Intro
2장과 3장에서는 vectors, projection of vectors, linear mapping에 대해서 살펴봤습니다. Mapping과 transformations of vectors는 행렬로 수행되는 연산으로 다룰 수 있었습니다. 그리고, 행렬의 행을 각 사람들로 두고 행렬의 열을 각 사람들의 feature로 두어 데이터를 행렬 형태로 표현할 수도 있습니다. 4장에서는 3가지 행렬의 측면 how to summarize matrices / how matrices can be decomposed / how these decompositions can be used for matrix approximations 을 살펴보도록 하겠습니다.
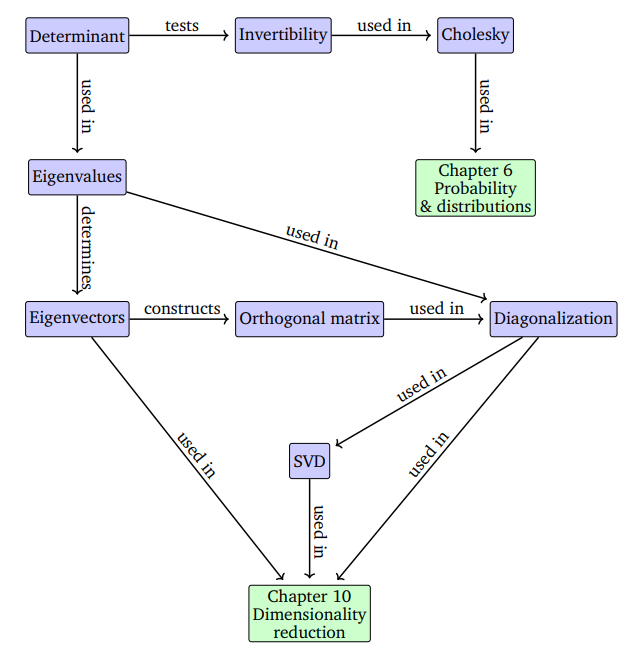
4장에서는 먼저 행렬의 전체 속성을 특성화(characterize)하는 숫자로 행렬을 설명하는 방법에 대해 살펴봅니다. 4.1장의 Determinants와 4.2장의 Eigenvalues는 정사각 행렬인 경우에서 매우 중요합니다. 이러한 characteristic number는 중요한 수학적 결과를 가지고 있으며 행렬에 어떤 유용한 속성이 있는지 빠르게 파악할 수 있도록 해줍니다. 여기서부터 행렬을 분해(decomposition)하는 방법에 대해 살펴봅니다. 행렬 분해는 21라는 숫자를 소수들의 곱 7x3으로 분해하는 것과 유사하며, matrix factorization 이라고도 칭합니다.
행렬 분해(Matrix decompositions)와 관련하여, 먼저 대칭(symmetric)이면서 양의 정부호(positive definite) 행렬에 대한 Cholesky decomposition(4.3장)을 살펴봅니다. 여기서는 행렬을 표준 형태(canonical forms)로 분해하는 두 가지 방법을 살펴봅니다. 첫 번째 방법은 행렬 대각화(matrix diagonalization, 4.4장)이며, 이는 적절한 basis를 선택하여 diagonal transformation matrix를 사용하는 linear mapping으로 표현할 수 있습니다. 두 번째 방법은 특잇값 분해(SVD, singular value decomposition, 4.5장) 입니다. SVD는 행렬 분해를 정사각 행렬이 아닌 행렬로 확장하며 선형대수학의 기본 개념 중 하나입니다. 수치 데이터를 표현하는 행렬은 일반적으로 매우 크고 분석하기가 어렵기 때문에 이러한 행렬 분해는 매우 유용하게 사용됩니다.
4장에서 살펴보는 방법들은 6장뿐만 아니라 10장의 Dimensionality Reduction이나 11장의 Density Estimation에서도 유용하게 사용됩니다. 4장의 전체적인 흐름은 아래와 같습니다.