Parameter Estimation
\[\begin{align*} &p(y|\boldsymbol{x},\boldsymbol{\theta}) = \mathcal{N}(y|\boldsymbol{x}^\top\boldsymbol{\theta},\sigma^2) \tag{9.3} \\ \Longleftrightarrow &y = \boldsymbol{x}^\top\boldsymbol{\theta} + \epsilon, \quad \epsilon\sim\mathcal{N}(0,\sigma^2) \tag{9.4} \end{align*}\](9.4)의 linear regression setting과 N개의 inputs $\boldsymbol{x}_n\in\mathbb{R}^D$ 와 대응되는 observations/targets $y_n\in\mathbb{R}$ 을 포함하는 training set $\mathcal{D} := {(\boldsymbol{x}_1,y_1),\dotsc,(\boldsymbol{x}_N,y_N)}$ 이 주어졌다고 가정하겠습니다. 이에 대응되는 graphical model은 아래의 그림과 같습니다.
$y_i$ 와 $y_j$ 는 각각 주어진 inputs $\boldsymbol{x}_1,\boldsymbol{x}_2$ 에 대해 조건부 독립이므로, likelihood는 다음과 같이 분해될 수 있습니다.
\[\begin{align*} p(\mathcal{Y}|\mathcal{X},\boldsymbol{\theta}) &= p(y_1,\dotsc,y_N|\boldsymbol{x}_1,\dotsc,\boldsymbol{x}_N,\boldsymbol{\theta}) \tag{9.5a} \\ & = \prod_{n=1}^N p(y_n|\boldsymbol{x}_n,\boldsymbol{\theta}) = \prod_{n=1}^N\mathcal{N}(y_n|\boldsymbol{x}^\top_n\boldsymbol{\theta},\sigma^2) \tag{9.5b} \end{align*}\]여기서 $\mathcal{X}:={\boldsymbol{x}_1,\dotsc,\boldsymbol{x}_N}$ 과 $\mathcal{Y}:={y_1,\dotsc,y_N}$ 을 training inputs 집합과 대응되는 targets 으로 정의합니다. Likelihood와 그 factors $p(y_n|\boldsymbol{x}_n,\boldsymbol{\theta})$ 는 noise distribution 이므로 가우시안입니다.
Maximum Likelihood Estimation
원하는 파라미터 $\boldsymbol{\theta}_{\text{ML}}$ 을 찾는데 널리 사용되는 접근 방식은 maximum likelihood estimation (MLE) 입니다. 여기서 파라미터 $\boldsymbol{\theta}_{\text{ML}}$ 은 (9.5b)의 likehood 를 최대화합니다. 직관적으로 likelihood를 최대화한다는 것은 주어진 모델 파라미터에서 training data의 예측 분포를 최대화한다는 것입니다. 여기서 maximum likelihood parameters는 다음의 식을 통해서 얻습니다.
\[\boldsymbol{\theta}_{\text{ML}} = \arg\max_{\boldsymbol{\theta}}p(\mathcal{Y}|\mathcal{X},\boldsymbol{\theta}) \tag{9.7}\]Likelihood를 최대화하는 원하는 파라미터 $\boldsymbol{\theta}_{\text{ML}}$ 을 찾기 위해서, 전형적으로 gradient ascent를 수행합니다 (or gradient descent on the negative likelihood). 그러나 우리가 고려하는 linear regression의 경우, closed-form solution이 존재하고, 반복적인 gradient descent가 불필요합니다. 실제로 likelihood를 직접 최대화하는 대신, likelihood function에 log-transformation을 적용하고 negative log-likelihood를 최소화합니다.
우리의 linear regression problem의 최적의 파라미터 $\boldsymbol{\theta}_{\text{ML}}$ 을 찾기 위해서, 아래의 negative log-likelihood를 최소화합니다.
\[-\log p(\mathcal{Y}|\mathcal{X},\boldsymbol{\theta}) = -\log \prod_{n=1}^Np(y_n|\boldsymbol{x}_n,\boldsymbol{\theta}) = -\sum_{n=1}^N\log p(y_n|\boldsymbol{x}_n,\boldsymbol{\theta}) \tag{9.8}\](9.4)의 linear regression model에서, likelihood는 가우시안이므로 다음과 같습니다.
\[\log p(y_n|\boldsymbol{x}_n,\boldsymbol{\theta}) = -\frac{1}{2\sigma^2}(y_n-\boldsymbol{x}_n^\top\boldsymbol{\theta})^2 + \text{const} \tag{9.9}\]위 식에서 상수는 $\boldsymbol{\theta}$ 에 모든 독립적인 항들을 포함합니다. 식 (9.9)를 이용하여 negative log-likelihood (9.8)을 통해 (상수항을 모두 무시하여), 다음의 식을 얻습니다.
\[\begin{align*} \mathcal{L}(\boldsymbol{\theta}) := &\frac{1}{2\sigma^2}\sum_{n=1}^N (y_n-\boldsymbol{x}^\top_n\boldsymbol{\theta})^2 \tag{9.10a} \\ = &\frac{1}{2\sigma^2}(\boldsymbol{y}-\boldsymbol{X\theta})^\top(\boldsymbol{y}-\boldsymbol{X\theta}) = \frac{1}{2\sigma^2}\|\boldsymbol{y}-\boldsymbol{X\theta}\|^2 \tag{9.10b} \end{align*}\]여기서 design matrix $\boldsymbol{X} := [\boldsymbol{x}_1,\dotsc,\boldsymbol{x}_N]^\top\in\mathbb{R}^{N\times D}$ 를 training inputs로 정의하고 $\boldsymbol{y}:=[y_1,\dotsc,y_n]^\top\in\mathbb{R}^N$ 을 tarining targets의 벡터로 정의했습니다. 식 (9.10b) 에서 우리는 관측값 $y_n$ 과 대응되는 모델 예측값 $\boldsymbol{x}_n^\top\boldsymbol{\theta}$ 의 squared errors의 합이 $\boldsymbol{y}$ 와 $\boldsymbol{X\theta}$ 간의 squared distance와 같다는 사실을 이용했습니다.
(9.10b) 식을 통해 최적화해야 하는 negative log-likelihood function을 구체적인 형태를 구성했습니다. 이 식인 $\boldsymbol{\theta}$ 의 2차식이라는 것을 볼 수 있습니다. 이는 negative log-likelihood $\mathcal{L}$ 을 최소화하여 유일한 global solution $\boldsymbol{\theta}_{\text{ML}}$ 을 찾을 수 있다는 것을 의미합니다. Global optima는 $\mathcal{L}$ 의 gradient를 계산하여 이를 $\boldsymbol{0}$ 과 같다고 설정한 뒤 $\boldsymbol{\theta}$ 에 대해 해를 구하면 됩니다.
