Conjugacy and the Exponential Family
통계학에서 이름을 가진 확률 분포들의 대부분은 특정 유형의 현상들을 모델링하기 위해서 발견되었습니다. 예를 들면, 6.5장 에서 살펴본 가우시안 분포가 있습니다.
또한, 분포들은 복잡한 방식으로 서로 연관되어 있습니다. 이 분야의 비기너들에게는 어떤 분포를 사용해야 하는지 파악하기에 너무 방대할 수 있는데, 이러한 분포의 대부분은 컴퓨터가 아닌 연필과 종이로 계산하던 시기에 발견되었습니다.
현재 컴퓨터를 사용하는 시대에서 이러한 분포들이 어떠한 의미가 있는지 파악하는 것이 중요합니다. 추론에 필요한 많은 연산들이 분포가 가우시안일 때 편리하다는 것을 6.5장에서 살펴봤습니다.
이러한 관점에서 머신러닝 맥락에서의 확률 분포 조작이 필요한 데이터를 다시 한 번 상기해보도록 하겠습니다.
- 베이즈 정리(Bayes’ theorem)과 같은 확률 법칙(rules of probability)을 적용할 때, “closure property”가 있습니다. “closure”는 특정 연산을 수행했을 때, 동일한 타입의 객체를 반환한다는 것을 의미합니다.
- 더 많은 데이터들을 수집했을 때, 이러한 분포를 설명하기 위해 더 많은 파라미터가 필요하지 않습니다.
- 데이터로부터 학습하는 것에 관심이 있으므로, 파라미터 추정이 원할하기를 원합니다.
Exponential Family (지수족) 이라고 하는 분포들이 적절한 연산과 추론 속성들을 유지하면서 일반성(generality)의 올바른 균형을 제공한다는 것이 밝혀졌습니다. 이러한 지수족(exponential family) 소개하기 전에 베르누이(Bernoulli), 이항(Binormal), 베타(Beta) 분포를 예제를 통해 살펴보도록 하겠습니다.
Example 6.8
베르누이 분포(Bernoulli distribution)은 $x\in\lbrace 0,1\rbrace$ 의 state를 가진 single binary random variable $X$ 에 대한 분포입니다. 베르누이 분포 $\text{Ber}(\mu)$ 는 $X=1$ 의 확률을 표현하는 single continuous parameter $\mu\in\lbrack 0,1\rbrack$ 에 의해 제어되며, 다음과 같이 정의됩니다.
\[\begin{align*} p(x|\mu) &= \mu^x(1-\mu)^{1-x}, \quad x\in\lbrace 0,1\rbrace \tag{6.92} \\ \mathbb{E}[x] &= \mu \tag{6.93} \\ \mathbb{V}[x] &= \mu(1-\mu) \tag{6.94} \end{align*}\]$\mathbb{E}[x]$ 와 $\mathbb{V}[x]$ 는 각각 binary random variable $X$ 의 평균(mean)과 분산(variance) 입니다.
베르누이 분포는 동전을 던질 때, 앞면(heads)의 확률을 모델링할 때 사용될 수 있습니다.
Example 6.9 (Binomial Distribution)
이항 분포(Binomial distribution)는 베르누이 분포를 정수(integers)에 대한 분포로 일반화한 것 입니다. 아래 그림 Figure 6.10이 그 예시입니다.
이항 분포는 베르누이 분포( $p(X=1) = \mu\in[0,1]$) 로부터 N개의 샘플에서 $X=1$ 이 $m$ 번 발생할 확률을 설명하는데 사용될 수 있습니다. 이항 분포 $\text{Bin}(N, \mu)$ 는 다음과 같이 정의됩니다.
\[\begin{align*} p(m|N, \mu) &= \binom{N}{m}\mu^m(1-\mu)^{N-m} \tag{6.95} \\ \mathbb{E}[m] &= N\mu \tag{6.96} \\ \mathbb{V}[m] &= N\mu(1-\mu) \tag{6.97} \end{align*}\]$\mathbb{E}[m]$ 와 $\mathbb{V}[m]$ 는 각각 $m$ 의 평균(mean)과 분산(variance) 입니다.
