Bayesian Linear Regression
이전 장에서 maximum likelihood 또는 MAP estimation을 통해 모델의 파라미터 $\boldsymbol{\theta}$ 를 추정한 linear regression 모델을 살펴봤습니다. 여기서 우리는 MLE가 특히 데이터가 소규모일 때, 과적합을 유발할 수 있다는 것을 발견했습니다. MAP는 regularizer의 역할을 수행하는 사전 확률을 파라미터에 배치하여 이 문제를 해결합니다.
Bayesian linear regression 는 파라미터 사전 분포의 아이디어에서 한 발 더 나아가, 파라미터의 point estimate를 계산하려고 시도하는 것이 아닌 예측할 때 매개변수에 대한 전체 사후 분포가 고려됩니다. 이는 우리가 어떠한 파라미터에도 피팅하진 않지만, 모든 가능성 있는 파라미터에 대한 평균을 계산하는 것을 의미합니다.
Model
Bayesian linear regression에서는 다음의 모델을 고려합니다.
\[\begin{align*} \text{prior} \qquad\quad &p(\boldsymbol{\theta}) = \mathcal{N}(\boldsymbol{m}_0, \boldsymbol{S}_0) \\ \text{likelihood}\quad& p(y|\boldsymbol{x},\boldsymbol{\theta}) = \mathcal{N}(y|\phi^\top(\boldsymbol{x})\boldsymbol{\theta},\sigma^2) \end{align*} \tag{9.35}\]여기서는 이제 명시적으로 $\boldsymbol{\theta}$ 에 대한 Gaussian prior $p(\boldsymbol{\theta}) = \mathcal{N}(\boldsymbol{m}_0, \boldsymbol{S}_0$ 을 배치합니다. 이는 파라미터 벡터를 확률 변수로 바꿉니다. 이를 graphical model로 표현하면 아래와 같습니다.
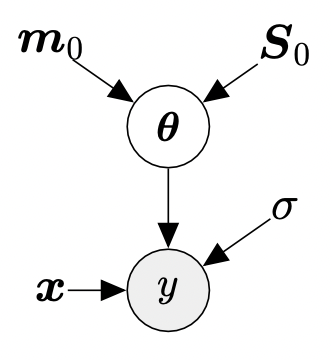
Full probabilistic model, 즉, 관측된 것과 관측되지 않은 변수 $y$ 와 $\boldsymbol{\theta}$ 의 joint distribution은 아래와 같습니다.
\[p(y,\boldsymbol{\theta}|\boldsymbol{x}) = p(y|\boldsymbol{x},\boldsymbol{\theta})p(\boldsymbol{\theta}) \tag{9.36}\]Prior Predictions
사실, 일반적으로 파라미터 값 $\boldsymbol{\theta}$ 자채에 대해서는 그다지 관심이 없습니다. 그 대신 우리의 관심은 이러한 파라미터 값으로 만드는 예측값에 있습니다. 베이지안 설정에서 예측할 때, 우리는 모든 그럴듯한 파라미터 설정에 대한 분포와 평균을 취합니다. 구체적으로 말하면, input $\boldsymbol{x}$ 에서의 예측을 위해, $\boldsymbol{\theta}$ 를 적분하고 다음의 식을 얻습니다.
\[p(y_{\ast}|\boldsymbol{x}_{\ast}) = \int p(y_{\ast}|\boldsymbol{x}_{\ast},\boldsymbol{\theta})p(\boldsymbol{\theta})\mathrm{d}\boldsymbol{\theta} = \mathbb{E}_{\boldsymbol{\theta}}[p(y_{\ast}|\boldsymbol{x}_{\ast},\boldsymbol{\theta})] \tag{9.37}\]이는 사전 분포 $p(\boldsymbol{\theta})$ 를 따르는 모든 그럴듯한 파라미터 $\boldsymbol{\theta}$ 에 대한 $y_{\ast}|\boldsymbol{x}_{\ast},\boldsymbol{\theta}$ 의 평균 예측으로 해석할 수 있습니다.
(9.35)로 표현되는 모델에서, 우리는 $\boldsymbol{\theta}$ 에 대해 conjugate (Gaussian) prior를 선택하고, 따라서, 예측된 분포 또한 Gaussian 입니다. 사전 분포 $p(\boldsymbol{\theta})=\mathcal{N}(\boldsymbol{m}_0,\boldsymbol{S}_0)$ 을 가지고, 우리는 다음의 예측된 분포를 얻습니다.
\[p(y_{\ast}|\boldsymbol{x}_{\ast}) = \mathcal{N}(\phi^\top(\boldsymbol{x}_{\ast})\boldsymbol{m}_0, \phi^\top(\boldsymbol{x}_{\ast})\boldsymbol{S}_0\phi(\boldsymbol{x}_{\ast}) + \sigma^2) \tag{9.38}\]여기서 (1) prediction은 conjugacy과 Gaussian의 marginalization property 때문에 Gaussian이고, (2) Gaussian noise가 독립이기에 다음을 만족한다는 것과
\[\mathbb{V}[y_{\ast}] = \mathbb{V}_{\boldsymbol{\theta}}[\phi^\top(\boldsymbol{x}_{\ast}\boldsymbol{\theta})] + \mathbb{V}_\epsilon[\epsilon] \tag{9.39}\](3) $y_{\ast}$ 가 $\boldsymbol{\theta}$ 의 linear transformation이어서 (6.50)과 (6.51)을 사용하여 각각 예측의 평균과 공분산을 계산할 수 있다는 것을 활용합니다. 식 (9.38)의 분산에서 $\phi^\top(\boldsymbol{x}_{\ast})\boldsymbol{S}_0\phi(\boldsymbol{x}_{\ast})$ 항은 파라미터 $\boldsymbol{\theta}$ 와 관련된 불확실성을 명시적으로 설명하는 반면, $\sigma^2$ 는 측정 노이즈로 인한 불확실성 기여도입니다.
