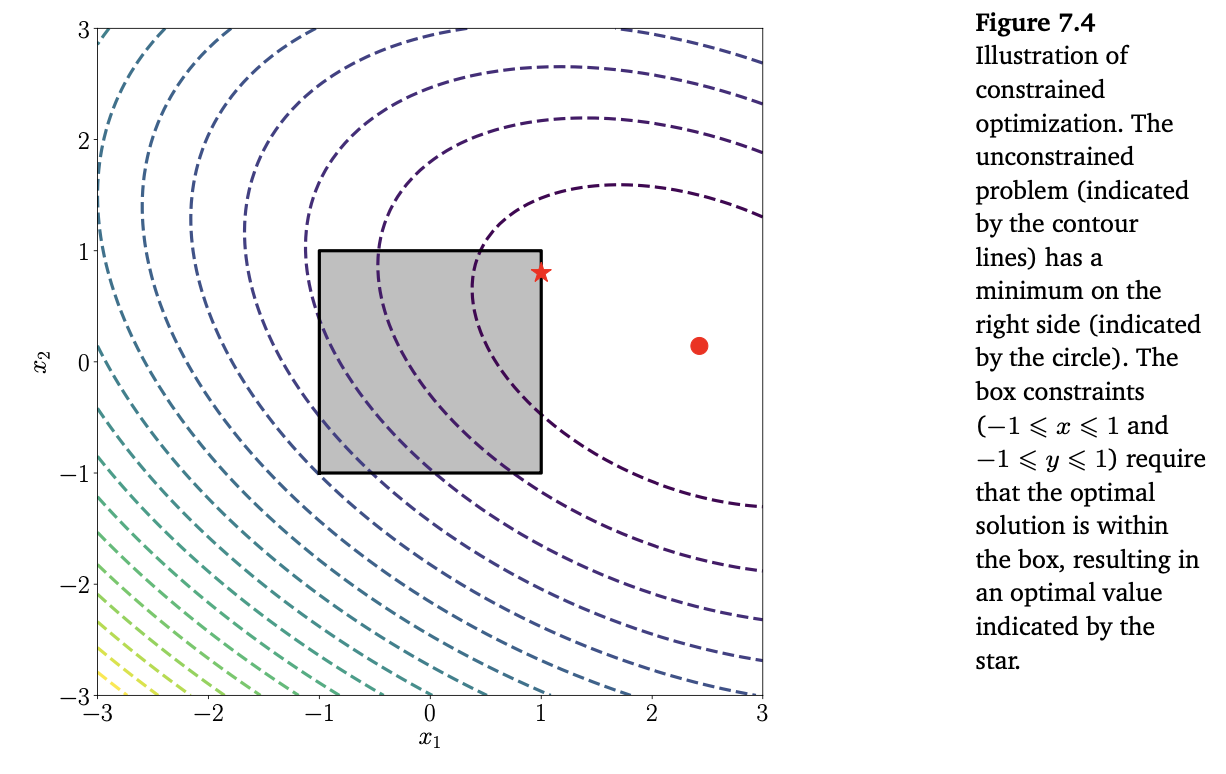
\[\begin{align*} \min_{\boldsymbol{x}\in\mathbb{R}^2}\quad&\frac{1}{2}\begin{bmatrix}x_1\\x_2\end{bmatrix}^\top\begin{bmatrix}2&1\\1&4\end{bmatrix}\begin{bmatrix}x_1\\x_2\end{bmatrix} + \begin{bmatrix}5\\3\end{bmatrix}^\top\begin{bmatrix}x_1\\x_2\end{bmatrix} \tag{7.46} \\ \text{subject to}\quad&\begin{bmatrix}1&0\\-1&0\\0&1\\0&-1\end{bmatrix}\begin{bmatrix}x_1\\x_2\end{bmatrix} \leq \begin{bmatrix}1\\1\\1\\1\end{bmatrix} \tag{7.47} \end{align*}\]이 문제는 Figure 7.4에서 설명하고 있습니다. 목적 함수(objective function)은 positive semidefinite matrix $\boldsymbol{Q}$ 를 가진 quadratic 이며, 타원형의 등고선을 만듭니다. 최적의 값은 음영 처리된 영역에 있어야 하며 최적값은 아래 Figure 7.4에 별표로 표시되어 있습니다.