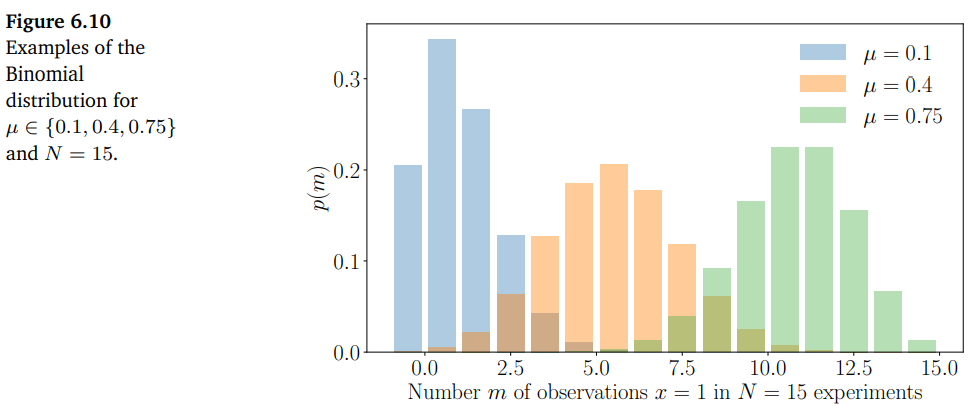
이항 분포는 단일 실험에서 앞면이 나올 확률이 $\mu$ 인 동전을 $N$ 번 던져서 $m$ 개의 앞면이 나올 확률을 모델링할 때 사용될 수 있습니다.
Example 6.10 (Beta Distribution)
베타 분포(Beta distribution)로 유한한 구간에서 연속 확률 변수를 모델링할 수 있습니다. 베타 분포는 연속 확률 변수 $\mu\in[0,1]$ 에 대한 분포로, 일부 binary event(예를 들어, 베르누이 분포를 제어하는 파라미터)의 확률을 나타내는데 주로 사용됩니다. 베타 분포 $\text{Beta}(\alpha,\beta)$ 는 두 파라미터 $\alpha>0,\beta>0$ 에 의해 제어되며, 다음과 같이 정의됩니다.
\[\begin{align*} p(\mu|\alpha, \beta) &= \frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)}\mu^{\alpha-1}(1-\mu)^{\beta-1} \tag{6.98} \\ \mathbb{E}[\mu] &= \frac{\alpha}{\alpha+\beta}, \quad \mathbb{V}[\mu] = \frac{\alpha\beta}{(\alpha+\beta)^2(\alpha+\beta+1)} \tag{6.99} \end{align*}\]이때, $\Gamma(\cdot)$ 은 Gamma Function으로, 다음과 같이 정의됩니다.
\[\begin{align*} \Gamma(t) &:= \int_{0}^{\infty} x^{t-1}\exp(-x)dx, \quad t > 0 \tag{6.100} \\ \Gamma(t+1) &= t\Gamma(t) \tag{6.101} \end{align*}\](6.98)의 gamma function은 베타 분포를 정규화(normalization)합니다.
아래 그림은 $\alpha, \beta$ 에 따른 몇 가지 베타 분포를 보여줍니다.
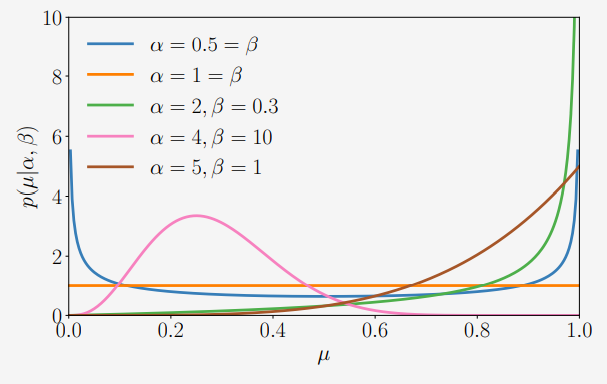
직관적으로 베타 분포에서 $\alpha$ 는 probability mass를 1로 움직이도록 하고, $\beta$ 는 0으로 움직이도록 합니다. 베타 분포에는 다음과 같은 몇 가지 special cases가 있습니다.
- $\alpha=1,\beta=1$ 일 때, uniform distribution $\mathcal{U}[0,1]$ 을 얻을 수 있습니다.
- $\alpha,\beta < 1$ 일 때, 0과 1에서 솟구치는 bimodal distribution을 얻을 수 있습니다.