5장에서 살펴본 내용을 활용하여, 파라미터에 대한 $\mathcal{L}$ 의 gradient는 다음과 같이 계산됩니다.
\[\begin{align*} \frac{\mathrm{d}\mathcal{L}}{\mathrm{d}\boldsymbol{\theta}} &= \frac{\mathrm{d}}{\mathrm{d}\boldsymbol{\theta}}\left( \frac{1}{2\sigma^2}(\boldsymbol{y} - \boldsymbol{X\theta})^\top(\boldsymbol{y}-\boldsymbol{X\theta}) \right) \tag{9.11a} \\ &= \frac{1}{2\sigma^2}\frac{\mathrm{d}}{\mathrm{d}\boldsymbol{\theta}}\left( \boldsymbol{y}^\top\boldsymbol{y} - 2\boldsymbol{y}^\top\boldsymbol{X\theta} + \boldsymbol{\theta}^\top\boldsymbol{X}^\top\boldsymbol{X\theta} \right) \tag{9.11b} \\ &= \frac{1}{\sigma^2}(-\boldsymbol{y}^\top\boldsymbol{X}+\boldsymbol{\theta}^\top\boldsymbol{X}^\top\boldsymbol{X}) \in \mathbb{R}^{1\times D} \tag{9.11c} \end{align*}\]Maximum likelihood estimator $\boldsymbol{\theta}_{\text{ML}}$ 은 $\frac{\mathrm{d}\mathcal{L}}{\mathrm{d}\boldsymbol{\theta}}=\boldsymbol{0}^\top$ 을 다음과 같이 풀면 됩니다.
\[\begin{align*} \frac{\mathrm{d}\mathcal{L}}{\mathrm{d}\boldsymbol{\theta}}=\boldsymbol{0}^\top &\overset{(9.11c)}\Longleftrightarrow \boldsymbol{\theta}_{\text{ML}}^\top\boldsymbol{X}^\top\boldsymbol{X} = \boldsymbol{y}^\top\boldsymbol{X} \tag{9.12a} \\ &\Longleftrightarrow \boldsymbol{\theta}_{\text{ML}}^\top = \boldsymbol{y}^\top\boldsymbol{X}(\boldsymbol{X}^\top\boldsymbol{X})^{-1} \tag{9.12b} \\ &\Longleftrightarrow \boldsymbol{\theta}_{\text{ML}} = (\boldsymbol{X}^\top\boldsymbol{X})^{-1}\boldsymbol{X}^\top\boldsymbol{y} \tag{9.12c} \end{align*}\]위의 첫 번째 방정식에서 $\boldsymbol{X}^\top\boldsymbol{X}$ 는 $\text{rk}(\boldsymbol{X}) = D$ 라면 positive definite 이므로 $(\boldsymbol{X}^\top\boldsymbol{X})^{-1}$ 를 곱할 수 있습니다.
Example 9.2 (Fitting Lines)
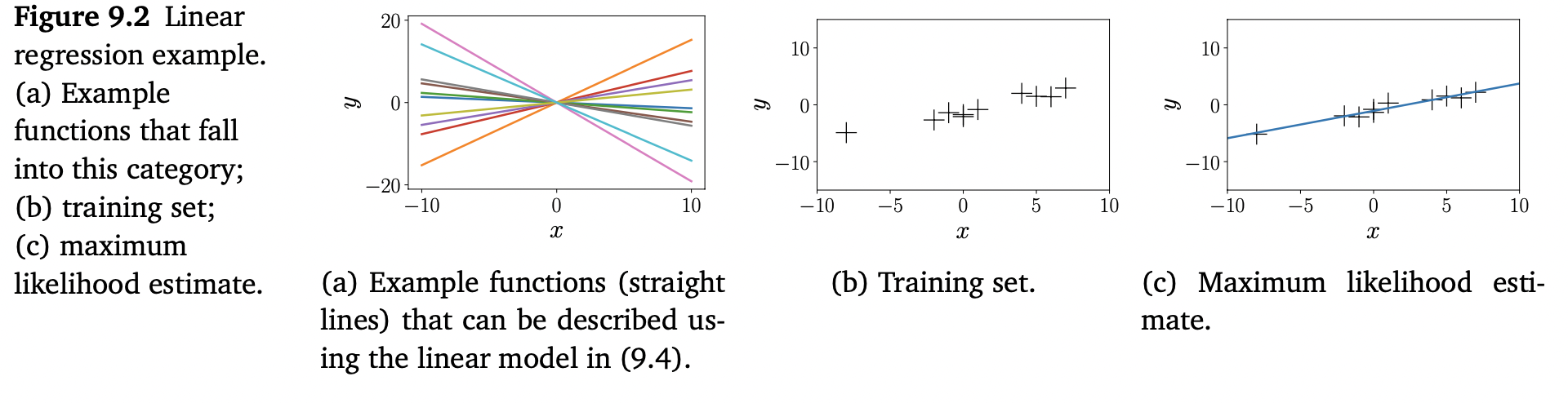
위의 Figure 9.2를 살펴봅시다. 여기서 우리는 직선 $f(x) = \theta x$ 를 맞추는 것이 목적이며, 여기서 $\theta$ 는 unknown slope 입니다. 이 모델 클래스(직선)의 함수 예시는 Figure 9.2(b)에서 보여줍니다. Figure 9.2(b) 에서 보여주는 dataset에 대해, 우리는 (9.12c) 식을 사용하여 slope parameter $\theta$ 의 MLE를 찾고, Figure 9.2(c)의 maximum likelihood linear function을 얻습니다.