Lagrangian은 다음과 같이 주어집니다.
\[\begin{align*} \mathfrak{L}(\boldsymbol{x},\boldsymbol{\lambda}) &= \frac{1}{2}\boldsymbol{x}^\top\boldsymbol{Qx} + \boldsymbol{c}^\top\boldsymbol{x} + \boldsymbol{\lambda}^\top(\boldsymbol{Ax}-\boldsymbol{b}) \tag{7.48a} \\ &= \frac{1}{2}\boldsymbol{x}^\top\boldsymbol{Qx} + (\boldsymbol{c}+\boldsymbol{A}^\top\boldsymbol{\lambda})^\top\boldsymbol{x} - \boldsymbol{\lambda}^\top\boldsymbol{b} \tag{7.48b} \end{align*}\]$\boldsymbol{x}$ 에 대한 $\mathfrak{L}(\boldsymbol{x},\boldsymbol{\lambda})$ 의 도함수를 구해 0과 같다고 설정하면, 다음의 식을 얻을 수 있습니다.
\[\boldsymbol{Qx} + (\boldsymbol{c}+\boldsymbol{A}^\top\boldsymbol{\lambda}) = 0 \tag{7.49}\]$\boldsymbol{Q}$ 가 invertible 하다고 가정한다면, 다음의 식으로 $\boldsymbol{x}$ 를 계산할 수 있습니다.
\[\boldsymbol{x} = -\boldsymbol{Q}^{-1}(\boldsymbol{c}+\boldsymbol{A}^\top\boldsymbol{\lambda}) \tag{7.50}\]식 (7.50)을 primal Lagrangian $\mathfrak{L}(\boldsymbol{x},\boldsymbol{\lambda})$ 에 치환하면, 다음의 dual Lagrangian을 얻을 수 있습니다.
\[\mathfrak{D}(\boldsymbol{\lambda}) = -\frac{1}{2}(\boldsymbol{c}+\boldsymbol{A}^\top\boldsymbol{\lambda})^\top\boldsymbol{Q}^{-1}(\boldsymbol{c} + \boldsymbol{A}^\top\boldsymbol{\lambda}) - \boldsymbol{\lambda}^\top\boldsymbol{b} \tag{7.51}\]따라서, dual optimization problem은 다음과 같이 주어집니다.
\[\begin{align*} \max_{\boldsymbol{\lambda}\in\mathbb{R}^m}\quad&-\frac{1}{2}(\boldsymbol{c}+\boldsymbol{A}^\top\boldsymbol{\lambda})^\top\boldsymbol{Q}^{-1}(\boldsymbol{c} + \boldsymbol{A}^\top\boldsymbol{\lambda}) - \boldsymbol{\lambda}^\top\boldsymbol{b} \\ \text{subject to}\quad&\boldsymbol{\lambda}\geq\boldsymbol{0} \end{align*} \tag{7.52}\]12장에서 quadratic programming을 머신러닝에 적용한 사례를 살펴봅니다.
Legendre-Fenchel Transform and Convex Conjugate
7.2장에서 살펴봤던 duality의 개념을 제약 조건이 없이 살펴보도록 하겠습니다. Convex set에 대한 한 가지 유용한 사실은 이는 convex set의 supporting hyperplanes(받침 초평면)로 동등하게 표현될 수 있다는 것입니다. 초평면(hyperplane)이 convex set과 교차하는 경우, 이러한 초평면을 supporting hyperplane 이라고 하며, convex set은 초평면의 한쪽 side에만 포함됩니다. 이전에 convex set인 epigraph를 얻기 위해서 convex function을 채운다고 했던 것을 상기해봅시다. 따라서, 우리는 convex function을 이들의 supporting hyperplanes의 term으로 표현할 수도 있습니다. 게다가, supporting hyperplane이 단지 convex function에 접하기만 한다면, 이는 그 점에서 함수의 접선이 됩니다. 어느 주어진 점 $\boldsymbol{x}_0$ 에서 함수 $f(\boldsymbol{x})$ 의 접선은 그 점에서 함수의 gradient $\left.\frac{\mathrm{d}f(\boldsymbol{x})}{\mathrm{d}\boldsymbol{x}}\right|_{\boldsymbol{x}=\boldsymbol{x}_0}$ 의 값 입니다.
요약하면, convex sets은 이들의 supporting hyperplanes로 동등하게 표현될 수 있기 때문에, convex functions는 이들의 gradients의 함수로 동등하게 표현될 수 있습니다. Legendre transform 은 이 개념을 공식화 합니다.