- $\alpha,\beta > 1$ 일 때의 분포는 unimodal 입니다.
- $\alpha,\beta > 1$ 이면서 $\alpha=\beta$ 일 때의 분포는 unimodal, symmetric 이고, $[0,1]$ 구간의 중심에 있습니다. 즉, mode와 mean은 모두 $\frac{1}{2}$ 에 위치합니다.
Conjugacy
베이즈 정리 (6.23)에 의하면, 사후 확률(posterior)은 사전 확률(prior)과 likelihood의 곱에 비례합니다. 사전 확률의 specification은 두 가지 이유로 복잡할 수 있습니다. 첫째, 사전 확률은 데이터를 직접 관측하기 전에 문제에 대한 지식을 가지고 있어야 하지만 이는 쉽지 않습니다. 둘째, 사후 분포를 분석적으로 계산하는 것은 일반적으로 불가능합니다.
그러나 계산한 몇 가지 편리한 사전 확률들이 있는데, 이들이 바로 conjugate priors 입니다.
Definition 6.13 (Conjugate Prior).
만약 사후 확률(posterior)이 사전 확률(prior)의 형태(form) 또는 유형(type)과 같다면, 이 사전 확률(prior)는 likelihood function에 대한 conjugate(켤레) 입니다.
Conjugacy는 prior distribution의 파라미터를 업데이트하여 posterior distribution을 대수적으로 계산할 수 있기 때문에 편리합니다.
Conjugate priors의 구체적인 예시를 위해서, 이항 분포와 베타 분포를 Example 6.11에서 살펴보도록 하겠습니다.
Example 6.11 (Beta-Binormal Conjugacy)
아래와 같이 정의되는 binormal random variable $x\sim\text{Bin}(N,\mu)$ 를 고려해봅시다 (N번 동전을 던졌을 때, 앞면이 x번 나올 확률).
\[p(x|N,\mu) = \binom{N}{x}\mu^x(1-\mu)^{N-x}, \quad x = 0,1,\dotsc,N \tag{6.102}\]여기서 $\mu$ 는 앞면이 나올 확률입니다.
그리고, 파라미터 $\mu$ 에 대한 Beta prior, 즉, $\mu\sim\text{Beta}(\alpha,\beta)$ 를 다음과 같이 정의합니다.
\[p(\mu|\alpha,\beta) = \frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)}\mu^{\alpha-1}(1-\mu)^{\beta-1} \tag{6.103}\]이제 어떤 결과 $x=h$ , 즉, 동전을 N번 던졌을 때 h번 앞면이 나오는 결과를 관측하면, $\mu$ 에 대한 사후 분포(posterior distribution)을 다음과 같이 계산할 수 있습니다.
\[\begin{align*} p(\mu|x=h,N,\alpha,\beta) &\propto p(x|N,\mu)p(\mu|\alpha,\beta) \tag{6.104a} \\ &\propto \mu^h(1-\mu)^{N-h}\mu^{\alpha-1}(1-\mu)^{\beta-1} \tag{6.104b} \\ &= \mu^{h+\alpha-1}(1-\mu)^{(N-h)+\beta-1} \tag{6.104c} \\ &\propto \text{Beta}(h+\alpha, N-h+\beta) \tag{6.104d} \end{align*}\]즉, 사후 분포(posterior distribution)는 prior와 같은 Beta distribution 입니다. 따라서, Beta prior는 Binomial likelihood function의 파라미터 $\mu$ 에 대한 conjugate 입니다.
위 예제에 이어서 베타 분포가 베르누이 분포에 대한 conjugate prior 라는 것을 보도록 하겠습니다.
Example 6.12 (Beta-Bernoulli Conjugacy)
$x\in\lbrace0,1\rbrace$ 가 파라미터 $\theta\in[0,1]$ 인 베르누이 분포를 따른다고 가정하겠습니다. 즉, $p(x=1|\theta) = \theta$ 입니다. 이는 다음과 같이 표현될 수도 있습니다.
\[p(x|\theta) = \theta^x(1-\theta)^{1-x}\]이제 $\theta$ 가 파라미터 $\alpha, \beta$ 를 갖는 베타 분포를 따른다고 가정합니다. 즉, 다음과 같습니다.
\[p(\theta|\alpha,\beta) \propto \theta^{\alpha-1}(1-\theta)^{\beta-1}\]베타 분포와 베르누이 분포를 곱하면, 다음의 식을 얻을 수 있습니다.