Maximum Likelihood Estimation with Features
지금까지는 (9.4)에서 본 것과 같이 linear regression setting을 고려했습니다. 이를 통해 MLE를 사용하여 데이터에 직선을 맞출 수 있었습니다. 그러나, 더 관심있는 데이터를 피팅할 때에 직선으로 충분히 표현되지 않을 수 있습니다. 다행히 linear regression은 linear regression framework 내에서 nonlinear function을 피팅할 수 있는 방법을 제공합니다. “Linear regression”이 오직 “linear in the parameters”를 지칭하기 때문에, inputs $\boldsymbol{x}$ 에 대한 임의의 nonlinear transformation $\phi(\boldsymbol{x})$ 를 수행한 뒤, 이 변환의 요소들을 선형으로 결합합니다. 이에 대응되는 linear regression 모델은 다음과 같습니다.
\[\begin{align*} &p(y|\boldsymbol{x},\boldsymbol{\theta}) = \mathcal{N}(y|\phi^\top(\boldsymbol{x})\boldsymbol{\theta}, \sigma^2) \\ \Longleftrightarrow &y = \phi^\top(\boldsymbol{x})\boldsymbol{\theta} + \epsilon = \sum_{k=0}^{K-1}\theta_k \phi_k(\boldsymbol{x}) + \epsilon \tag{9.13} \end{align*}\]여기서 $\phi:\mathbb{R}^D\rightarrow\mathbb{R}^K$ 는 inputs $\boldsymbol{x}$ 의 (nonlinear) transformation이고, $\phi_k:\mathbb{R}^D\rightarrow\mathbb{R}$ 은 feature vector $\phi$ 의 k번째 component 입니다. 여기서 모델 파라미터 $\boldsymbol{\theta}$ 는 여전히 선형으로 나타납니다.
Example 9.3 (Polynomial Regression)
Regression problem $y=\phi^\top(x)\boldsymbol{\theta} + \epsilon$ ,$x\in\mathbb{R}, \boldsymbol{\theta}\in\mathbb{R}^K$ 를 살펴봅시다. 이러한 문맥에서 주로 사용되는 변환은 아래와 같습니다.
\[\phi(x) = \begin{bmatrix}\phi_0(x)\\\phi_1(x)\\\vdots\\\phi_{K-1}(x)\end{bmatrix} = \begin{bmatrix}1\\x\\x^2\\x^3\\\vdots\\x^{K-1}\end{bmatrix} \tag{9.14}\]이는 기존의 1차원 input space를 모든 단항식 $x^k, k=0,\dotsc,K-1$ 을 포함하는 K-차원의 feature space로 변환한다는 것을 의미합니다. 이러한 features를 가지고, linear regression 프레임워크 내에서 $\leq K-1$ 차 다항식을 모델링할 수 있습니다. $K-1$ 차 다항식은 아래와 같습니다.
\[f(x) = \sum_{k=0}^{K-1}\theta_k x^k = \phi^\top(x)\boldsymbol{\theta} \tag{9.15}\]$\phi$ 는 (9.14)에서 정의되었고, $\boldsymbol{\theta} = [\theta_0,\dotsc, \theta_{K-1}]^\top\in\mathbb{R}^K$ 는 linear parameters $\theta_k$ 를 포함합니다.
이제 (9.13)의 linear regression 모델에서 파라미터 $\boldsymbol{\theta}$ 의 MLE를 살펴보겠습니다. Training inputs $\boldsymbol{x}_n\in\mathbb{R}^D$ 와 targets $y_n\in\mathbb{R}$ 이 있고, feature matrix (design matrix) 를 다음과 같이 정의합니다.
\[\boldsymbol{\Phi} := \begin{bmatrix}\phi^\top(\boldsymbol{x}_1)\\\vdots\\\phi^\top(\boldsymbol{x}_N)\end{bmatrix} = \begin{bmatrix}\phi_0(\boldsymbol{x}_1)&\cdots&\phi_{K-1}(\boldsymbol{x}_1)\\\phi_0(\boldsymbol{x}_2)&\cdots&\phi_{K-1}(\boldsymbol{x}_2)\\\vdots&&\vdots\\\phi_0(\boldsymbol{x}_N)&\cdots&\phi_{K-1}(\boldsymbol{x}_K)\end{bmatrix} \in\mathbb{R}^{N\times K} \tag{9.16}\]여기서 $\Phi_{ij} = \phi_j(\boldsymbol{x}_i)$ 이고, $\phi_j : \mathbb{R}^D\rightarrow\mathbb{R}$ 입니다.
Example 9.4 (Feature Matrix for Second-order Polynomials)
2차 다항식과 N개의 training points $x_n\in\mathbb{R}, n=1,\dotsc,N$ 에 대한 feature matrix는 아래와 같습니다.
\[\boldsymbol{\Phi} = \begin{bmatrix}1&x_1&x_1^2\\1&x_2&x_2^2\\\vdots&\vdots&\vdots\\1&x_N&x_N^2\end{bmatrix} \tag{9.17}\]
(9.16)에서 정의된 feature matrix $\boldsymbol{\Phi}$ 를 포함하는, linear regression model (9.13)의 negative log-likelihood는 다음과 같습니다.
\[-log p(\mathcal{Y}|\mathcal{X},\boldsymbol{\theta}) = \frac{1}{2\sigma^2}(\boldsymbol{y}-\boldsymbol{\Phi\theta})^\top(\boldsymbol{y}-\boldsymbol{\Phi\theta}) + \text{const} \tag{9.18}\](9.18)과 (9.10b)(feature-free model)의 negative log-likelihood을 비교하면, $\boldsymbol{X}$ 를 $\boldsymbol{\Phi}$ 로 대체해야한다는 것을 알 수 있습니다. $\boldsymbol{X}$ 와 $\boldsymbol{\Phi}$ 가 모두 파라미터 $\boldsymbol{\theta}$ 에 독립이기 때문에, 바로 maximum likelihood estimate 를 찾을 수 있습니다.