만약 noise-corrputed targets $y_{\ast}$ 대신 noise-free function values $f(\boldsymbol{x}_{\ast}) = \phi^\top(\boldsymbol{x}_{\ast})\boldsymbol{\theta}$ 를 예측하는데 관심이 있다면, 다음의 식을 얻습니다.
\[p(f(\boldsymbol{x}_{\ast})) = \mathcal{N}(\phi^\top(\boldsymbol{x}_{\ast})\boldsymbol{m}_0, \phi^\top(\boldsymbol{x}_{\ast})\boldsymbol{S}_0\phi(\boldsymbol{x}_{\ast})) \tag{9.40}\](9.38) 식과 비교하면 predictive variance에서 노이즈 분산 $\sigma^2$ 만 생략되었습니다.
Example 9.7 (Prior over Functions)
5차 다항식의 베이지안 linear regression 문제를 살펴봅시다. 여기서 파라미터의 사전 확률은 $p(\boldsymbol{\theta}) = \mathcal{N}(\boldsymbol{0},\frac{1}{4}\boldsymbol{I})$ 로 선택합니다. 위의 그림은 이 파라미터 사전 확률에 의해 유도된 함수에 대한 유도된 사전 분포를 시각화합니다(dark gray: 67% 신뢰범위, light gray: 95% 신뢰범위). 함수 샘플은 먼저 매개변수 벡터 $\boldsymbol{\theta}_i\sim p(\boldsymbol{\theta})$ 를 샘플링한 다음 $f_i(\cdot) = \boldsymbol{\theta}_i^\top\phi(\cdot)$ 을 계산하여 얻습니다. 여기서는 200개의 input locations $x_{\ast}\in[-5,5]$ 를 사용하여 feature function $\phi(\cdot)$ 에 적용하였습니다. 위 그림에서의 불확실성은 noise-free predictive 분포 (9.40)을 고려했기 때문에 오직 파라미터의 불확실성으로 인한 것입니다.
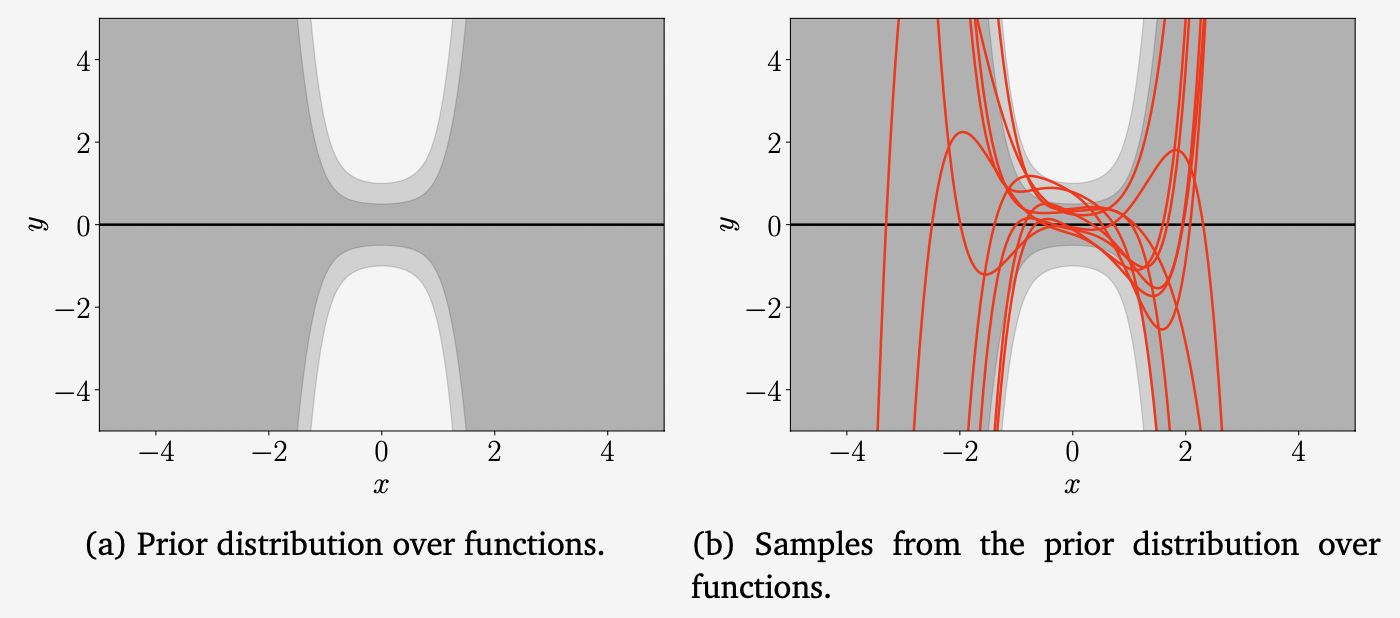
지금까지 파라미터의 사전 확률 $p(\boldsymbol{\theta})$ 를 사용하여 예측을 계산하는 방법을 살펴봤습니다. 그러나 파라미터의 사후 분포가 있을 때, 예측과 추론에 대한 동일한 원칙은 (9.37)에서와 같이 유지됩니다. 단지 사전 확률 $p(\boldsymbol{\theta})$ 를 사후 확률 $p(\boldsymbol{\theta}|\mathcal{X, Y})$ 로 바꾸기만 하면 됩니다.