\[\begin{align*} p(\theta|x,\alpha,\beta) &= p(x|\theta)p(\theta|\alpha,\beta) \tag{6.105a} \\ &\propto \theta^x(1-\theta)^{1-x}\theta^{\alpha-1}(1-\theta)^{\beta-1} \tag{6.105b} \\ &= \theta^{\alpha+x-1}(1-\theta)^{\beta+(1-x)-1} \tag{6.105c} \\ &\propto p(\theta|\alpha+x,\beta+(1-x)) \tag{6.105d} \end{align*}\]위 식에서 마지막 식은 파라미터 $(\alpha+x, \beta+(1-x))$ 를 갖는 베타 분포라는 것을 보여줍니다.

위의 표는 확률 모델링에 사용되는 몇 가지 표준 likelihood의 파라미터에 대한 conjugate priors를 보여줍니다. Multinomial, inverse Gamma, inverse Wishart, Dirichlet과 같은 분포는 다른 통계학 교재에서 참고하시길 바랍니다.
베타 분포는 파라미터 $\mu$ 에 의해 제어되는 Binomial / Bernoulli likelihood 에 대한 conjugate prior 입니다. Gaussian likelihood function의 경우는 평균(mean)에 대한 conjugate Gaussian prior를 지정할 수 있습니다. 위 표에서 가우시안 likelihood가 두 번 등장하는 이유는 univariate와 multivariate를 구분하기 위해서 입니다. Univariate(scalar)의 경우에는 inverse Gamma가 분산(variance)에 대한 conjugate prior 입니다. Multivariate인 경우에는 covariance matrix에 대한 prior로 conjugate inverse Wishart distribution을 사용합니다. Dirichlet distribution은 multinomial likelihood function에 대한 conjugate prior 입니다.
이와 관련하여 조금 더 자세한 내용은 PRML에서 자세히 살펴볼 예정입니다.
Sufficient Statistics
확률 변수의 통계량(statistic)은 그 확률 변수의 deterministic function 입니다. 예를 들어, 만약 $\boldsymbol{x} = [x_1,\dotsc,x_N]^\top$ 이 univariate Gaussian random variables의 벡터, 즉, $x_n\sim\mathcal{N}(\mu,\sigma^2)$ 라면, sample mean $\hat{\mu} = \frac{1}{N}(x_1+\cdots+x_N)$ 은 통계량(statistic) 입니다. Ronald Fisher는 sufficient statistics(충분통계량) 이라는 개념을 발견했는데, 이는 고려 중인 분포에 대응하는 데이터로부터 추론할 수 있는 모든 사용 가능한 정보를 포함하는 통계량이 있다는 아이디어입니다. 다시 말하면, sufficient statistic는 모집단(population)에 대해 추론하는데 필요한 모든 정보를 포함합니다. 즉, 분포를 표현하기에 충분한 통계입니다.
$\theta$ 에 의해 매개변수화된 분포 집합에 대해, $X$ 가 $p(x|\theta_0)$ 분포(given an unkwown $\theta_0$)를 갖는 확률 변수라고 합시다. 만약 통계량 벡터 $\phi(x)$ 가 $\theta_0$ 에 대해 모든 가능한 정보를 포함하고 있다면, 이를 $\theta_0$ 에 대한 sufficient statistics(충분 통계량)이라고 부릅니다. 모든 가능한 정보를 포함하다는 것은 주어진 $\theta$ 에 대한 $x$ 의 확률이 $\theta$ 에 의존하지 않는 부분과 $\phi(x)$ 만을 통해서 $\theta$ 에 의존하는 부분으로 분해될 수 있다는 것을 의미합니다.
Fisher-Neyman factorization theorem은 이 개념을 공식화하며 아래 Theorem 6.14와 같습니다.
Theorem 6.14 (Fisher-Neyman). $X$ 가 확률 밀도 함수(probability density function) $p(x|\theta)$ 를 갖는다고 가정합시다. 만약 $p(x|\theta)$ 가 아래의 형태로 작성될 수 있다면,
\[p(x|\theta) = h(x)g_{\theta}(\phi(x)) \tag{6.106}\]통계량 $\phi(x)$ 는 $\theta$ 에 대해 sufficient하다고 합니다.