\[\boldsymbol{\theta}_{\text{ML}} = (\boldsymbol{\Phi}^\top\boldsymbol{\Phi})^{-1}\boldsymbol{\Phi}^\top\boldsymbol{y} \tag{9.19}\]Example 9.5 (Maximum Likelihood Polynomial Fit)
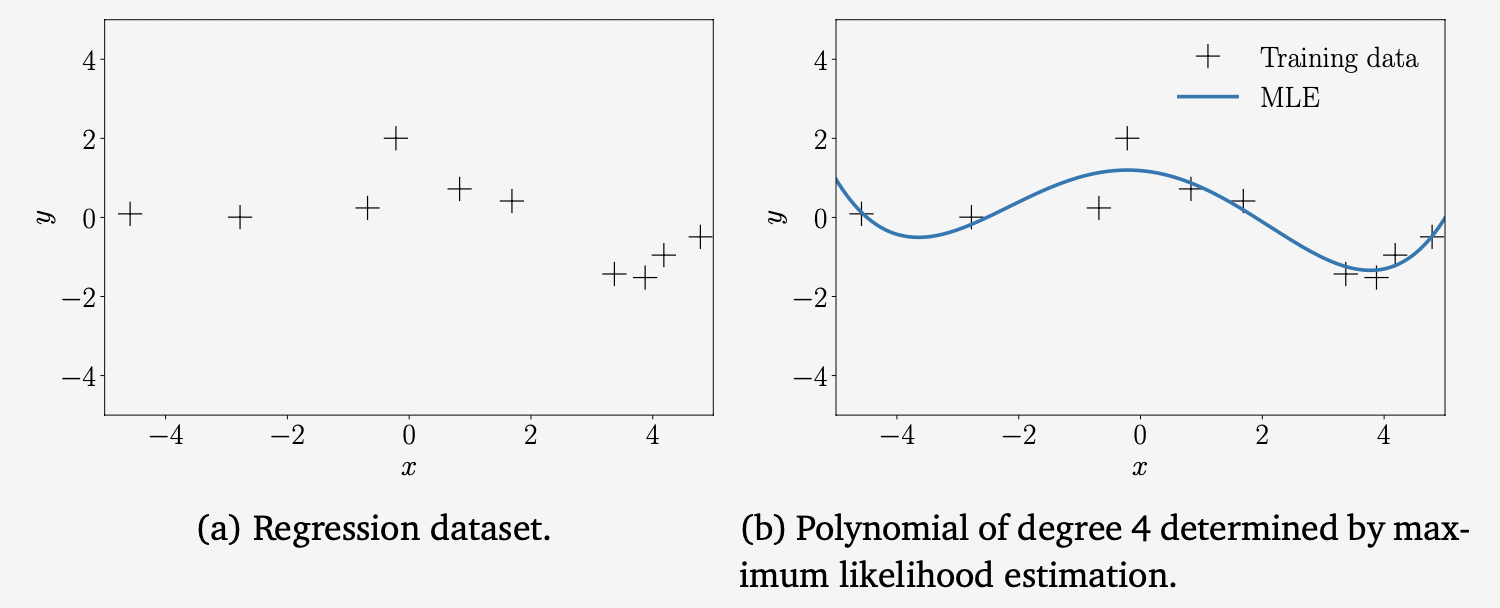
Figure 9.4(a)의 dataset을 살펴보겠습니다. Dataset은 $N=10$ 인 $(x_n,y_n)$ 쌍으로 구성되어 있고, $x_n\sim\mathcal{U}[-5,5]$ , $y_n=-\sin(x_n/5) + \cos(x_n) + \epsilon$ 이며, 여기서 $\epsilon\sim\mathcal{N}(0,0.2^2)$ 입니다.
MLE를 사용하여 4차 다항식을 피팅하는데, 여기서 파라미터 $\boldsymbol{\theta}_{\text{ML}}$ 은 (9.19)에서 주어집니다. MLE는 각 test location $x_{\ast}$ 에서의 함수 값 $\phi^\top(x_{\ast})\boldsymbol{\theta}_{\text{ML}}$ 을 출력합니다. 그 결과는 위의 Figure 9.4(b)에서 볼 수 있습니다.
Estimating the Noise Variance
지금까지 노이즈의 분산 $\sigma^2$ 는 알고 있다고 가정했습니다. 그러나, MLE를 사용하여 노이즈 분산에 대한 maximum likelihood estimator $\sigma_{\text{ML}}^2$ 를 얻을 수 있습니다. 이를 위해서는 다음의 표준 절차(standard procedure)를 따라야 합니다: log-likelihood를 쓰고, $\sigma^2>0$ 에 대한 미분을 계산합니다. 그리고 이를 0과 같다고 두고 문제를 풀면 됩니다. Log-likelihood는 다음과 같이 주어집니다.
\[\begin{align*} \log &p(\mathcal{Y}|\mathcal{X},\boldsymbol{\theta},\sigma^2) = \sum_{n=1}^N \log\mathcal{N}(y_n|\phi^\top(\boldsymbol{x}_n)\boldsymbol{\theta}, \sigma^2) \tag{9.20a} \\ &= \sum_{n=1}^N\left( -\frac{1}{2}\log(2\pi) - \frac{1}{2}\log\sigma^2 - \frac{1}{2\sigma^2}(y_n-\phi^\top(\boldsymbol{x}_n)\boldsymbol{\theta})^2 \right) \tag{9.20b} \\ &= -\frac{N}{2}\log\sigma^2 - \frac{1}{2\sigma^2}\underbrace{\sum_{n=1}^N(y_n-\phi^\top(\boldsymbol{x}_n)\boldsymbol{\theta})^2}_{=:s} + \text{const} \tag{9.20c} \end{align*}\]$\sigma^2$ 에 대한 log-likelihood의 편미분은 아래와 같고,
\[\begin{align*} &\frac{\partial\log p(\mathcal{Y}|\mathcal{X},\boldsymbol{\theta},\sigma^2)}{\partial\sigma^2} = -\frac{N}{2\sigma^2}+\frac{1}{2\sigma^4}s = 0 \tag{9.21a} \\ \Longleftrightarrow &\frac{N}{2\sigma^2} = \frac{s}{2\sigma^4} \tag{9.21b} \end{align*}\]따라서, 다음과 같습니다.
\[\sigma^2_{\text{ML}} = \frac{s}{N} = \frac{1}{N}\sum_{n=1}^N(y_n - \phi^\top(\boldsymbol{x}_n)\boldsymbol{\theta})^2 \tag{9.22}\]그러므로 noise variacne의 MLE는 noise-free인 함수값 $\phi^\top(\boldsymbol{x}_n)\boldsymbol{\theta}$ 와 input location $\boldsymbol{x}_n$ 에 대응되는 noisy observations $y_n$ 간의 squared distances의 empirical mean 입니다.