이어서 사후 분포를 예측에 사용하기 전에 사후 분포를 유도하는 방법에 대해 자세히 살펴보도록 하겠습니다.
Posterior Distribution
Trainin set의 inputs $\boldsymbol{x}_n \in \mathbb{R}^D$ 와 대응되는 관측값 $y_n\in\mathbb{R}, n=1,\dotsc,N$ 이 주어졌을 때, 우리는 베이즈 정리를 사용하여 다음과 같이 파라미터에 대한 사후 확률을 계산할 수 있습니다.
\[p(\boldsymbol{\theta}|\mathcal{X,Y}) = \frac{p(\mathcal{Y}|\mathcal{X},\boldsymbol{\theta})p(\boldsymbol{\theta})}{p(\mathcal{Y|X})} \tag{9.41}\]여기서 $\mathcal{X}$ 는 training inputs 집합이고 $\mathcal{Y}$ 는 대응되는 training targets의 집합입니다. 또한, $p(\mathcal{Y}|\mathcal{X},\boldsymbol{\theta})$ 는 likelihood 이고, $p(\boldsymbol{\theta})$ 는 파라미터 사전 확률, 그리고
\[p(\mathcal{Y|X}) = \int p(\mathcal{Y}|\mathcal{X},\boldsymbol{\theta})p(\boldsymbol{\theta})\mathrm{d}\boldsymbol{\theta} = \mathbb{E}_{\boldsymbol{\theta}}[p(\mathcal{Y}|\mathcal{X},\boldsymbol{\theta})] \tag{9.42}\]는 marginal likelihood/evidence 이며, 이는 파라미터 $\boldsymbol{\theta}$ 에 독립적이며 사후 확률이 정규화(normalization) 되었다는 것을 보장합니다. 즉, 적분하면 1이 됩니다. 이 marginal likelihood는 모든 가능한 파라미터 값에 대해 평균을 낸 likelihood라고 생각할 수 있습니다.
Theorem 9.1 (Parameter Posterior). (9.35) 모델에서 parameter posterior (9.41)은 closed form 으로 다음과 같이 계산될 수 있습니다.
\[\begin{align*} p(\boldsymbol{\theta}|\mathcal{X,Y}) &= \mathcal{N}(\boldsymbol{\theta}|\boldsymbol{m}_N,\boldsymbol{S}_N) \tag{9.43a} \\ \boldsymbol{S}_N &= (\boldsymbol{S}^{-1}_0 + \sigma^{-2}\boldsymbol{\Phi}^\top\boldsymbol{\Phi})^{-1} \tag{9.43b} \\ \boldsymbol{m}_N &= \boldsymbol{S}_N(\boldsymbol{S}^{-1}_0\boldsymbol{m}_0 + \sigma^{-2}\boldsymbol{\Phi}^\top\boldsymbol{y}) \tag{9.43c} \end{align*}\]여기서 아래첨자 $N$ 은 training set의 크기를 나타냅니다.
Proof) 베이즈 정리에 의해 사후 확률 $p(\boldsymbol{\theta}|\mathcal{X,Y})$ 는 likelihood $p(\mathcal{Y}|\mathcal{X},\boldsymbol{\theta})$ 와 사전 확률 $p(\boldsymbol{\theta})$ 의 곱에 비례합니다.
\[\begin{align*} \text{Posterior} \qquad &p(\boldsymbol{\theta}|\mathcal{X,Y}) = \frac{p(\mathcal{Y}|\mathcal{X},\boldsymbol{\theta})p(\boldsymbol{\theta})}{p(\mathcal{Y}|\mathcal{X})} \tag{9.44a} \\ \text{Likelihood}\qquad &p(\mathcal{Y}|\mathcal{X},\boldsymbol{\theta}) = \mathcal{N}(\boldsymbol{y}|\boldsymbol{\Phi\theta}, \sigma^2\boldsymbol{I}) \tag{9.44b} \\ \text{Prior}\qquad &p(\boldsymbol{\theta}) = \mathcal{N}(\boldsymbol{\theta}|\boldsymbol{m}_0, \boldsymbol{S}_0) \tag{9.44c} \end{align*}\]사전 확률과 likelihood의 곱을 log-space로 문제를 변환하고 제곱하여 사후 확률의 평균과 분산에 대해 풉니다.