여기서 $h(x)$ 는 $\theta$ 에 독립적인 분포이고 $g_{\theta}$ 는 sufficient statistics $\phi(x)$ 를 통해 $\theta$ 에 의존적인 모든 정보를 포함합니다.
만약 $p(x|\theta)$ 가 $\theta$ 에 의존적이지 않다면, $\phi(x)$ 는 모든 어떠한 함수 $\phi$ 에 대해 sufficient statistic 이라는 것이 자명합니다. 조금 더 흥미로운 케이스는 $p(x|\theta)$ 가 $x$ 자체가 아닌 오직 $\phi(x)$ 에 의존하는 경우입니다. 이러한 경우에는 $\phi(x)$ 가 $\theta$ 에 대한 sufficient statistic 이 됩니다.
머신러닝에서 우리는 분포로부터 유한한 수의 샘플을 고려하게 됩니다. 베르누이와 같은 단순한 분포의 경우에는 분포의 매개변수를 추정하기 위해 적은 수의 샘플만이 필요하다고 상상할 수 있습니다. 또한, 반대의 경우도 생각해볼 수 있습니다. 만약 알 수 없는 분포로부터의 데이터 집합이 있는 경우 어떤 분포가 가장 적합할까요? 또는 더 많은 데이터를 관측할 때, 이 분포를 설명하기 위해서 더 많은 파라미터 $\theta$ 가 필요할까요?
일반적으로 위의 마지막 질문에 대한 대답은 yes 이며, 이는 non-parametric statistics 에서 연구됩니다.
반대 질문으로 어떤 분포가 유한한 차원의 충분통계량을 갖고 있는지, 즉, 이 분포를 설명하기 위한 파라미터의 수가 임의로 증가하지는 않는 지에 대한 질문이 있을 수 있습니다. 이에 대한 답은 exponential family 에서 찾을 수 있습니다.
Exponential Family
Discrete 또는 continuous random variables의 분포를 고려할 때, 3가지의 추상화 레벨이 있습니다.
- Level 1: 고정된 파라미터를 가진 이름이 있는 특정 분포. 예를 들면, univariate Gaussian $\mathcal{N}(0, 1)$.
- Level 2: 머신러닝에서 주로 level 2를 다룹니다. Level 2에서는 파라미터를 수정하고 데이터로부터 파라미터를 추론합니다. 예를 들어, univariate Gaussian $\mathcal{N}(\mu,\sigma^2)$ 를 가정하고, 최적의 파라미터 $(\mu, \sigma^2)$ 를 결정하기 위해 maximum likelihood를 사용합니다. 이에 대한 내용은 9장의 linear regression을 살펴볼 때 자세히 다룹니다.
- Level 3: Level 3에서는 분포 계열(families of distributions)를 고려하는 것이며, 이 교재에서는 exponential family(지수족)에 대해 고려합니다. Univariate Gaussian은 exponential family 멤버의 한 예입니다. 6.6.1장에서 conjugate prior를 살펴볼 때 봤었던 표에 있는 이름이 있는 모든 분포들을 포함하여 널리 사용되는 많은 통계 모델들이 지수족의 멤버입니다. 이러한 모델들은 하나의 개념으로 통합될 수 있습니다.
Exponential Family 는 아래의 형태와 같이 $\boldsymbol{\theta}\in\mathbb{R}^D$ 에 의해 매개변수화되는 확률 분포의 family 입니다.
\[p(\boldsymbol{x}|\boldsymbol{\theta}) = h(\boldsymbol{x})\exp{(\langle\boldsymbol{\theta}, \phi(\boldsymbol{x})\rangle - A(\boldsymbol{\theta}))} \tag{6.107}\]위 식에서 $\phi(\boldsymbol{x})$ 는 충분통계량(sufficient statistics) 벡터입니다. 일반적으로 식 (6.107)에서는 어떠한 내적(inner product)도 사용될 수 있으며, 여기서는 구체적으로 표준 내적 $(\langle\boldsymbol{\theta},\phi(\boldsymbol{x})\rangle = \boldsymbol{\theta}^\top\phi(\boldsymbol{x}))$ 을 사용합니다. 본질적으로 지수족의 형태는 Theorem 6.14에서 살펴본 Fisher-Neyman theorem에서 $g_{\theta}(\phi(x))$ 의 지수 형태의 특정 표현으로 사용하는 것과 같습니다.
