Eigenvalues and Eigenvectors
Eigenvalues와 eigenvectors에 대한 시각적 이해를 위해 3Blue1Brown 강의(link)를 먼저 보시는 것을 추천드립니다 !
이번 장에서는 행렬과 linear mapping을 특성화하는 새로운 방법에 대해 살펴봅니다. 모든 linear mapping은 ordered basis로 주어진 유일한 transformation matrix가 있습니다 (2.7.1장). 여기서 ‘eigen’ analysis를 수행함으로써 linear mapping과 그 변환을 해석할 수 있습니다. 이번 장을 통해서 알게되겠지만, linear mapping의 eigenvalues(고윳값)은 특별한 벡터 집합(eigenvectors, 고유벡터)가 linear mapping에 의해 어떻게 변환되는지 보여줍니다.
Definition 4.6
$\boldsymbol{A} \in \mathbb{R}^{n \times n}$ 이 square matrix일 때, 다음의 식을 만족하는
\[\boldsymbol{Ax} = \lambda\boldsymbol{x} \tag{4.25}\]$\lambda \in \mathbb{R}$ 를 $\boldsymbol{A}$ 의 eigenvalue(고윳값) 라 하고, $\boldsymbol{x}\in\mathbb{R}\backslash\lbrace\boldsymbol{0}\rbrace$ 를 대응되는 eigenvector(고유벡터) 라고 합니다.
식 (4.25)는 eigenvalue equation 이라고 부릅니다.
고윳값과 고유벡터와 관련하여 아래의 문장들은 모두 동일한 의미를 가지고 있습니다.
- $\lambda$ 는 $\boldsymbol{A}\in\mathbb{R}^{n\times n}$ 의 eigenvalue 입니다.
- $\boldsymbol{Ax} = \lambda\boldsymbol{x}$ 를 만족하는 $\boldsymbol{x} \in \mathbb{R}^n\backslash\lbrace\boldsymbol{0}\rbrace$ 가 존재합니다. 또는, 이와 동일하게 $(\boldsymbol{A} - \lambda\boldsymbol{I}_n)\boldsymbol{x} = \boldsymbol{0}$ 에서 0-벡터가 아닌 해가 존재합니다 ($\boldsymbol{x}\neq\boldsymbol{0}$).
- $\text{rk}(\boldsymbol{A}-\lambda\boldsymbol{I}_n) < n$
- $\det(\boldsymbol{A} - \lambda\boldsymbol{I}_n) = 0$
Defitnition 4.7 (Collinearity and Codirection)
두 벡터가 같은 방향을 가리키고 있을 때, 이를 codirected 하다고 합니다. 만약 두 벡터가 같은 방향 또는 반대 방향을 가리키고 있다면, 두 벡터를 collinear 하다고 합니다.
Theorem 4.8. $\lambda$ 가 $\boldsymbol{A}$ 의 characteristic polynomial $p_{\boldsymbol{A}}(\lambda)$ 의 근(root)일 때, $\lambda \in \mathbb{R}$ 는 $\boldsymbol{A} \in \mathbb{R}^{n\times n}$ 의 eigenvalue 입니다.
Definition 4.9. Square matrix $\boldsymbol{A}$ 의 eigenvalue 를 $\lambda_i$ 라고 한다면, $\lambda_i$ 의 algebraic multiplicity(대수적 중복도) 는 특성 다항식에서 근이 나타나는 수 입니다.
Definition 4.10 (Eigenspace and Eigenspectrum). Eigenvalue가 $\lambda$ 인 $\boldsymbol{A}\in\mathbb{R}^{n\times n}$ 에 대해 $\boldsymbol{A}$ 의 모든 eigenvectors 집합은 $\mathbb{R}^n$ 의 subspace를 span합니다. 이를 $\lambda$ 에 대한 $\boldsymbol{A}$ 의 eigenspace(고유공간)라고 하고, $E_\lambda$ 로 표기합니다. 그리고 $\boldsymbol{A}$ 의 모든 eigenvalues 집합을 $\boldsymbol{A}$ 의 eigenspectrum 또는 단순히 spectrum 이라 합니다.
$\boldsymbol{A}$ 의 eigenvalue를 $\lambda$ 라고 한다면, 이에 대응되는 eigenspace $E_\lambda$ 는 homogeneous한 연립선형방정식 $(\boldsymbol{A}-\lambda\boldsymbol{I})\boldsymbol{x} = 0$ 의 soltuion space 입니다. 기하학적으로, 0이 아닌 eigenvalue에 대응되는 eigenvector는 linear mapping에 의해 확장되는 방향을 가리킵니다. 이때, eigenvalue는 얼마나 확장되는지를 나타내는 factor가 됩니다. 만약 eigenvalue가 음수라면 그 방향은 반대가 됩니다.