log-prior와 log-likelihod의 합은 아래와 같습니다.
\[\begin{align*} &\log\mathcal{N}(\boldsymbol{y}|\boldsymbol{\Phi\theta},\sigma^2\boldsymbol{I}) + \log\mathcal{N}(\boldsymbol{\theta}|\boldsymbol{m}_0,\boldsymbol{S}_0) \tag{9.45a} \\ &=-\frac{1}{2}(\sigma^{-2}(\boldsymbol{y}-\boldsymbol{\Phi\theta})^\top(\boldsymbol{y}-\boldsymbol{\Phi\theta}) + (\boldsymbol{\theta}-\boldsymbol{m}_0)^\top\boldsymbol{S}^{-1}_0(\boldsymbol{\theta}-\boldsymbol{m}_0)) + \text{const} \tag{9.45b} \end{align*}\]여기서 상수항은 $\boldsymbol{\theta}$ 에 독립적인 항들을 포함합니다. 이 상수항을 무시하면, (9.45b) 를 다음과 같이 풀 수 있습니다.
\[\begin{align*} &-\frac{1}{2}(\sigma^{-2}\boldsymbol{y}^\top\boldsymbol{y}-{\color{orange}2\sigma^{-2}\boldsymbol{y}^\top\boldsymbol{\Phi\theta}} + {\color{blue}\boldsymbol{\theta}^\top\sigma^{-2}\boldsymbol{\Phi}^\top\boldsymbol{\Phi\theta}+\boldsymbol{\theta}^\top\boldsymbol{S}_0^{-1}\boldsymbol{\theta}}) - {\color{orange}2\boldsymbol{m}_0^\top\boldsymbol{S}_0^{-1}\boldsymbol{\theta}} + \boldsymbol{m}_0^\top\boldsymbol{S}_0^{-1}\boldsymbol{m}_0 \tag{9.46a} \\ =&-\frac{1}{2}({\color{blue}\boldsymbol{\theta}^\top(\sigma^{-2}\boldsymbol{\Phi}^\top\boldsymbol{\Phi}+\boldsymbol{S}^{-1}_0)\boldsymbol{\theta}} - {\color{orange}2(\sigma^{-2}\boldsymbol{\Phi}^\top\boldsymbol{y}+\boldsymbol{S}_0^{-1}\boldsymbol{m}_0)^\top\boldsymbol{\theta}}) + \text{const} \tag{9.46b} \end{align*}\]여기서 상수항은 (9.46a) 에서 검정색으로 표시된 항이며 파라미터에 독립적입니다. 주황색 항들은 $\boldsymbol{\theta}$ 에 linear 하며, 파란색 항들은 $\boldsymbol{\theta}$ 에 제곱인 항들 입니다. (9.46b) 식을 살펴보면, 이 방정식이 $\boldsymbol{\theta}$ 에 이차식이라는 것을 알 수 있습니다. 정규화되지 않은 log-posterior distribution이 (negative) 이차 형태라는 사실은 posterior가 Gaussian 이라는 것을 의미합니다. 즉,
\[\begin{align*} &p(\boldsymbol{\theta}|\mathcal{X,Y}) = \exp(\log p(\boldsymbol{\theta}|\mathcal{X,Y})) \propto \exp(\log p(\mathcal{Y}|\mathcal{X},\boldsymbol{\theta}) + \log p(\boldsymbol{\theta})) \tag{9.47a} \\ &\propto \exp\left(-\frac{1}{2}({\color{blue}\boldsymbol{\theta}^\top(\sigma^{-2}\boldsymbol{\Phi}^\top\boldsymbol{\Phi}+\boldsymbol{S}_0^{-1})\boldsymbol{\theta}} - {\color{orange}2(\sigma^{-2}\boldsymbol{\Phi}^\top\boldsymbol{y}+\boldsymbol{S}_0^{-1}\boldsymbol{m}_0)^\top\boldsymbol{\theta}})\right) \tag{9.47b} \end{align*}\]입니다. 마지막 방정식에서는 (9.46b)를 사용했습니다.
남은 작업은 이 (unnormalized) 가우시안을 $\mathcal{N}(\boldsymbol{\theta}|\boldsymbol{m}_N,\boldsymbol{S}_N$ 에 비례하는 형태로 가져오는 것인데, 즉, 평균 $\boldsymbol{m}_N$ 과 공분산 행렬 $\boldsymbol{S}_N$ 을 일치시킬 필요가 있습니다. 이를 위해서 completing the squares 개념을 사용합니다. 원하는 log-posterior는 다음과 같습니다.