먼저 직관적이지는 않지만 가장 일반적인 정의에 대해서 먼저 살펴보고, 이를 직관적으로 표현할 수 있는 special case에 대해 살펴보도록 하겠습니다. Legendre-Fenchel transform 은 convex differentiable function $f(\boldsymbol{x})$ 을 접선(tangents) $s(\boldsymbol{x}) = \nabla_{\boldsymbol{x}}f(\boldsymbol{x})$ 와 연관된 함수로 변환하는 transformation 입니다. 이는 변수 $\boldsymbol{x}$ 나 $\boldsymbol{x}$ 에서 평가되는 함수가 아닌 함수 $f(\cdot)$ 에 대한 변환이라는 것에 유의합니다. Legendre-Fenchel transform은 convex conjugate 라고도 알려져 있으며, 이는 duality와 매우 밀접하게 연관되어 있습니다.
(참고: link)
Definition 7.4. 함수 $f:\mathbb{R}^D\rightarrow\mathbb{R}$ 의 convex conjugate 는 다음과 같이 정의되는 함수 $f^*$ 입니다.
\[f^*(\boldsymbol{s}) = \sup_{\boldsymbol{x}\in\mathbb{R}^D}(\langle\boldsymbol{s},\boldsymbol{x}\rangle - f(\boldsymbol{x})) \tag{7.53}\](여기서 $\sup$ 는 supremum을 의미하며 ‘상한’을 뜻합니다.)
위의 convex conjugate definition 에서는 함수 $f$ 가 convex 이거나 differentiable 일 필요는 없습니다. Definition 7.4에서는 일반적인 inner product를 사용헀지만, 아래에서는 기술적 문제들을 피하기 위해서 유한한 차원의 벡터의 표준 내적(standard dot product) $\langle\boldsymbol{s},\boldsymbol{x}\rangle = \boldsymbol{s}^\top\boldsymbol{x}$ 로 간주합니다.
Definition 7.4를 기하학적 방법으로 이해하려면, $f(x) = x^2$ 과 같은 간단한 1차원 conver & differentiable 함수를 고려해보면 됩니다. 1차원 문제에서 hyperplanes는 선으로 축소되며, 직선 $y=sx+c$ 로 간주할 수 있습니다. 위에서 convex function을 그들의 supporting hyperplanes로 설명할 수 있다고 언급했었습니다. 따라서, 함수 $f(x) = x^2$ 을 supporting lines으로 설명해보도록 하겠습니다.
직선 $s\in\mathbb{R}$ 의 gradient를 고정시키고, $f$ 의 그래프에서 각 점 $(x_0, f(x_0))$ 에 대해 직선이 $(x_0, f(x_0))$ 에 교차하는 $c$ 의 최솟값을 찾습니다. 여기서 $c$ 의 최솟값은 기울기가 $s$ 인 직선이 함수 $f(x)=x^2$ 와 접하는 위치입니다. $(x_0, f(x_0))$ 을 통과하면서 기울기가 $s$ 인 직선은 아래와 같이 주어집니다.
\[y-f(x_0) = s(x-x_0) \tag{7.54}\]이 직선의 y-절편은 $-sx_0 + f(x_0)$ 입니다. 따라서, $y=sx+c$ 가 $f$ 의 그래프와 교차하는 $c$ 의 최솟값은 다음과 같습니다 ($\inf$ 는 infimum 이며, ‘하한’을 뜻합니다).
\[\inf_{x_0} -sx_0 + f(x_0) \tag{7.55}\]앞서 정의한 convex conjugate 는 관례상 이것의 negative로 정의됩니다. 이는 일차원 convex & differentiable function에만 의존하는 것이 아닌 non-convex & non-differentiable 인 모든 함수 $f:\mathbb{R}^D\rightarrow\mathbb{R}$ 에도 적용됩니다.
Conjugate function은 nice한 속성을 가지고 있습니다. 예를 들어, convex function에 대해서, Legendre transform을 적용하여 다시 original function으로 돌아갑니다. $f(x)$ 의 기울기가 s인 것과 같은 방식으로 $f^*(s)$ 의 기울기는 x 입니다.
아래의 두 example은 머신러닝에서 일반적으로 사용되는 convex conjugates를 보여줍니다.
Example 7.7 (Convex Conjugates)
Convex conjugates의 응용을 설명하기 위해서, 다음의 quadratic function 을 살펴봅시다.
\[f(\boldsymbol{y}) = \frac{\lambda}{2}\boldsymbol{y}^\top\boldsymbol{K}^{-1}\boldsymbol{y} \tag{7.59}\]$\boldsymbol{K}\in\mathbb{R}^{n\times n}$ 은 positive definite matrix 입니다.