Example 4.4 (The Case of the Identity Matrix)
단위 행렬 $\boldsymbol{I}\in\mathbb{R}^{n\times n}$ 의 특성 다항식은 $p_{\boldsymbol{I}}(\lambda) = \det(\boldsymbol{I}-\lambda\boldsymbol{I}) = (1-\lambda)^n = 0$ 입니다. 이때, 오직 n번 나타나는 하나의 eigenvalue $\lambda = 1$ 만을 가집니다. 게다가, 모든 벡터 $\boldsymbol{x} \in \mathbb{R}^n\backslash\lbrace\boldsymbol{0}\rbrace$ 에 대해 $\boldsymbol{Ix} = \lambda\boldsymbol{x} = 1\boldsymbol{x}$ 를 만족합니다. 이 때문에, 단위 행렬의 유일한 eigenspace $E_1$ 는 n차원을 span하며, $\mathbb{R}^n$ 의 n개의 standard basis vectors는 $\boldsymbol{I}$ 의 eigenvectors 입니다.
다음은 Eigenvalues와 eigenvectors에 관한 유용한 속성들을 보여줍니다.
- 행렬 $\boldsymbol{A}$ 와 이 행렬의 전치인 $\boldsymbol{A}^\top$ 은 동일한 eigenvalue를 가지지만, 같은 eigenvector를 가지는 것은 아닙니다.
- 아래의 식으로 인해, eigenspace $E_\lambda$ 는 $(\boldsymbol{A}-\lambda\boldsymbol{I})$ 의 null space 입니다.
- Similar matrices (definition 2.22)는 동일한 eigenvalues를 갖습니다. 따라서, linear mapping $\Phi$ 는 이 mapping의 trasformation matrix의 basis에 독립적인 eigenvalues를 갖습니다. 이러한 성질 때문에 eigenvalues는, determinant와 trace와 함께, linear mapping의 핵심적인 특성 파라미터이며 basis change에도 변하지 않습니다.
- Symmetric이면서 positive definite인 행렬은 항상 positive, real eigenvalues를 갖습니다.
Example 4.5 (Computing Eigenvalues, Eigenvectors, and Eigenspaces)
\[\boldsymbol{A} = \begin{bmatrix}4&2\\1&3\end{bmatrix} \tag{4.28}\]
다음의 $2\times2$ 행렬의 eigenvalues와 eigenvectors를 찾아보도록 하겠습니다.Step 1: Characteristic Polynomial.
Eigenvector와 eigenvector 의 정의에 의해 $\boldsymbol{Ax} = \lambda\boldsymbol{x}$ ,즉, $(\boldsymbol{A}-\lambda\boldsymbol{I})\boldsymbol{x} = 0$ 을 만족하는 벡터가 존재합니다. $\boldsymbol{x} \neq \boldsymbol{0}$ 이기 때문에, $\boldsymbol{A}-\lambda\boldsymbol{I}$ 의 kernel(null space)는 $\boldsymbol{0}$ 보다 더 많은 요소들을 포함하고 있습니다. 이는 $\boldsymbol{A}-\lambda\boldsymbol{I}$ 의 역행렬이 존재하지 않으며, 따라서, $\det(\boldsymbol{A}-\lambda\boldsymbol{I}) = 0$ 이라는 것을 의미합니다. 그러므로, eigenvalues를 구하기 위해서는 식 (4.22a)의 특성 다항식의 근을 계산해야 합니다.
Step 2: Eigenvalues.
특성 다항식은 다음과 같습니다.
\[\begin{align*} p_{\boldsymbol{A}}(\lambda) &= \det(\boldsymbol{A}-\lambda\boldsymbol{I}) \tag{4.29a} \\ &= \det\left(\begin{bmatrix}4&2\\1&3\end{bmatrix} - \begin{bmatrix}\lambda&0\\0&\lambda\end{bmatrix}\right) = \begin{vmatrix}4-\lambda&2\\1&3-\lambda\end{vmatrix} \tag{4.29b} \\ &= (4-\lambda)(3-\lambda) - 2\cdot1 \tag{4.29c} \end{align*}\]이 특성 방정식을 풀어서 다시 인수분해하면 다음의 식을 얻습니다.
\[p(\lambda) = (4-\lambda)(3-\lambda) - 2\cdot1 = 10-7\lambda+\lambda^2 = (2-\lambda)(5-\lambda) \tag{4.30}\]따라서, 특정 다항식의 근은 $\lambda_1 = 2, \lambda_2 = 5$ 입니다.
Step 3: Eigenvectors and Eigenspaces.