$h(\boldsymbol{x})$ factor는 sufficient statistics $\phi(\boldsymbol{x})$ 에 또 다른 항 $\log{h(\boldsymbol{x})}$ 를 추가하고, 대응하는 파라미터 $\theta_0 = 1$ 로 제한하여 내적항으로 흡수될 수 있습니다.
$A(\boldsymbol{\theta})$ 항은 normalization constant이며 분포의 합이 1이 되도록 해줍니다. 이 항은 log-partition function 이라고 부릅니다.
지수족에 대한 직관적인 개념은 $h(\boldsymbol{x})$ 와 $A(\boldsymbol{\theta})$ 항을 무시하고 아래의 형태의 분포로 간주하면 이해하는데 도움이 됩니다.
\[p(\boldsymbol{x}|\boldsymbol{\theta}) \propto \exp{(\boldsymbol{\theta}^\top\phi(\boldsymbol{x}))} \tag{6.108}\]이러한 형태의 매개변수화(parametrization)에서, 파라미터 $\boldsymbol{\theta}$ 는 natural parameters 라고 부릅니다. 언뜻보기에는 지수족은 내적의 결과에 지수 함수를 취한 것과 같은 평범한 변환으로 보입니다. 하지만 $\phi(\boldsymbol{x})$ 에서 데이터에 대한 정보를 얻을 수 있따는 사실을 기반으로 편리한 모델링과 효율적인 연산을 가능한다는 점에서 많은 의미가 있습니다.
Example 6.13 (Gaussian as Exponential Family)
Univariate Gaussian distribution $\mathcal{N}(\mu,\sigma^2)$ 를 고려해보도록 하겠습니다. 이때, $\phi(x) = \begin{bmatrix}x\\x^2\end{bmatrix}$ 입니다. 그러면 지수족의 정의를 사용하여 아래의 식을 얻을 수 있습니다.
\[p(x|\boldsymbol{\theta}) \propto \exp(\theta_1 x + \theta_2 x^2) \tag{6.109}\]파라미터 $\boldsymbol{\theta}$ 를 다음과 같이 설정하고
\[\boldsymbol{\theta} = \begin{bmatrix} \frac{\mu}{\sigma^2} & -\frac{1}{2\sigma^2} \end{bmatrix}^\top \tag{6.110}\]이를 식 (6.109)에 대입하면 다음의 식을 얻을 수 있습니다.
\[p(x|\boldsymbol{\theta}) \propto \exp\left(\frac{\mu x}{\sigma^2} - \frac{x^2}{2\sigma^2}\right) \propto \exp\left(-\frac{1}{2\sigma^2}(x-\mu)^2\right) \tag{6.111}\]따라서, univariate Gaussian distribution은 sufficient statistic $\phi(x) = \begin{bmatrix}x\\x^2\end{bmatrix}$ 와 $\boldsymbol{\theta}$ 로 주어지는 natural parameter 갖는 지수족의 멤버입니다.
Example 6.14 (Bernoulli as Exponential Family)
Example 6.8에서 살펴본 아래의 베르누이 분포를 다시 살펴봅시다.
\[p(x|\mu) = \mu^x(1-\mu)^{1-x}, \quad x \in \{0,1\} \tag{6.112}\]이는 지수족 형태로 다음과 같이 작성될 수 있습니다.
\[\begin{align*} p(x|\mu) &= \exp[\log(\mu^x(1-\mu)^{1-x})] \tag{6.113a} \\ &= \exp[x\log\mu + (1-x)\log(1-\mu)] \tag{6.113b} \\ &= \exp[x\log\mu - x\log(1-\mu) + log(1-\mu)] \tag{6.113c} \\ &= \exp\left\lbrack x\log\frac{\mu}{1-\mu} + \log(1-\mu)\right\rbrack \tag{6.113d} \end{align*}\]마지막 식 (6.113d) 는 (6.107)의 지수족 형태와 동일하며
\[\begin{align*} h(x) &= 1 \tag{6.114} \\ \theta &= \log\frac{\mu}{1-\mu} \tag{6.115} \\ \phi(x) &= x \tag{6.116} \\ A(\theta) &= -\log(1-\mu) = \log(1+\exp(\theta)) \tag{6.117} \end{align*}\]이라는 것을 관찰할 수 있습니다.