Overfitting in Linear Regression
지금까지 linear models(e.g., polynomials)에 데이터를 피팅하기 위해 MLE를 어떻게 사용하는지 살펴봤습니다. 모델의 quality는 발생하는 error/loss를 계산하여 평가할 수 있습니다. 한 가지 방법은 maximum likelihood estimator를 결정하기 위해 최소화한 negative log-likielihood (9.10b) 를 계산하는 것입니다. 또는, noise parameter $\sigma^2$ 가 free model parameter가 아니라는 점을 감안하여, $1/\sigma^2$ 를 무시하고, 결과적으로 squared-error-loss function $\|\boldsymbol{y}-\boldsymbol{\Phi\theta}\|^2$ 를 사용할 수 있습니다. 이 squared loss를 사용하는 대신, 보통 아래의 root mean square error (RMSE) 를 사용합니다.
\[\sqrt{\frac{1}{N}\|\boldsymbol{y}-\boldsymbol{\Phi\theta}\|^2} = \sqrt{\frac{1}{N}\sum_{n=1}(y_n - \phi^\top(\boldsymbol{x}_n)\boldsymbol{\theta})^2} \tag{9.23}\]이를 사용하면 (a) 다른 크기를 가진 datasets의 error를 비교할 수 있고, (b) 관측된 함수값 $y_n$ 과 동일한 scale과 units을 가지게 됩니다. 예를 들어, post-codes($\boldsymbol{x}$ 가 위도 경도로 주어짐)를 house prices ($y$ -values 는 EUR)로 매핑하는 모델을 피팅할 때, RMSE 또한 EUR로 측정됩니다. 반면 squared error 단위는 EUR$^2$ 입니다. 만약 original negative log-likelihood (9.10b)의 factor $\sigma^2$ 를 포함하도록 한다면, 단위가 없는 objective가 되고, 즉, 우리의 objective는 더이상 EUR도, EUR$^2$ 도 아닙니다.
Model selection을 위해 RMSE(or negative log-likelihood)를 사용하여 objective를 최소화하는 다항식 차수 $M$ 을 찾아서 다항식의 최고의 차수를 결정할 수 있습니다. 주어진 다항식 차수가 자연수라고 가정한다면, brute-force search를 사용하여 모든 합리적인 $M$ 의 값을 열거할 수 있습니다. N개의 training set의 경우, $0\leq M \leq N-1$ 을 테스트하는 것만으로도 충분합니다. $M<N$ 의 경우, maximum likelihood estimator는 유일합니다. $M\geq N$ 의 경우, 우리는 data point보다 더 많은 매개변수를 가지고 있으므로, underdetermined system of linear equations($\boldsymbol{\Phi}^\top\boldsymbol{\Phi}$ 가 invertible하지 않을 수 있음) 를 풀어야 하며, 따라서 무한히 많은 가능한 maximum likelihood estimators가 있습니다.
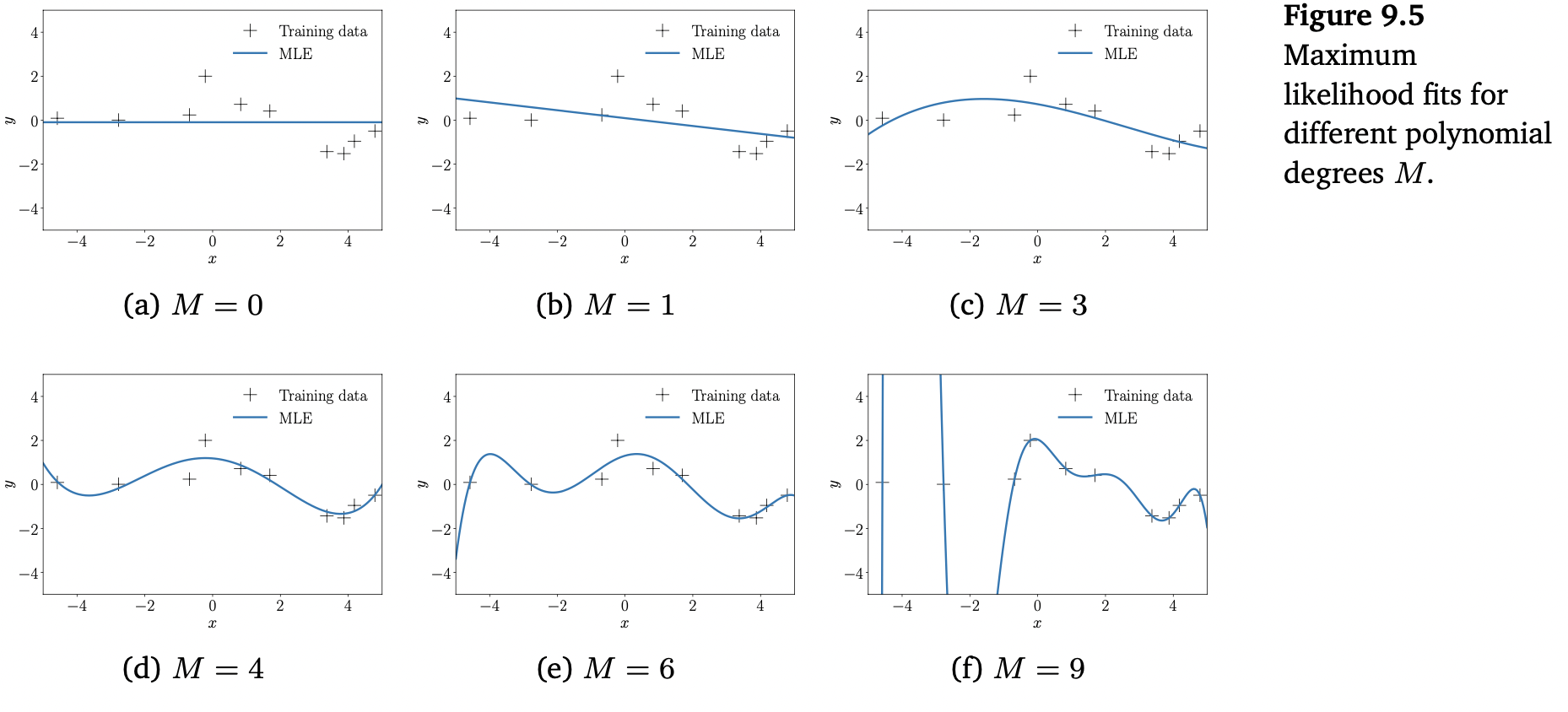
위의 Figure 9.5는 10개의 관측치를 가진 Figure 9.4(a)의 dataset에 대해 miximum likelihood로 결정된 다항식 피팅의 수를 보여줍니다. 낮은 차수($M=0$ or $M=1$)의 다항식은 데이터에 잘 맞지 않으므로 성능이 좋지 못합니다. $M=3,\dotsc,6$ 의 차수에는 데이터에 잘 적합해보이며, 부드럽게 데이터 간을 연결합니다. 더 높은 차수의 다항식으로 이동하면, 데이터에 더욱 잘 맞는 것을 볼 수 있습니다. $M=N-1=9$ 인 케이스를 보면, 해당 함수가 모든 data point를 통과하고 있습니다. 그러나, 이러한 고차 다항식은 매우 크게 진동하고 있으므로, 데이터를 생성한 원본 함수를 제대로 표현하지 못하며 결국 overfitting (과적합)이 발생합니다.