다음의 식을 통해 벡터 $\boldsymbol{x}$ 를 살펴봄으로써 위에서 구한 eigenvalues에 대응되는 eigenvectors를 찾습니다.
\[\begin{bmatrix}4-\lambda&2\\1&3-\lambda\end{bmatrix}\boldsymbol{x} = \boldsymbol{0} \tag{4.31}\]$\lambda = 5$ 일 때, 다음의 식을 얻습니다.
\[\begin{bmatrix}4-5&2\\1&3-5\end{bmatrix}\begin{bmatrix}x_1\\x_2\end{bmatrix} = \begin{bmatrix}-1&2\\1&-2\end{bmatrix}\begin{bmatrix}x_1\\x_2\end{bmatrix} = \boldsymbol{0} \tag{4.32}\]이 homogeneous system을 풀면 다음과 같이 solution space를 얻을 수 있습니다.
\[E_5 = \text{span}\lbrack\begin{bmatrix}2\\1\end{bmatrix}\rbrack \tag{4.33}\]이 eigenspace는 하나의 basis vector를 가지고 있으므로 1차원 입니다.
\[\begin{bmatrix}4-2&2\\1&3-2\end{bmatrix}\boldsymbol{x} = \begin{bmatrix}2&2\\1&2\end{bmatrix}\boldsymbol{x} = \boldsymbol{0} \tag{4.34}\]
위와 유사하게 다음의 homogeneous system 방정식을 $\lambda = 2$ 에 대해 풀면 $\lambda = 2$ 에 대한 eigenvector를 찾을 수 있습니다.이는 $x_2 = -x_1$ 인, 즉, $\begin{bmatrix}1\\ -1\end{bmatrix}$ 와 같은 모든 $\boldsymbol{x} = \begin{bmatrix}x_1\\x_2\end{bmatrix}$ 는 eigenvalue 2의 eigenvector 입니다. 대응되는 eigenspace는 다음과 같습니다.
\[E_2 = \text{span}\lbrack\begin{bmatrix}1\\-1\end{bmatrix}\rbrack \tag{4.35}\]
Example 4.5의 두 eigenspaces $E_5, E_2$ 는 각각 하나의 벡터로 span되므로 1차원입니다. 그러나 definition 4.9에서 설명하듯이 동일한 eigenvalues를 여러 개 가질 수 있고 eigenspace의 차원은 1차원보다 클 수 있습니다.
Definition 4.11
Square matrix $\boldsymbol{A}$ 의 eigenvalues를 $\lambda_i$ 라고 하면, $\lambda_i$ 의 geometric multiplicity(기하적 중복도)는 $\lambda_i$ 의 linearly independent eigenvectors의 수입니다. 즉, $\lambda_i$ 의 eigenvectors에 의해 span되는 eigenspace의 차원입니다.
Example 4.6
행렬 $\boldsymbol{A} = \begin{bmatrix}2&1\\0&2\end{bmatrix}$ 는 두 개의 중복되는 eigenvalues $\lambda_1=\lambda_2=2$ 를 가지고 algebraic multiplicity는 2입니다. 그러나 eigenvalue는 하나의 unit eigenvector $\boldsymbol{x}_1 = \begin{bmatrix}1\\0\end{bmatrix}$ 를 가지므로 geometric multiplicity는 1입니다.
Determinants, eigenvectors, eigenvalues 에 대한 직관적으로 이해하기 위해 다른 linear mapping들을 사용하여 살펴보도록 하겠습니다. 아래의 Figure 4.4는 5개의 transformation matrices $\boldsymbol{A}_1, \dotsc, \boldsymbol{A}_5$ 가 어떻게 적용되는지 보여줍니다.