여기서 primal variable은 $\boldsymbol{y}\in\mathbb{R}^n$ 으로 표기하고, dual variable은 $\boldsymbol{\alpha}\in\mathbb{R}^n$ 으로 표기합니다.
Definition 7.4를 적용하면 다음의 함수를 얻을 수 있습니다.
\[f^*(\boldsymbol{\alpha}) = \sup_{\boldsymbol{y}\in\mathbb{R}^n}\langle\boldsymbol{y},\boldsymbol{\alpha}\rangle-\frac{\lambda}{2}\boldsymbol{y}^\top\boldsymbol{K}^{-1}\boldsymbol{y} \tag{7.60}\]함수가 미분 가능하기 때문에, $\boldsymbol{y}$ 에 대한 도함수를 구하고 0과 같다라고 설정하면 maximum을 찾을 수 있습니다.
\[\frac{\partial[\langle\boldsymbol{y},\boldsymbol{\alpha}-\frac{\lambda}{2}\boldsymbol{y}^\top\boldsymbol{K}^{-1}\boldsymbol{y}]}{\partial\boldsymbol{y}} = (\boldsymbol{\alpha}-\lambda\boldsymbol{K}^{-1}\boldsymbol{y})^\top \tag{7.61}\]Gradient가 0일 때, $\boldsymbol{y} = \frac{1}{\lambda}\boldsymbol{K\alpha}$ 입니다. 이를 (7.60)에 대입하면, 다음의 식을 얻을 수 있습니다.
\[f^*(\boldsymbol{\alpha}) = \frac{1}{\lambda}\boldsymbol{\alpha}^\top\boldsymbol{K\alpha}-\frac{\lambda}{2}\left(\frac{1}{\lambda}\boldsymbol{K\alpha}\right)^\top\boldsymbol{K}^{-1}\left(\frac{1}{\lambda}\boldsymbol{K\alpha}\right) = \frac{1}{2\lambda}\boldsymbol{\alpha}^\top\boldsymbol{K\alpha} \tag{7.62}\]
Example 7.8
머신러닝에서는 보통 함수들의 합을 사용합니다. 예를 들어, training set의 objective function으로 training set의 각 example들의 losses 합을 사용합니다. 이번에는 $l:\mathbb{R}\rightarrow\mathbb{R}$ 인 losses $l(t)$ 의 합의 convex conjugate를 유도해보도록 하겠습니다. 이 예제는 벡터의 경우에 convex conjugate를 어떻게 적용하는지도 보여줍니다.
여기서 $\mathcal{L}(\boldsymbol{t}) = \sum_{i=1}^n l_i(t_i)$ 입니다.
그러면,
\[\begin{align*} \mathcal{L}^*(\boldsymbol{z}) &= \sup_{\boldsymbol{t}\in\mathbb{R}^n}\langle\boldsymbol{z},\boldsymbol{t}\rangle - \sum_{i=1}^n l_i(t_i) \tag{7.63a} \\ &= \sup_{\boldsymbol{t}\in\mathbb{R}^n}\sum_{i=1}^n z_it_i - l_i(t_i)\quad\text{definition of dot product} \tag{7.63b} \\ &= \sum_{i=1}^n \sup_{\boldsymbol{t}\in\mathbb{R}^n} z_it_i - l_i(t_i) \tag{7.63c} \\ &= \sum_{i=1}^n l^*_i(z_i)\qquad\text{definition of conjugate} \tag{7.63d} \end{align*}\]입니다.
7.2장에서 우리는 라그랑주 승수(Lagrange multipliers)를 사용하여 dual optimization problem을 도출했습니다. 게다가, convex optimization problem에서 primal의 해는 dual problem의 해가 동일하다는 strong duality에 대해 다루었습니다.
7.3.3장에서 다룬 Legendre-Fenchel transform 또한 dual optimization problem을 도출하는데 사용될 수 있습니다. 더불어, 함수가 convex하고 미분 가능할 때, 상한(supremum)은 유일합니다.
이러한 두 가지 접근 방법 간의 관계를 더 살펴보기 위해서, linear equality constrained convex optimization problem을 살펴보도록 하겠습니다.