우리의 목표는 새로운 데이터에 대한 정확한 예측을 수행하여 good generalization을 달성해야 합니다. 생성된 training set에서 사용했던 것과 동일한 절차를 사용하여 생성된 200개의 data points로 구성된 별도의 test set을 사용하여 M차 다항식의 generalization 성능에 대한 정량적인 insight를 얻을 수 있습니다.
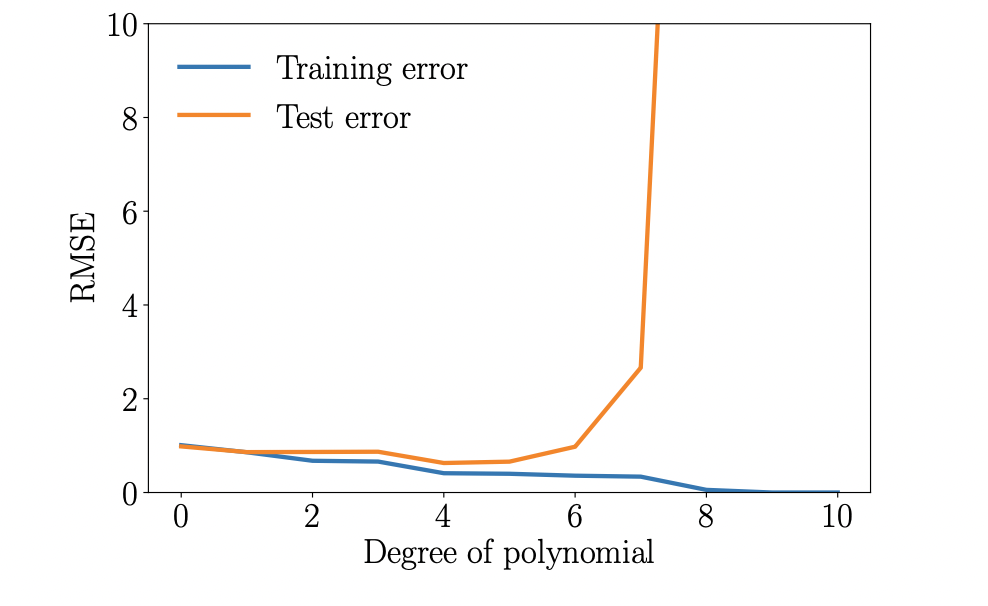
이제 대응되는 다항식의 generalization 속성의 정성적 측정인 test error를 살펴보면, 초기에는 test error가 감소한다는 것을 볼 수 있습니다. 위의 Figure 9.6의 주황색 선을 참조바랍니다. 4차 다항식의 경우, test error가 낮고 5차까지는 비교적 일정하게 유지됩니다. 그러나 6차 다항식부터 test error가 크게 증가하고 일반화 속성이 매우 안좋다는 것을 알 수 있습니다. Training error(파란색 곡선)는 다항식의 차수가 증가할 때 계속 감소합니다. 이 예시에서는 $M=4$ 차수의 다항식에서 최상의 generalization을 얻습니다.
Maximum A Posteriori Estimation
위의 예시에서 MLE가 과적합되는 경향이 있다는 것을 봤습니다. 과적합에 빠지면 종종 파라미터의 크기가 비교적 커진다는 것을 관찰하게 됩니다.
거대한 파라미터 값의 영향을 완화하기 위해, 파라미터의 사전 분포(prior distribution) $p(\boldsymbol{\theta})$ 를 사용할 수 있습니다. 사전 분포는 명시적으로 어떤 파라미터 값이 타당한지 인코딩합니다 (before having seen any data). 예를 들어, 단일 파라미터 $\theta$ 에 대한 Gaussian prior $p(\theta) = \mathcal{N}(0, 1)$ 는 파라미터 값이 $[-2,2]$ 구간에 있는 것으로 예상하도록 인코딩합니다. Dataset $\mathcal{X},\mathcal{Y}$ 를 사용하게 되면, likelihood를 최대화하는 대신 posterior distribution(사후 분포) $p(\boldsymbol{\theta}|\mathcal{X},\mathcal{Y})$ 를 최대화하는 파라미터를 찾습니다. 이러한 과정을 maximum a posteriori (MAP) estimation 이라고 부릅니다.
주어진 training data $\mathcal{X, Y}$ 에서 파라미터 $\boldsymbol{\theta}$ 에 대한 posterior는 베이즈 정리를 적용하여 얻을 수 있습니다.
\[p(\boldsymbol{\theta}|\mathcal{X, Y}) = \frac{p(\mathcal{Y}|\mathcal{X},\boldsymbol{\theta})p(\boldsymbol{\theta})}{p(\mathcal{Y}|\mathcal{X})} \tag{9.24}\]Posterior는 명시적으로 파라미터의 prior $p(\boldsymbol{\theta})$ 에 의존하기 때문에, prior는 posterior의 maximizer로 찾은 파라미터 값에 영향을 미칩니다. 이에 대해서는 이어서 조금 더 자세히 살펴보도록 하겠습니다. Posterior (9.24)를 최대화하는 파라미터 벡터 $\boldsymbol{\theta}_{\text{MAP}}$ 는 MAP estimate 입니다.
MAP 추정치를 찾기 위해서, MLE와 유사한 단계를 따릅니다. 먼저 log-transform으로 시작하여 log-posterior를 다음과 같이 계산합니다.
\[\log p(\boldsymbol{\theta}|\mathcal{X, Y}) = \log p(\mathcal{Y}|\mathcal{X},\boldsymbol{\theta}) + \log p(\boldsymbol{\theta}) + \text{const} \tag{9.25}\]위 식에서 상수는 $\boldsymbol{\theta}$ 에 독립적인 항들로 구성됩니다. 여기서 (9.25)의 log-posterior는 log-likelihood $p(\mathcal{Y}|\mathcal{X},\boldsymbol{\theta})$ 와 log-prior $\log p(\boldsymbol{\theta})$ 의 합이라는 것을 볼 수 있고, 따라서, MAP 추정치는 prior (데이터를 관측하기 전에 그럴듯한 파라미터 값에 대한 제안)와 data-dependent likelihood 사이의 “절충” 되도록 합니다.