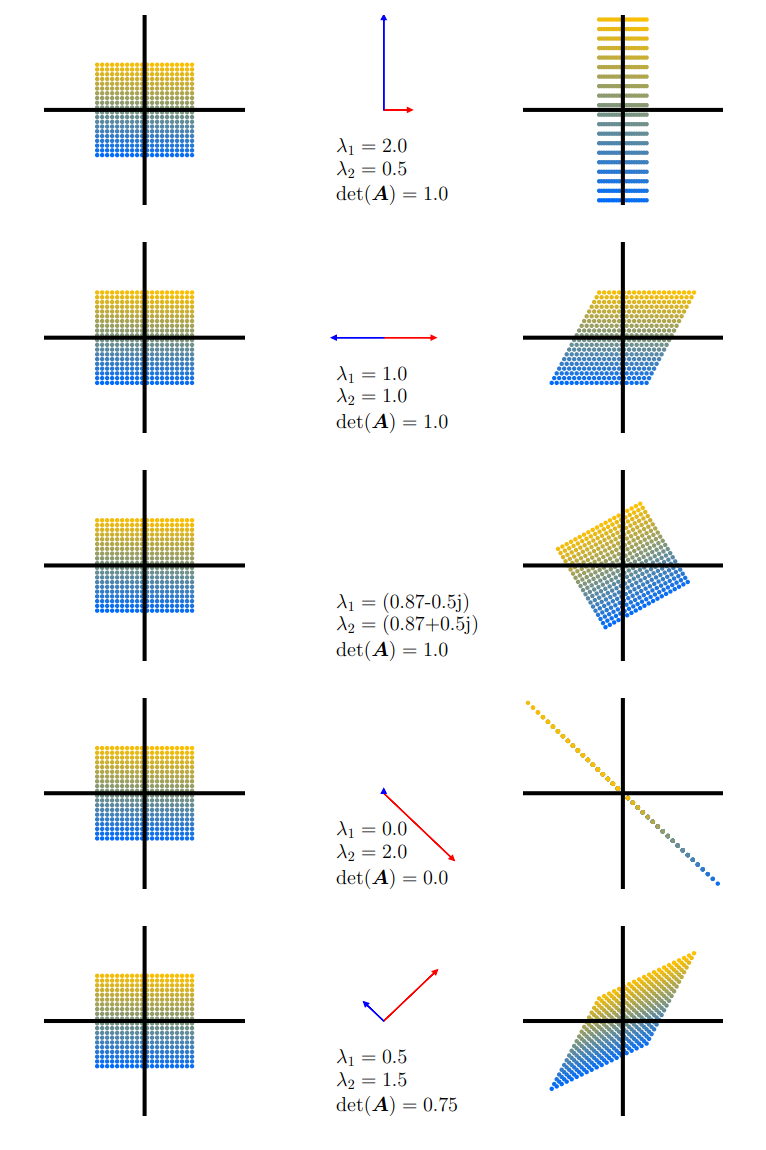
- $\boldsymbol{A}_1 = \begin{bmatrix}\frac{1}{2}&0\\0&2\end{bmatrix}$.
두 고유 벡터의 방향은 $\mathbb{R}^2$ 의 canonical basis vectors, 즉, 두 기본 축에 해당합니다. 수직 축은 2라는 factor(eigenvalue $\lambda_1 = 2$)로 확장되고, 수평 축은 $\frac{1}{2}$ 라는 factor(eigenvalue $\lambda_2 = \frac{1}{2}$)로 압축됩니다. 매핑된 결과의 면적은 보존됩니다 ($\det(\boldsymbol{A}_1) = 1 = 2\cdot\frac{1}{2}$).
- $\boldsymbol{A}_2 = \begin{bmatrix}1&\frac{1}{2}\\0&1\end{bmatrix}$.
이 mapping은 수평 축을 기준으로 위쪽은 오른쪽으로 늘어나고, 아래쪽은 그 반대로 늘어나는 shearing mapping 입니다. 이 mapping의 면적은 보존됩니다 ($\det(\boldsymbol{A}_2) = 1$). Eigenvalue $\lambda_1 = 1 = \lambda_2$ 는 repeated 되고, eigenvectors는 collinear(서로 반대 방향)합니다. 이는 이 mapping이 한 방향(수평축)으로만 작용한다는 것을 가리킵니다.
- $\boldsymbol{A}_3 = \begin{bmatrix}\cos(\frac{\pi}{6})&-\sin(\frac{\pi}{6})\\sin(\frac{\pi}{6})&\cos(\frac{\pi}{6})\end{bmatrix} = \frac{1}{2}\begin{bmatrix}\sqrt{3}& -1\\1&\sqrt{3}\end{bmatrix}$.
행렬 $\boldsymbol{A}_3$ 은 반시계 방향으로 $\frac{\pi}{6}\text{rad} = 30^\circ$ 만큼 회전시킵니다. 그리고 회전 mapping을 반영하는 복소수(허수)인 eigenvalues만을 가집니다. 따라서 그림에서는 eigenvectors를 그리지 않았습니다. 회전하더라도 부피/넓이는 보존되며, 따라서 determinant는 1입니다.
- $\boldsymbol{A}_4 = \begin{bmatrix}1&-1\\ -1&1\end{bmatrix}$.
이 mapping은 2차원을 1차원으로 축소하는 standard basis에서의 mapping을 나타냅니다. Eigenvalues 중 하나가 0이기 때문에 $\lambda_1 = 0$ 에 대응되는 eigenvector(파란색) 방향의 공간은 축소되고, 직교(orthogonal)하는 eigenvector(빨간색)은 $\lambda_2 = 2$ factor로 확장됩니다. 따라서, 면적은 0입니다.
- $\boldsymbol{A}_5 = \begin{bmatrix}1&\frac{1}{2}\\ \frac{1}{2}&1\end{bmatrix}$.