Example 7.9
$f(\boldsymbol{y})$ 와 $g(\boldsymbol{x})$ 가 convec functions 이고, 행렬 $\boldsymbol{A}$ 가 $\boldsymbol{Ax}=\boldsymbol{y}$ 를 만족하는 적절한 차원의 real matrix 라고 가정합시다. 그러면, 다음의 식이 성립합니다.
\[\min_{\boldsymbol{x}}f(\boldsymbol{Ax}) + g(\boldsymbol{x}) = \min_{\boldsymbol{Ax}=\boldsymbol{y}}f(\boldsymbol{y}) + g(\boldsymbol{x}) \tag{7.64}\]제약 조건 $\boldsymbol{Ax}=\boldsymbol{y}$ 에 대한 라그랑주 승수 $\boldsymbol{u}$ 를 도입하면,
\[\begin{align*} \min_{\boldsymbol{Ax}=\boldsymbol{y}}f(\boldsymbol{y}) + g(\boldsymbol{x}) &= \min_{\boldsymbol{x},\boldsymbol{y}}\max_{\boldsymbol{u}}f(\boldsymbol{y})+g(\boldsymbol{x}) + (\boldsymbol{Ax}-\boldsymbol{y})^\top\boldsymbol{u} \tag{7.65a} \\ &= \max_{\boldsymbol{u}}\min_{\boldsymbol{x},\boldsymbol{y}}f(\boldsymbol{y})+g(\boldsymbol{x}) + (\boldsymbol{Ax}-\boldsymbol{y})^\top\boldsymbol{u} \tag{7.65b} \end{align*}\]이고, 여기서 $f(\boldsymbol{y})$ 와 $g(\boldsymbol{x})$ 가 convex function이기 때문에 마지막 줄의 max와 min의 위치를 바꾸었습니다.
Dot product term을 분리하고, $\boldsymbol{x}$ 와 $\boldsymbol{y}$ 에 대해 정리하면,
\[\begin{align*} &\max_{\boldsymbol{u}}\min_{\boldsymbol{x},\boldsymbol{y}}f(\boldsymbol{y}) + g(\boldsymbol{x}) + (\boldsymbol{Ax}-\boldsymbol{y})^\top\boldsymbol{u} \tag{7.66a} \\ =&\max_{\boldsymbol{u}}\left\lbrack\min_{\boldsymbol{y}}-\boldsymbol{y}^\top\boldsymbol{u}+f(\boldsymbol{y})\right\rbrack + \left\lbrack\min_{\boldsymbol{x}}(\boldsymbol{Ax})^\top\boldsymbol{u} + g(\boldsymbol{x})\right\rbrack \tag{7.66b} \\ =&\max_{\boldsymbol{u}}\left\lbrack\min_{\boldsymbol{y}}-\boldsymbol{y}^\top\boldsymbol{u}+f(\boldsymbol{y})\right\rbrack + \left\lbrack\min_{\boldsymbol{x}}\boldsymbol{x}^\top\boldsymbol{A}^\top\boldsymbol{u} + g(\boldsymbol{x})\right\rbrack \tag{7.66c} \end{align*}\]Definition 7.4의 convex conjugate와 dot product가 symmetric 하다는 사실을 통해 다음의 식이 도출됩니다.
\[\begin{align*} &\max_{\boldsymbol{u}}\left\lbrack\min_{\boldsymbol{y}}-\boldsymbol{y}^\top\boldsymbol{u}+f(\boldsymbol{y})\right\rbrack + \left\lbrack\min_{\boldsymbol{x}}\boldsymbol{x}^\top\boldsymbol{A}^\top\boldsymbol{u} + g(\boldsymbol{x})\right\rbrack \tag{7.67a} \\ =&\max_{\boldsymbol{u}}-f^*(\boldsymbol{u}) - g^*(-\boldsymbol{A}^\top\boldsymbol{u}) \tag{7.67b} \end{align*}\]따라서, 다음의 식이 성립합니다.
\[\min_{\boldsymbol{x}}f(\boldsymbol{Ax}) + g(\boldsymbol{x}) = \max_{\boldsymbol{u}}-f^*(\boldsymbol{u}) - g^*(-\boldsymbol{A}^\top\boldsymbol{u}) \tag{7.68}\]
Legendre-Fenchel conjugate는 convex optimization problem으로 표현될 수 있는 머신러닝 문제에 대해 매우 유용합니다. 특히, 각 샘플(or example)에 독립적으로 적용되는 convex loss function에 대해 conjugate loss는 dual problem을 유도하는 편리한 방법입니다.