\[\begin{align*} \log&\mathcal{N}(\boldsymbol{\theta}|\boldsymbol{m}_N,\boldsymbol{S}_N) = -\frac{1}{2}(\boldsymbol{\theta}-\boldsymbol{m}_N)^\top\boldsymbol{S}_N^{-1}(\boldsymbol{\theta}-\boldsymbol{m}_N) + \text{const} \tag{9.48a} \\ &=-\frac{1}{2}({\color{blue}\boldsymbol{\theta}^\top\boldsymbol{S}_N^{-1}\boldsymbol{\theta}} - {\color{orange}2\boldsymbol{m}_N^\top\boldsymbol{S}_N^{-1}\boldsymbol{\theta}}+\boldsymbol{m}_N^\top\boldsymbol{S}_N^{-1}\boldsymbol{m}_N) \tag{9.48b} \end{align*}\]여기서 이차 형태인 $(\boldsymbol{\theta}-\boldsymbol{m}_N)^\top\boldsymbol{S}_N^{-1}(\boldsymbol{\theta}-\boldsymbol{m}_N)$ 을 인수분해하여 파란색의 $\boldsymbol{\theta}$ 의 이차식, 주황색의 $\boldsymbol{\theta}$ 의 linear, 그리고 검정색의 상수항으로 분리했습니다. 이제 (9.46b)와 (9.48b)에서 각각의 색상끼리 매칭하여 $\boldsymbol{S}_N$ 과 $\boldsymbol{m}_N$ 을 찾을 수 있습니다. 그 결과는
\[\begin{align*} &\boldsymbol{S}_N^{-1} = \boldsymbol{\Phi}^\top\sigma^{-2}\boldsymbol{I\Phi} + \boldsymbol{S}_0^{-1} \tag{9.49a} \\ \Longleftrightarrow&\boldsymbol{S}_N = (\sigma^{-2}\boldsymbol{\Phi}^\top\boldsymbol{\Phi} + \boldsymbol{S}_0^{-1})^{-1} \tag{9.49b} \end{align*}\]와
\[\begin{align*} &\boldsymbol{m}_N^\top\boldsymbol{S}_N^{-1} = (\sigma^{-2}\boldsymbol{\Phi}^\top\boldsymbol{y} + \boldsymbol{S}_0^{-1}\boldsymbol{m}_0)^\top \tag{9.50a} \\ \Longleftrightarrow&\boldsymbol{m}_N = \boldsymbol{S}_N(\sigma^{-2}\boldsymbol{\Phi}^\top\boldsymbol{y} + \boldsymbol{S}_0^{-1}\boldsymbol{m}_0) \tag{9.50b} \end{align*}\]입니다.
(9.47b) 의 지수항에 있는 항들은 아래를 만족하는 (9.51) 형태라는 것을 알 수 있습니다.
\[\begin{align*} \boldsymbol{A}&:=\sigma^{-2}\boldsymbol{\Phi}^\top\boldsymbol{\Phi} + \boldsymbol{S}_0^{-1} \tag{9.55} \\ \boldsymbol{a}&:=\sigma^{-2}\boldsymbol{\Phi}^\top\boldsymbol{y} + \boldsymbol{S}_0^{-1}\boldsymbol{m}_0 \tag{9.56} \end{align*}\]Posterior Predictions
(9.37)에서 파라미터의 사전 확률 $p(\boldsymbol{\theta})$ 를 사용하여 test input $\boldsymbol{x}_{\ast}$ 에서 $y_{\ast}$ 의 예측 분포를 계산했습니다. 원칙적으로, conjugate model에서 사전 확률과 사후 확률이 모두 가우시안인 것을 감안할 때, 파라미터의 사후 확률 $p(\boldsymbol{\theta}|\mathcal{X,Y})$ 로 예측하는 것은 근본적으로 다르지 않습니다. 그러므로, 9.3.2장에서의 동일한 추론을 따르면, 우리는 아래의 (posterior) predictive distribution를 얻습니다.
\[\begin{align*} p(y_{\ast}|\mathcal{X, Y},\boldsymbol{x}_{\ast}) &= \int p(y_{\ast}|\boldsymbol{x}_{\ast},\boldsymbol{\theta})p(\boldsymbol{\theta}|\mathcal{X, Y})\mathrm{d}\boldsymbol{\theta} \tag{9.57a} \\ &= \int\mathcal{N}(y_{\ast}|\phi^\top(\boldsymbol{x}_{\ast}), \sigma^2)\mathcal{N}(\boldsymbol{\theta}|\boldsymbol{m}_N, \boldsymbol{S}_N) \tag{9.57b} \\ &= \mathcal{N}(y_{\ast}|\phi^\top(\boldsymbol{x}_{\ast})\boldsymbol{m}_N, \phi^\top(\boldsymbol{x}_{\ast})\boldsymbol{S}_N\phi(\boldsymbol{x}_{\ast})+\sigma^2) \tag{9.57c} \end{align*}\]$\phi^\top(\boldsymbol{x}_{\ast})\boldsymbol{S}_N\phi(\boldsymbol{x}_{\ast})$ 항은 파라미터 $\boldsymbol{\theta}$ 와 관련된 사후 불확실성을 반영합니다. $\boldsymbol{S}_N$ 은 $\boldsymbol{\Phi}$ 를 통한 training inputs에 따라 달라집니다. 예측된 평균 $\phi^\top(\boldsymbol{x}_{\ast})\boldsymbol{m}_N$ 은 MAP estimate $\boldsymbol{\theta}_{\text{MAP}}$ 로 만들어진 예측과 동일합니다.