이 mapping은 shear-and-stretch mapping 이며, $|\det(\boldsymbol{A}_5)| = \frac{3}{4}$ 이므로 그 면적이 75%로 감소됩니다. 빨간색으로 표시되는 $\lambda_2$ 의 eigenvector를 따라 1.5 factor로 공간이 확장되고, 직교하는 파란색 eigenvector는 0.5 factor로 축소됩니다.
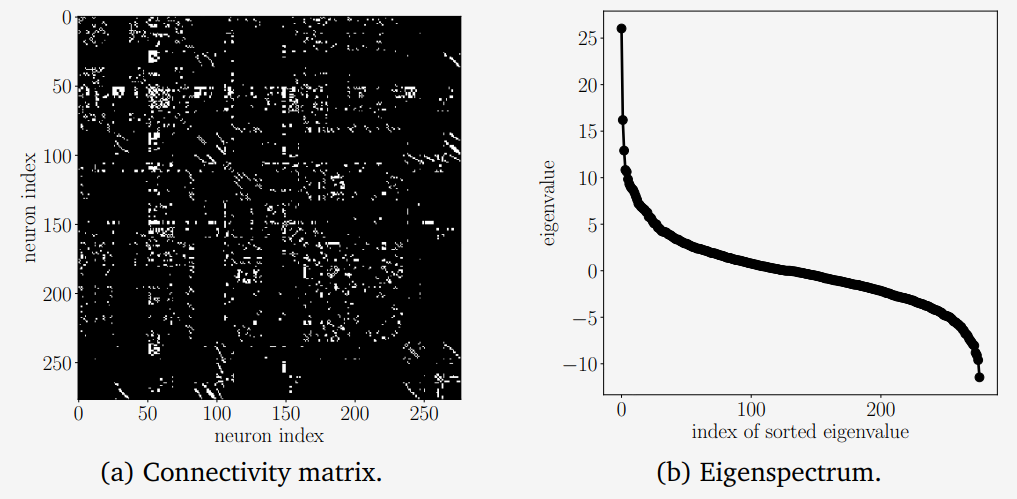
Example 4.7 (Eigenspectrum of a Biological Neural Network)
네트워크 데이터를 분석하고 이로부터 학습하는 방법은 머신러닝 방법에서 필수적인 구성 요소입니다. 네트워크를 이해하는데 핵심은 네트워크 노드 간의 연결성(connectivity) 입니다. 여기서, 두 노드가 연결되어 있는지와는 관계없습니다. 데이터 사이언스 영역에서는 이러한 연결 데이터를 포착하는 행렬을 연구하는 것이 일반적으로 유용합니다.C.Elegans 라는 벌레의 complete neural network를 connectivity/adjacency(인접) matrix $\boldsymbol{A} \in \mathbb{R}^{277\times277}$ 구축한다고 합시다. 각 행과 열은 이 벌레의 뇌의 277개 뉴런 중 하나를 나타냅니다. Connectivity matrix $\boldsymbol{A}$ 에서 뉴런 $i$ 가 뉴런 $j$ 로 시냅스를 통해 전달한다면 $a_{ij} = 1$ 의 값을 가지며, 그렇지 않은 경우에는 $a_{ij} = 0$ 의 값을 갖습니다. Connectivity matrix는 symmetric하지 않으며, 이는 eigenvalues가 실수가 아닐 수 있음을 암시합니다. 그러므로 이 connectivity matrix를 $\boldsymbol{A}_{\text{sym}} := \boldsymbol{A}+\boldsymbol{A}^\top$ 인 symmetrized version으로 계산합니다. 새로운 행렬 $\boldsymbol{A}_{\text{sym}}$ (대각화된 connectivity matrix) 는 위의 그림 (a)에서 보여주고 있습니다. 그리고, 두 뉴런이 연결되어 있다면(white pixel에 해당) 연결 방향과는 관계없이 0이 아닌 값을 가지는 $a_{ij}$ 를 갖습니다. 그림 (b)에서는 대응되는 $\boldsymbol{A}_{\text{sym}}$ 의 eigenspectrum을 보여줍니다. 수평 축은 eigenvalues의 index이며 내림차순으로 정렬되어 있습니다. 수직축은 대응되는 eigenvalue 입니다. S 형태의 eigenspectrum은 많은 생물학적 신경망에서 일반적입니다.
Theorem 4.12. n개의 구별되는 eigenvalues $\lambda_1, \dotsc, \lambda_n$ 을 가지는 행렬 $\boldsymbol{A} \in \mathbb{R}^{n \times n}$ 의 eigenvectors $\boldsymbol{x}_1, \dotsc, \boldsymbol{x}_n$ 는 linearly independent 합니다.