MAP 추정치 $\boldsymbol{\theta}_{\text{MAP}}$ 를 찾기 위해서, $\boldsymbol{\theta}$ 에 대한 negative log-posterior distribution을 최소화합니다. 즉, 다음의 식을 풀어야 합니다.
\[\boldsymbol{\theta}_{\text{MAP}}\in\arg\min_{\boldsymbol{\theta}}\{-\log p(\mathcal{Y}|\mathcal{X},\boldsymbol{\theta}) - \log p(\boldsymbol{\theta})\} \tag{9.26}\]$\boldsymbol{\theta}$ 에 대한 negative log-posterior의 gradient는 아래와 같습니다.
\[-\frac{\mathrm{d}\log p(\boldsymbol{\theta}|\mathcal{X,Y})}{\mathrm{d}\boldsymbol{\theta}} = -\frac{\mathrm{d}\log p(\mathcal{Y}|\mathcal{X},\boldsymbol{\theta})}{\mathrm{d}\boldsymbol{\theta}} - \frac{\mathrm{d}\log p(\boldsymbol{\theta})}{\mathrm{d}\boldsymbol{\theta}} \tag{9.27}\]여기서 우항의 첫 번째 항은 (9.11c)의 negative log-likelihood의 gradient와 동일합니다.
파라미터 $\boldsymbol{\theta}$ 에 대한 (Conjugate) Gaussian prior $p(\boldsymbol{\theta}) = \mathcal{N}(\boldsymbol{0},b^2\boldsymbol{I})$ 와 (9.13)의 linear regression setting에 대한 negative log-likelihood를 가지고, 다음의 negative log posterior를 얻습니다.
\[-\log p(\boldsymbol{\theta}|\mathcal{X,Y}) = \frac{1}{2\sigma^2}(\boldsymbol{y}-\boldsymbol{\Phi\theta})^\top(\boldsymbol{y}-\boldsymbol{\Phi\theta}) + \frac{1}{2b^2}\boldsymbol{\theta}^\top\boldsymbol{\theta} + \text{const} \tag{9.28}\]여기서 첫 번째 항은 log-likelihood로 부터 오고, 두 번째 항은 log-prior에서 옵니다. 파라미터 $\boldsymbol{\theta}$ 에 대한 log-posterior의 gradient는 아래와 같습니다.
\[-\frac{\mathrm{d}\log p(\boldsymbol{\theta}|\mathcal{X,Y})}{\mathrm{d}\boldsymbol{\theta}} = \frac{1}{\sigma^2}(\boldsymbol{\theta}^\top\boldsymbol{\Phi}^\top\boldsymbol{\Phi} - \boldsymbol{y}^\top\boldsymbol{\Phi}) + \frac{1}{b^2}\boldsymbol{\theta}^\top \tag{9.29}\]이렇게 계산한 gradient가 $\boldsymbol{0}^\top$ 과 같다고 설정하여 MAP 추정치 $\boldsymbol{\theta}_{\text{MAP}}$ 를 구할 수 있습니다.
\[\begin{align*} &\frac{1}{\sigma^2}(\boldsymbol{\theta}^\top\boldsymbol{\Phi}^\top\boldsymbol{\Phi} - \boldsymbol{y}^\top\boldsymbol{\Phi}) + \frac{1}{b^2}\boldsymbol{\theta}^\top = \boldsymbol{0}^\top \tag{9.30} \\ \Longleftrightarrow\quad&\boldsymbol{\theta}^\top\left(\frac{1}{\sigma^2}\boldsymbol{\Phi}^\top\boldsymbol{\Phi} + \frac{1}{b^2}\boldsymbol{I}\right) - \frac{1}{\sigma^2}\boldsymbol{y}^\top\boldsymbol{\Phi} = \boldsymbol{0}^\top \tag{9.30b} \\ \Longleftrightarrow\quad &\boldsymbol{\theta}^\top\left(\boldsymbol{\Phi}^\top\boldsymbol{\Phi}+\frac{\sigma^2}{b^2}\boldsymbol{I}\right) = \boldsymbol{y}^\top\boldsymbol{\Phi} \tag{9.30c} \\ \Longleftrightarrow\quad &\boldsymbol{\theta}^\top = \boldsymbol{y}^\top\boldsymbol{\Phi}\left(\boldsymbol{\Phi}^\top\boldsymbol{\Phi} + \frac{\sigma^2}{b^2}\boldsymbol{I}\right)^{-1} \tag{9.30d} \end{align*}\]따라서, MAP estimate는 다음과 같습니다.
\[\boldsymbol{\theta}_{\text{MAP}} = \left(\boldsymbol{\Phi}^\top\boldsymbol{\Phi} + \frac{\sigma^2}{b^2}\boldsymbol{I}\right)^{-1}\boldsymbol{\Phi}^\top\boldsymbol{y} \tag{9.31}\](9.31)의 MAP 추정치와 (9.19)의 MLE를 비교하면, 두 결과에서 유일한 차이점은 $\frac{\sigma^2}{b^2}\boldsymbol{I}$ 항의 추가라는 것을 알 수 있습니다. 이 항은 $\boldsymbol{\Phi}^\top\boldsymbol{\Phi} + \frac{\sigma^2}{b^2}\boldsymbol{I}$ 가 symmetric이고 strictly positive definite라는 것을 보장합니다. Strictly positive definite 이므로, 역행렬이 존재하고 MAP 추정치가 선형 연립방정식의 유일한 해라는 것을 보장합니다. 게다가, 이는 regularizer의 영향을 반영합니다.