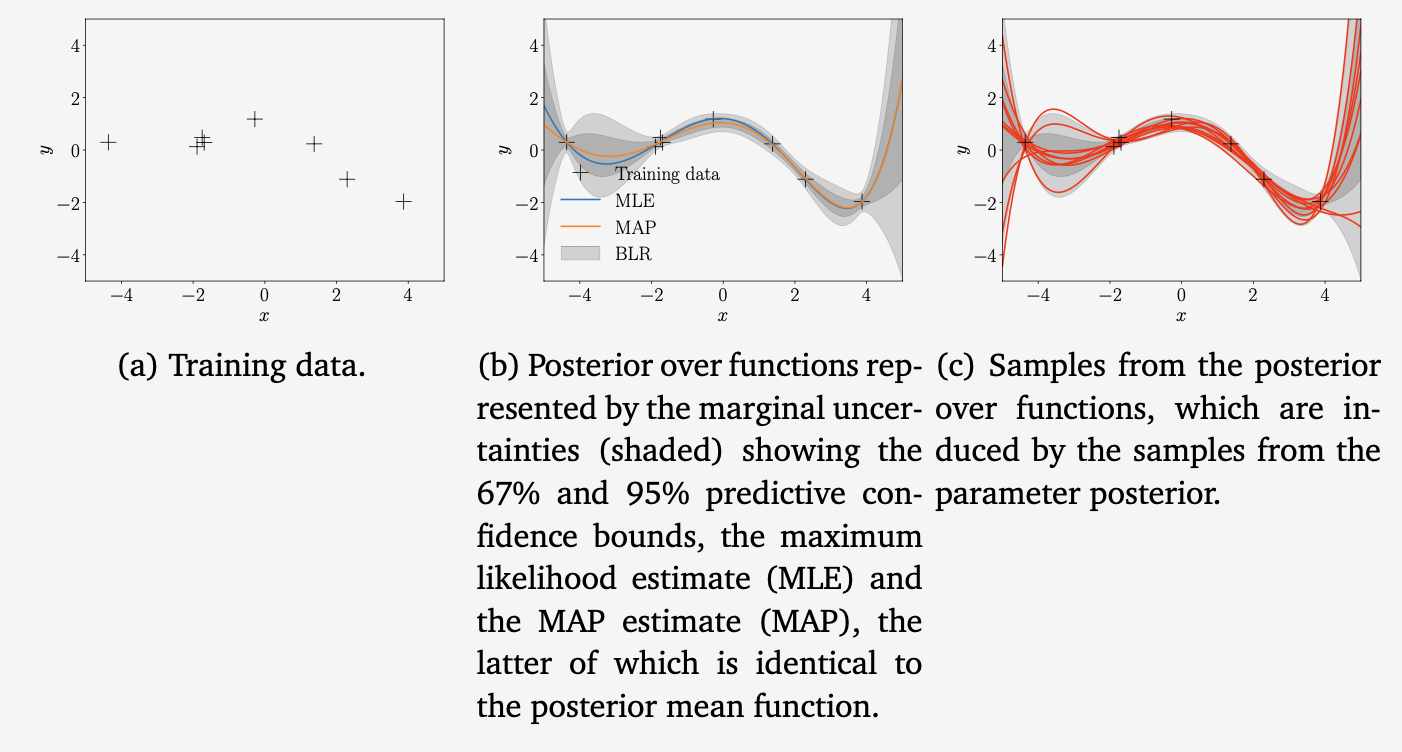
Example 9.8 (Posterior over Functions)
5차 다항식을 사용하여 Bayesian linear regression 문제를 다시 살펴보겠습니다. 파라미터의 사전 확률은 $p(\boldsymbol{\theta})=\mathcal{N}(\boldsymbol{0},\frac{1}{4}\boldsymbol{I})$ 로 선택합니다.
위 그림은 파라미터 사전 확률과 이 사전 확률로부터의 샘플 함수로 유도된 함수에 대한 사전 확률을 시각화합니다.
위 그림은 Bayesian linear regression을 통해 얻은 함수에 대한 사후 확률을 보여줍니다. (a)에서 training dataset을 보여주고, (b)에서 MLE와 MAP로 얻은 함수를 포함하여 함수에 대한 사후 확률을 보여줍니다. MAP를 사용하여 얻은 함수는 Bayesian linear regression setting에서 사후 확률의 평균 함수에 대응됩니다. (c)에서는 함수에 대한 사후 분포에서 함수들의 어떤 그럴듯한 realizations (samples) 를 보여줍니다.