Theorem 4.12는 n개의 eigenvalues를 갖는 행렬의 eigenvectors가 $\mathbb{R}^n$ 의 basis를 형성한다는 것을 말해줍니다.
Definition 4.13
Square matrix $\boldsymbol{A} \in \mathbb{R}^{n\times n}$ 이 n개보다 적은 linearly independent eigenvectors를 가진다면, 행렬 $\boldsymbol{A}$ 를 defective 하다고 합니다.
Non-defective한 행렬이라고 n개의 구별되는 eigenvalues를 필요로 하는 것은 아닙니다. 하지만, $\mathbb{R}^n$ 의 basis를 형성하는 eigenvectors는 필요로 합니다. Defective matrix의 eigenspaces를 살펴보면, 이 eigenspaces의 차원의 합이 n보다 작다는 것을 확인할 수 있습니다. 구체적으로 defective matrix는 algebraic multiplicity $m > 1$ 이고 geometric multiplicity가 $m$ 보다 작은 하나 이상의 eigenvalue $\lambda_i$ 를 갖습니다.
Theorem 4.14. 행렬 $\boldsymbol{A} \in \mathbb{R}^{m\times n}$ 이 주어졌을 때, 항상 symmetric, positivie semidefinite한 행렬 $\boldsymbol{S}\in\mathbb{R}^{n\times n}$ 을 얻을 수 있으며 $\boldsymbol{S}$ 는 다음과 같이 정의됩니다.
\[\boldsymbol{S} := \boldsymbol{A}^\top\boldsymbol{A} \tag{4.36}\]
Theorem 4.14가 성립하는 이유를 이해하면 대칭 행렬(symmetrized matrix)을 어떻게 사용하는지 잘 알 수 있습니다. Symmetric 하다는 것은 $\boldsymbol{S} = \boldsymbol{S}^\top$ 을 의미하고, 이를 식 (4.36)에 대입하면 $\boldsymbol{S} = \boldsymbol{A}^\top\boldsymbol{A} = \boldsymbol{A}^\top(\boldsymbol{A}^\top)^\top = (\boldsymbol{A}^\top\boldsymbol{A})^\top = \boldsymbol{S}^\top$ 이 성립합니다. 또한, positive semidefiniteness (3.2.3장 참조)에 의해 $\boldsymbol{x}^\top\boldsymbol{Sx} \geq 0$ 이므로, 이를 (4.36)에 적용하면 $\boldsymbol{x}^\top\boldsymbol{Sx} = \boldsymbol{x}^\top\boldsymbol{A}^\top\boldsymbol{Ax} = (\boldsymbol{x}^\top\boldsymbol{A}^\top)(\boldsymbol{Ax}) = (\boldsymbol{Ax})^\top(\boldsymbol{Ax}) \geq 0$ 이 성립합니다 (dot product는 제곱의 합을 계산하기 때문).
Theorem 4.15 (Spectral Theorem). 만약 $\boldsymbol{A} \in\mathbb{R}^{n\times n}$ 이 symmetric 하다면 $\boldsymbol{A}$ 의 eigenvectors로 구성된 vector space $V$ 의 orthonormal basis 가 존재하고, 각 eigenvalue는 실수입니다.
Spectral theorem은 대칭 행렬인 $\boldsymbol{A}$ 의 eigendecomposition이 존재(with real eigenvalues)하고, eigenvectors의 ONB(orthonormal basis)를 찾을 수 있다는 것을 알려줍니다. 따라서 $\boldsymbol{D}$ 가 diagonal 이고 $\boldsymbol{P}$ 의 열들이 eigenvectors를 포함할 때, $\boldsymbol{A} = \boldsymbol{PDP}^\top$ 이 성립합니다.
Example 4.8
\[\boldsymbol{A} = \begin{bmatrix}3&2&2\\2&3&2\\2&2&3\end{bmatrix} \tag{4.37}\]행렬 $\boldsymbol{A}$ 가 있을 때, 이 행렬의 특성 다항식은 다음과 같습니다.
\[\begin{align*} p_{\boldsymbol{A}}(\lambda) &= \det(\boldsymbol{A}-\lambda\boldsymbol{I}) \\ &= \det\left(\begin{bmatrix}3-\lambda&2&2\\2&3-\lambda&2\\2&2&3-\lambda\end{bmatrix}\right) \\ &= (3-\lambda)\cdot(3-\lambda)\cdot(3-\lambda) + 2\cdot2\cdot2 + 2\cdot2\cdot2 \\ &\qquad -2\cdot(3-\lambda)\cdot2 - (3-\lambda)\cdot2\cdot2 - 2\cdot2\cdot(3-\lambda) = -\lambda^3 + 9\lambda^2 -15\lambda + 7 \end{align*}\] \[p_{\boldsymbol{A}}(\lambda) = -(\lambda-1)^2(\lambda-7) \tag{4.38}\]따라서, 우리는 이 행렬에 대해 eigenvalues $\lambda_1 = 1, \lambda_2 = 7$ 을 얻을 수 있으며 $\lambda_1$ 은 repeated eigenvalue 입니다. 위에서 살펴본 eigenvectors를 구하는 방법을 따라, 다음의 eigenspaces를 구할 수 있습니다.