Example 9.6 (MAP Estimation for polynomial Regression)
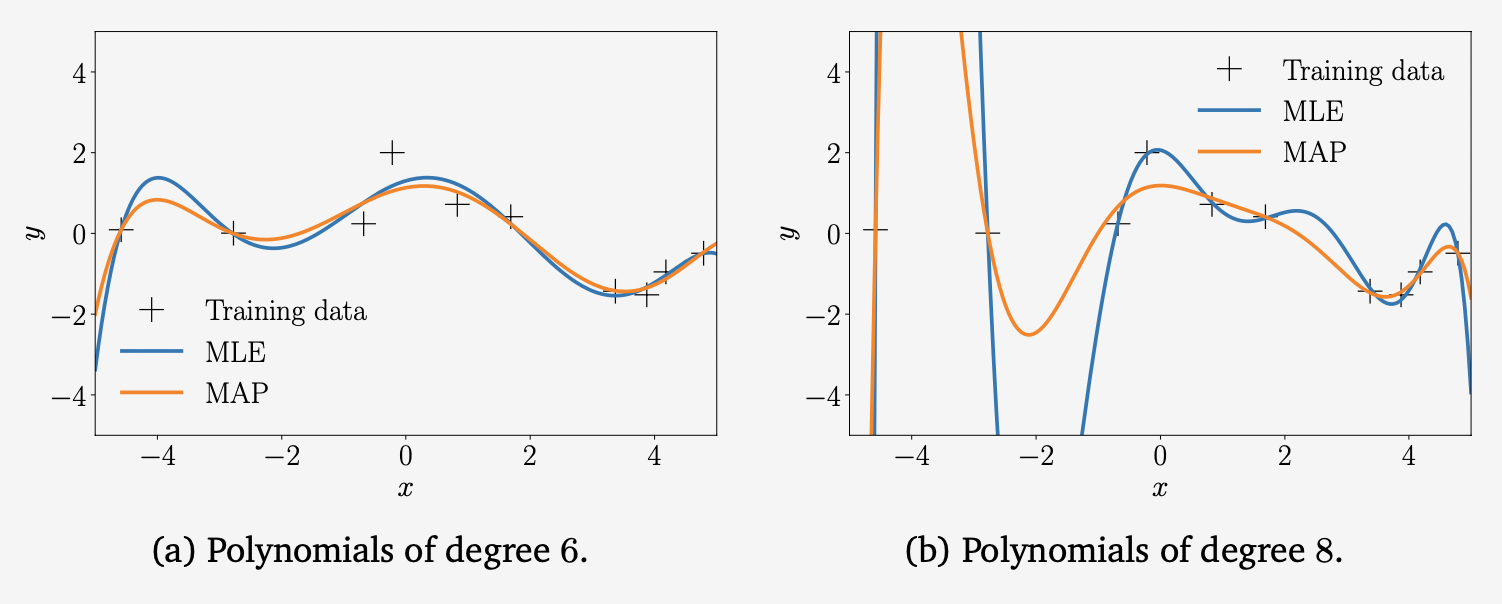
9.2.1장에서 살펴본 polynomial regression example에서, 파라미터 $\boldsymbol{\theta}$ 의 Gaussian prior $p(\boldsymbol{\theta} = \mathcal{N}(\boldsymbol{0},\boldsymbol{I})$ 를 두고 (9.31)에 해당하는 MAP 추정치를 구합니다. 아래의 그림에서 6차 다항식과 8차 다항식에서의 MLE와 MAP estimate를 모두 보여주고 있습니다.
Prior (regularizer)는 낮은 차수의 다항식에서는 중요한 역할을 하지 않지만, 고차 다항식에서는 함수가 비교적 스무스하도록 합니다. 비록 MAP estimate가 과적합의 한계를 뛰어넘을 수 있지만, 과적합에 대한 일반적인 해결 방법은 아니므로 이를 해결하려면 보다 원칙적인 접근 방법이 필요합니다.
MAP Estimation as Regularization
파라미터 $\boldsymbol{\theta}$ 의 사전 분포를 배치하는 대신, 정규화(regularization)을 통해 파라미터의 크기에 페널티를 부여하여 과적합의 영향을 완화할 수 있습니다. Regularized least squares 에서, loss function을 다음과 같이 사용합니다.
\[\|\boldsymbol{y}-\boldsymbol{\Phi\theta}\|^2 + \lambda\|\boldsymbol{\theta}\|_2^2 \tag{9.32}\]여기서 첫 번째 항은 data-fit term (also called misfit term)이며, negative log-likelihood에 비례합니다. 두 번째 항은 regularizer 라고 부르며 regularization parameter $\lambda\geq 0$ 은 정규화의 “strictness” 를 조절합니다.
(9.32)의 regularizer $\lambda\|\boldsymbol{\theta}\|_2^2$ 는 MAP estimation에서 사용하는 negative log-Gaussian prior로 해석될 수 있습니다. 보다 구체적으로, Gaussian prior $p(\boldsymbol{\theta}) = \mathcal{N}(\boldsymbol{0},b^2\boldsymbol{I})$ 를 사용하여 negative log-Gaussian prior를 얻습니다.
\[-\log p(\boldsymbol{\theta}) = \frac{1}{2b^2}\|\boldsymbol{\theta}\|^2_2 + \text{const} \tag{9.33}\]여기서 $\lambda = \frac{1}{2b^2}$ 는 regularization term이고 negative log-Gaussian prior와 동일합니다.
(9.32)에서 주어진 regularized least-squares loss function은 negative log-likelihood + negative log-prior와 매우 연관된 항으로 구성되어 있다는 점을 감안할 때, 이 loss를 최소화할 때 (9.31)에서의 MAP 추정치와 비슷한 솔루션을 얻는다는 것이 놀라운 것은 아닙니다. 구체적으로 살펴보면, regularized least-squares loss function을 최소화하는 것은 아래의 결과를 도출합니다.
\[\boldsymbol{\theta}_{\text{RLS}} = (\boldsymbol{\Phi}^\top\boldsymbol{\Phi}+\lambda\boldsymbol{I})^{-1}\boldsymbol{\Phi}^\top\boldsymbol{y} \tag{9.34}\]이는 (9.31)의 MAP estimate에서 $\lambda = \frac{\sigma^2}{b^2}$ 인 것과 동일하며, 여기서 $\sigma^2$ 는 noise variance이고 $b^2$ 는 Gaussian prior $p(\boldsymbol{\theta}) = \mathcal{N}(\boldsymbol{0},b^2\boldsymbol{I})$ 의 variance 입니다.
지금까지, 목적 함수(likelihood or posterior)를 최적화하는 point estimates $\boldsymbol{\theta}^{\ast}$ 를 찾는 MLE와 MAP 추정을 다루었습니다. 여기서 MLE와 MAP가 모두 과적합을 유도할 수 있다는 것을 확인했습니다. 다음 장에서는 Bayesian linear regression에 대해 다룰텐데, 여기서는 알지 못하는 파라미터에 대한 posterior distribution을 찾기 위해 베이지안 추론(8.4장 참조)을 사용하며, 이후에는 예측할 때 사용합니다. 보다 구체적으로, 예측할 때 point estimate에 초점을 맞추는 대신 모든 그럴듯한 파라미터 집합에 대한 평균을 계산합니다.