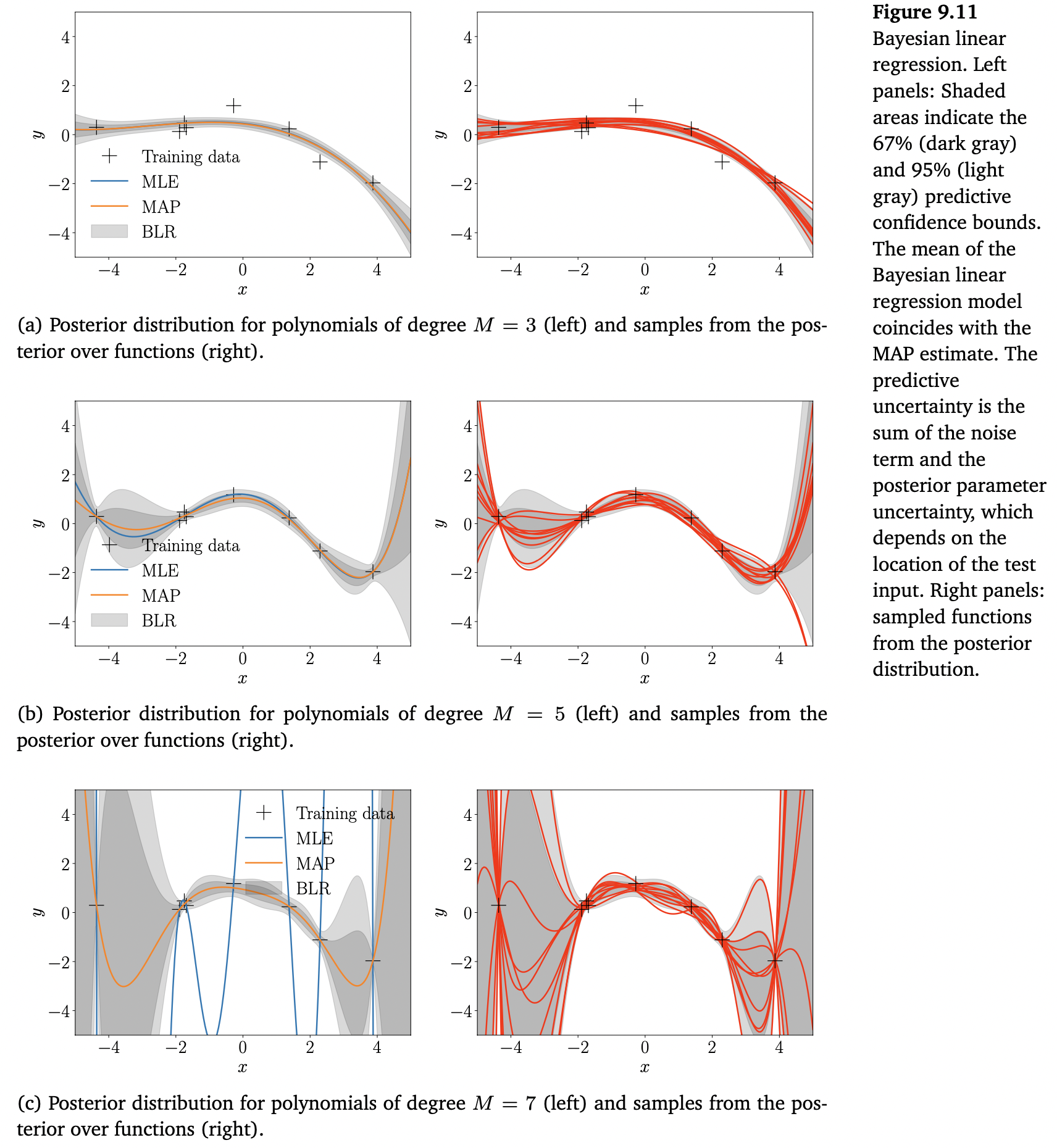
위의 Figure 9.11은 파라미터의 사후 분포에 의해 유도된 함수에 대한 사후 분포를 보여줍니다. 다른 다항식 차수 $M$ 에 대해, 왼쪽 패널은 ML function $\boldsymbol{\theta}^\top_{\text{ML}}\phi(\cdot)$ , $\boldsymbol{\theta}^\top_{\text{MAP}}\phi(\cdot)$ , 그리고 Bayesian linear regression으로 얻는 67%와 95%의 예측 신뢰범위(음영으로 표시)를 보여줍니다.
오른쪽 패널은 함수에 대한 사후 분포로부터의 샘플들을 보여줍니다. 여기서 파라미터 posterior로부터 파라미터 $\boldsymbol{\theta}_i$ 를 샘플링하고 함수 $\phi^\top(\boldsymbol{x}_{\ast})\boldsymbol{\theta}_i$ 를 계산합니다. 이는 함수에 대한 사후 분포에서 함수의 single realization 입니다. 2차 다항식에 대해, 파라미터 사후 분포가 많이 변하는 것을 허용하지 않습니다. 샘플링된 함수는 거의 동일합니다. 더 많은 파라미터를 추가, 즉, 고차 다항식을 통해 모델을 더 유연하게 만들 때, 이러한 파라미터들은 사후 분포에 의해 충분히 제한되지 않으며, 샘플링된 함수는 쉽게 시각적으로 분리될 수 있습니다. 또한, 왼쪽에 있는 패널들을 통해 불확실성이 어떻게 증가하는지 알 수 있습니다 (특히 경계에서).
비록 7차 다항식에 대해 MAP estimate는 합리적으로 피팅되었다고 판단하지만, Bayesian linear regression 모델은 사후 불확실성이 크다고 추가로 말해주고 있습니다. 이 정보는 잘못된 결정이 큰 문제를 일으킬 수 있는 의사 결정 시스템에서 이러한 예측을 사용할 때 중요할 수 있습니다.
Computing the Marginal Likelihood
8.6.2장에서, bayesian model selection에서 marginal likelihood의 중요성에 대해 강조했습니다. 이어서 파라미터의 conjugate Gaussian prior를 가진 Bayesian linear regression에 대한 marginal likelihood를 계산합니다.