\[E_1 = \text{span}\lbrack\underbrace{\begin{bmatrix}-1\\1\\0\end{bmatrix}}_{=:\boldsymbol{x}_1},\underbrace{\begin{bmatrix}-1\\0\\1\end{bmatrix}}_{=:\boldsymbol{x}_2}\rbrack, \quad E_7 = \text{span}\lbrack\underbrace{\begin{bmatrix}1\\1\\1\end{bmatrix}}_{=:\boldsymbol{x}_3} \tag{3.39}\]여기서 $\boldsymbol{x}_3$ 은 $\boldsymbol{x}_1, \boldsymbol{x}_2$ 에 대해 직교한다는 것을 볼 수 있습니다. 반면, $\boldsymbol{x}_1^\top\boldsymbol{x}_2 = 1 \neq 0$ 이므로 $\boldsymbol{x}_1, \boldsymbol{x}_2$ 는 서로 직교하지 않습니다. Spectral Theorem(theorem 4.15)에 의해 orthogonal basis가 존재한다고 합니다. 그러나 우리가 구한 basis 중 하나는 직교하지 않습니다. 하지만, 직교하는 basis를 구성할 수 있습니다.
\[\boldsymbol{A}(\alpha\boldsymbol{x}_1 + \beta\boldsymbol{x}_2) = \boldsymbol{Ax}_1\alpha + \boldsymbol{Ax}_2\beta = \lambda(\alpha\boldsymbol{x}_1 + \beta\boldsymbol{x}_2) \tag{4.40}\]
이러한 basis를 구하기 위해, $\boldsymbol{x}_1, \boldsymbol{x}_2$ 가 서로 같은 eigenvalue $\lambda$ 와 관련된 eigenvector라는 것을 이용합니다. 따라서, 모든 $\alpha, \beta \in \mathbb{R}$ 에 대해 다음의 식이 성립합니다.즉, $\boldsymbol{x}_1, \boldsymbol{x}_2$ 의 모든 linear combination은 $\lambda$ 와 관련된 $\boldsymbol{A}$ 의 eigenvector 입니다. Gram-Schmidt algorithm(3.8.3장 참조)는 이러한 linear combination을 사용하여 한 basis 집합으로부터 orthogonal/orthonomal basis를 구하는 방법입니다. 따라서, 비록 $\boldsymbol{x}_1, \boldsymbol{x}_2$ 이 서로 직교하지 않더라도, Gram-Schmidt algorithm을 사용하여 $\lambda_1=1$ 에 연관된 직교하는 eigenvectors를 찾을 수 있습니다. 이 예제에서는 다음과 같은 eigenvectors를 구할 수 있습니다.
\[\boldsymbol{x}'_1 = \begin{bmatrix}-1\\1\\0\end{bmatrix}, \quad \boldsymbol{x}'_2 = \frac{1}{2}\begin{bmatrix}-1\\-1\\2\end{bmatrix} \tag{4.41}\]이렇게 구한 $\boldsymbol{x}_1’, \boldsymbol{x}_2’$ 는 서로 직교하면서, $\boldsymbol{x}_3$ 과도 직교합니다.
Eigenvalues와 eigenvectors는 determinant와 trace의 개념과 함께 묶으면 매우 유용합니다.
Theorem 4.16. 행렬 $\boldsymbol{A}\in\mathbb{R}^{n\times n}$ 의 determinant 는 eigenvalues의 곱(product)입니다. 즉,
\[\det(\boldsymbol{A}) = \prod_{i=1}^n\lambda_i \tag{4.42}\]이며, 여기서 $\lambda_i$ 는 $\boldsymbol{A}$ 의 (posiibly repeated) eigenvalues 입니다.
Theorem 4.17. 행렬 $\boldsymbol{A}\in\mathbb{R}^{n\times n}$ 의 trace 는 eigenvalues의 합(sum)입니다. 즉,
\[\text{tr}(\boldsymbol{A}) = \sum_{i=1}^n\lambda_i \tag{4.42}\]이며, 여기서 $\lambda_i$ 는 $\boldsymbol{A}$ 의 (posiibly repeated) eigenvalues 입니다.