$\theta$ 와 $\mu$ 의 관계는 invertible 하며, 다음을 만족합니다.
\[\mu = \frac{1}{1+\exp(-\theta)} \tag{6.118}\]
특정 분포의 conjugate distribution의 parametric form을 찾는 것이 명확하지 않은 경우가 많습니다. 이러한 경우에 지수족은 분포의 conjugate pairs를 찾는 편리한 방법을 제공합니다. 확률 변수 $X$ 가 지수족 (6.107)의 멤버라고 간주해봅시다.
\[p(\boldsymbol{x}|\boldsymbol{\theta}) = h(\boldsymbol{x})\exp(\langle\boldsymbol{\theta},\phi(\boldsymbol{x})\rangle -A(\boldsymbol{\theta})) \tag{6.119}\]지수족의 모든 멤버들은 아래 형태의 conjugate prior를 갖습니다.
\[p(\boldsymbol{\theta}|\boldsymbol{\gamma}) = h_c(\boldsymbol{\theta})\exp\left(\left\langle\begin{bmatrix}\gamma_1\\\gamma_2\end{bmatrix},\begin{bmatrix}\boldsymbol{\theta}\\-A(\boldsymbol{\theta})\end{bmatrix}\right\rangle - A_c(\boldsymbol{\gamma})\right) \tag{6.120}\]여기서 $\boldsymbol{\gamma} = \begin{bmatrix}\gamma_1\\ \gamma_2\end{bmatrix}$ 은 차원이 $\text{dim}(\boldsymbol{\theta}) + 1$ 입니다. 그리고 conjugate prior의 sufficient statistics는 $\begin{bmatrix}\boldsymbol{\theta}\\ -A(\boldsymbol{\theta})\end{bmatrix}$ 입니다. 지수족에 대한 conjugate priors의 기본적인 형태를 사용하면 특정 분포에 대응하는 conjugate priors의 형태를 유도할 수 있습니다.
Example 6.15
(6.113d)의 베르누이 분포의 지수족 형태를 다시 살펴봅시다.
\[p(x|\mu) = \exp\left\lbrack x\log\frac{\mu}{1-\mu} + \log(1-\mu)\right\rbrack \tag{6.121}\]이 분포의 canonical conjugate prior는 다음의 형태를 갖습니다.
\[p(\mu|\alpha,\beta) = \frac{\mu}{1-\mu}\exp\left\lbrack \alpha\log\frac{\mu}{1-\mu} + (\beta+\alpha)\log(1-\mu) - A_c(\boldsymbol{\gamma}) \right\rbrack \tag{6.122}\]위 식에서 $\boldsymbol{\gamma} := [\alpha, \beta+\alpha]^\top$ 이고, $h_c(\mu) := \mu/(1-\mu)$ 입니다. (6.122) 식은 다음와 같이 간단하게 정리할 수 있습니다.
\[p(\mu|\alpha,\beta) = \exp[(\alpha-1)\log\mu + (\beta-1)\log(1-\mu)-A_c(\alpha,\beta)] \tag{6.123}\]위 식을 non-exponential family form에 대입하면 다음과 같으며,
\[p(\mu|\alpha,\beta) \propto \mu^{\alpha-1}(1-\mu)^{\beta-1} \tag{6.124}\]이는 Beta distribution (6.98)과 동일합니다. Example 6.12에서 우리는 Beta distribution이 베르누이 분포의 conjugate prior라고 가정했었고, 실제로 conjugate prior라는 것을 봤습니다. 이번 예제에서는 지수족 형태의 베르누이 분포의 conjugate prior를 살펴봄으로써 베타 분포를 유도했습니다.
6.6.2장에서 언급했듯이 지수족의 주요 motivation은 이들이 유한 차원의 sufficient statistics를 가지고 있다는 것입니다. 또한, conjugate distibution을 구하기 쉽고, 이 또한 지수족입니다. 추론의 관점에서 maximum likelihood estimation(MLE; 최대우도추정)은 sufficient statistics의 경험적 추정이 sufficient statistics의 모집단 값에 대한 최적의 추정이기 때문에 훌륭하게 동작합니다. 최적화 관점에서는 log-likelihood function이 concave(오목함수) 이기 때문에 효율적인 최적화 접근을 적용할 수 있습니다.