먼저, $n = 1,\dotsc,N$ 에 대해 다음의 생성 프로세스를 따른다고 간주합니다.
\[\begin{align*} &\boldsymbol{\theta}\sim\mathcal{N}(\boldsymbol{m}_0,\boldsymbol{S}_0) \tag{9.60a} \\ y_n|\boldsymbol{x}_n,&\boldsymbol{\theta}\sim\mathcal{N}(\boldsymbol{x}_n^\top\boldsymbol{\theta},\sigma^2) \tag{9.60b} \end{align*}\]Marginal likelihood는 아래와 같이 주어집니다.
\[\begin{align*} p(\mathcal{Y}|\mathcal{X}) &= \int p(\mathcal{Y}|\mathcal{X},\boldsymbol{\theta})p(\boldsymbol{\theta})\mathrm{d}\boldsymbol{\theta} \tag{9.61a} \\ &= \int \mathcal{N}(\boldsymbol{y}|\boldsymbol{X\theta}, \sigma^2\boldsymbol{I})\mathcal{N}(\boldsymbol{\theta}|\boldsymbol{m}_0,\boldsymbol{S}_0)\mathrm{d}\boldsymbol{\theta} \tag{9.61b} \end{align*}\]Margianl likelihood는 2스텝으로 계산합니다. 먼저, marginal likelihood가 Gaussian이라는 것을 보입니다 ($\boldsymbol{y}$ 의 분포). 그리고, 이 가우시안의 평균과 공분산을 계산합니다.
- The marginal likelihood is Gaussian: 6.5.2장으로부터 우리는 (1) 두 가우시안 확률 변수의 곱이 (unnormalized) 가우시안 분포라는 것을 봤고, (2) 가우시안 확률 변수의 linear transformation 또한 가우시안 분포라는 것을 봤습니다. (9.61b)에서, $\boldsymbol{\mu, \Sigma}$ 에 대해 $\mathcal{N}(\boldsymbol{y}|\boldsymbol{X\theta},\sigma^2\boldsymbol{I})$ 를 $\mathcal{N}(\boldsymbol{\theta}|\boldsymbol{\mu},\boldsymbol{\Sigma})$ 로 가져오려면 linear transformation이 필요합니다. 이것이 완료되면, 적분은 closed-form으로 풀 수 있습니다. 결과는 두 가우시안의 곱의 normalizing constant 입니다. Normalizing constant는 그자체로 가우시안 형태를 갖습니다.
-
Mean and covariance. 확률 변수의 affine transformations의 평균 및 공분산에 대한 표준 결과를 활용하여 marginal likelihood의 평균과 공분산 행렬을 계산합니다 (6.4.4장 참조). Marginal likelihood의 평균은 다음과 같이 계산됩니다.
\[\mathbb{E}[\mathcal{Y|X}] = \mathbb{E}_{\boldsymbol{\theta},\boldsymbol{\epsilon}}[\boldsymbol{X\theta}+\boldsymbol{\epsilon}] = \boldsymbol{X}\mathbb{E}_{\boldsymbol{\theta}}[\boldsymbol{\theta}] = \boldsymbol{Xm}_0 \tag{9.62}\]여기서 $\boldsymbol{\epsilon}\sim\mathcal{N}(\boldsymbol{0},\sigma^2\boldsymbol{I})$ 는 i.i.d. 확률 변수의 벡터라는 것에 주의합니다. 공분산 행렬은 아래와 같이 주어집니다.
\[\begin{align*} \text{Cov}[\mathcal{Y|X}] &= \text{Cov}_{\boldsymbol{\theta},\boldsymbol{\epsilon}}[\boldsymbol{X\theta} + \boldsymbol{\epsilon}] = \text{Cov}_{\boldsymbol{\theta}}[\boldsymbol{X\theta}] + \sigma^2\boldsymbol{I} \tag{9.63a} \\ &= \boldsymbol{X}\text{Cov}_{\boldsymbol{\theta}}[\boldsymbol{\theta}]\boldsymbol{X}^\top + \sigma^2\boldsymbol{I} = \boldsymbol{XS}_0\boldsymbol{X}^\top + \sigma^2\boldsymbol{I} \tag{9.63b} \end{align*}\]
그러므로, marginal likelihood는 아래와 같습니다.
\[\begin{align*} p(\mathcal{Y|X}) = &(2\pi)^{-\frac{N}{2}}\det(\boldsymbol{XS}_0\boldsymbol{X}^\top + \sigma^2\boldsymbol{I})^{-\frac{1}{2}} \\ &\cdot\exp\left(-\frac{1}{2}(\boldsymbol{y}-\boldsymbol{Xm}_0)^\top(\boldsymbol{XS}_0\boldsymbol{X}^\top + \sigma^2\boldsymbol{I})^{-1}(\boldsymbol{y}-\boldsymbol{Xm}_0)\right) \tag{9.64a} \\ =&\mathcal{N}(\boldsymbol{y}|\boldsymbol{Xm}_0, \boldsymbol{XS}_0\boldsymbol{X}^\top + \sigma^2\boldsymbol{I}) \tag{9.64b} \end{align*}\]