위의 두 theorem을 기하학 관점으로 살펴보도록 하겠습니다. 예를 들어, 두 개의 linearly independent한 eigenvector $\boldsymbol{x}_1, \boldsymbol{x}_2$ 를 가지는 행렬 $\boldsymbol{A}\in\mathbb{R}^{2\times2}$ 가 있다고 가정해봅시다. 여기서 두 eigenvector를 $\mathbb{R}^2$ 의 ONB(orthonormal basis)라고 가정하면 두 eigenvector는 직교하고 이들이 span하는 square의 넓이는 1입니다. (아래 그림 참조)
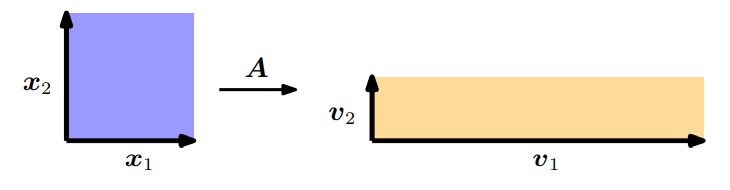
4.1장으로부터 우리는 determinant가 transformation $\boldsymbol{A}$ 에 의해 변경되는 unit square의 넓이를 scaling한다는 것을 알고 있습니다. 그렇기 때문에 이 예제에서 변환되는 넓이를 계산할 수 있습니다. $\boldsymbol{A}$ 를 사용하여 mapping한 eigenvector는 $\boldsymbol{v}_1 = \boldsymbol{Ax}_1 = \lambda_1\boldsymbol{x}_1$, $\boldsymbol{v}_2 = \boldsymbol{Ax}_2 = \lambda_2\boldsymbol{x}_2$ 로 얻을 수 있습니다. 즉, 새로운 벡터 $\boldsymbol{v}_i$ 는 eigenvector $\boldsymbol{x}_i$ 를 단순히 scaling한 것과 같으며, scaling factor는 대응되는 eigenvalues $\lambda_i$ 입니다. $\boldsymbol{v}_1, \boldsymbol{v}_2$ 는 여전히 직교(orthogonal)하기 때문에 이 벡터들이 span하는 사각형의 넓이는 $|\lambda_1\lambda_2|$ 입니다.
위 예제에서 주어진 $\boldsymbol{x}_1, \boldsymbol{x}_2$ 는 orthonormal이며, 이 unit square의 둘레는 $2(1+1)$ 로 직접 계산할 수 있습니다. $\boldsymbol{A}$ 를 사용하여 mapping한 eigenvectors는 직사각형을 만들며, 둘레는 $2(|\lambda_1| + |\lambda_2|)$ 입니다. 따라서, eigenvalues 절댓값 합은 unit square의 둘레가 transformation matrix $\boldsymbol{A}$ 에 의해 어떻게 변하는지 보여줍니다.
Example 4.9 (Google’s PageRank - Webpages as Eigenvalues)
구글은 행렬 $\boldsymbol{A}$ 의 maximal eigenvalue에 해당하는 eigenvector를 사용하여 search를 위한 페이지의 rank를 결정합니다. 이 PageRank 알고리즘의 핵심은 어떤 페이지든 이를 링크하는 페이지의 importance으로 근사할 수 있다는 것입니다. 이를 위해서, 모든 웹사이트가 어떤 페이지를 링크하는지 거대한 directed graph로 나타냅니다. PageRank는 웹사이트 $a_i$ 의 가중치(importance) $x_i \geq 0$ 를 $a_i$ 를 가리키는 페이지의 숫자를 카운트하여 계산합니다. 또한, $a_i$ 로 링크하는 웹사이트의 importance를 고려합니다. 그런 다음 사용자의 navigation behavior은 이 graph의 transition matrix $\boldsymbol{A}$ 로 모델링됩니다. 이 행렬은 누군가가 다른 웹사이트로 도달(클릭)하게 될 확률입니다.
웹사이트의 초기 rank/importance vector를 $\boldsymbol{x}$ 라고 할 때, 행렬 $\boldsymbol{A}$ 는 $\boldsymbol{x}, \boldsymbol{Ax}, \boldsymbol{A^2x}, \dotsc$ 시퀀스로 결국 vector $x^\ast$ 로 수렴합니다. 이 vector를 PageRank라고 부르며, $\boldsymbol{Ax}^\ast = x^\ast$ 를 만족합니다. 즉, 이 벡터는 eigenvalue가 1에 대응되는 $\boldsymbol{A}$ 의 eigenvector입니다. $\boldsymbol{x}^\ast$ 를 정규화(normalization)하면, $\|\boldsymbol{x}^\ast\| = 1$ 이므로, 확률로 해석할 수 있습니다.