Optimization Using Gradient Descent
아래의 (7.4)의 real-valued function의 minimum을 찾는 문제를 살펴보도록 하겠습니다.
\[\min_x f(\boldsymbol{x}) \tag{7.4}\]이때, 함수 $f : \mathbb{R}^d \rightarrow \mathbb{R}$ 는 목적 함수이며 미분은 가능하지만, closed form의 solution을 analytic하게 찾을 수 없다고 가정합니다.
Gradient Descent (경사하강법)은 first-order optimization algorithm 입니다. Gradient descent를 사용하여 함수의 local minimum을 찾으려면, 현재 위치에서 함수의 negative gradient에 비례하는 steps를 수행해야 합니다. 참고로 5.1장에서 gradient는 가장 가파른 상승 방향이라는 것을 알아봤습니다. 다른 유용한 직관으로는 함수가 특정 값(어떤 값 $c\in\mathbb{R}$ 에 대한 $f(\boldsymbol{x})$)에 있는 직선의 집합을 고려하는 것입니다. 이를 등고선(contour lines)이라고 합니다. Gradient는 우리가 최적화하고자 하는 함수의 coutour lines에 직교(orthogonal)하는 방향을 가리킵니다.
이제 multivariate function을 고려해보도록 하겠습니다. 먼저 함수 $f(\boldsymbol{x})$ 표면의 특정 위치 $\boldsymbol{x}_0$ 에서 공을 놓는다고 상상해봅시다. 그러면 이 공은 가장 가파른 하강 방향으로 내려갈 것입니다.
Gradient Descent는 $\boldsymbol{x}_0$ 에서 $f$ 의 negative gradient $-((\nabla f)(\boldsymbol{x}_0))^\top$ 의 방향으로 이동할 때, $f(\boldsymbol{x}_0)$ 이 가장 빠르게 감소한다는 사실을 이용합니다. 교재에서는 이 함수가 미분가능하다고 가정하며, 7.4장에서 좀 더 일반화된 버전을 참조할 수 있습니다.
따라서, 만약 작은 step-size $\gamma \geq 0$ 에 대해,
\[\boldsymbol{x}_1 = \boldsymbol{x}_0 - \gamma ((\nabla f)(\boldsymbol{x}_0))^\top \tag{7.5}\]라면, $f(\boldsymbol{x}_1) \leq f(\boldsymbol{x}_0)$ 이 만족합니다.
이를 이용하여 간단한 gradient descent algorithm을 정의할 수 있습니다. 만약 함수 $f : \mathbb{R}^n \rightarrow \mathbb{R}, \boldsymbol{x} \mapsto f(\boldsymbol{x})$ 의 local optimum $f(\boldsymbol{x}_*)$ 을 찾고자 한다면, 최적화하고자 하는 파라미터의 초기 추측값 $\boldsymbol{x}_0$ 에서 시작하여, 다음의 식을 반복(iterate) 하면 됩니다.
\[\boldsymbol{x}_{i+1} = \boldsymbol{x}_i - \gamma_i ((\nabla f)(\boldsymbol{x}_i))^\top \tag{7.6}\]적절한 step-size $\gamma_i$ 가 있을 때, sequence $f(\boldsymbol{x}_0) \geq f(\boldsymbol{x}_1) \geq \dotsc$ 는 local minimum으로 수렴합니다.
Example 7.1
2차원의 quadratic function 과 이 함수의 gradient가 다음과 같습니다.
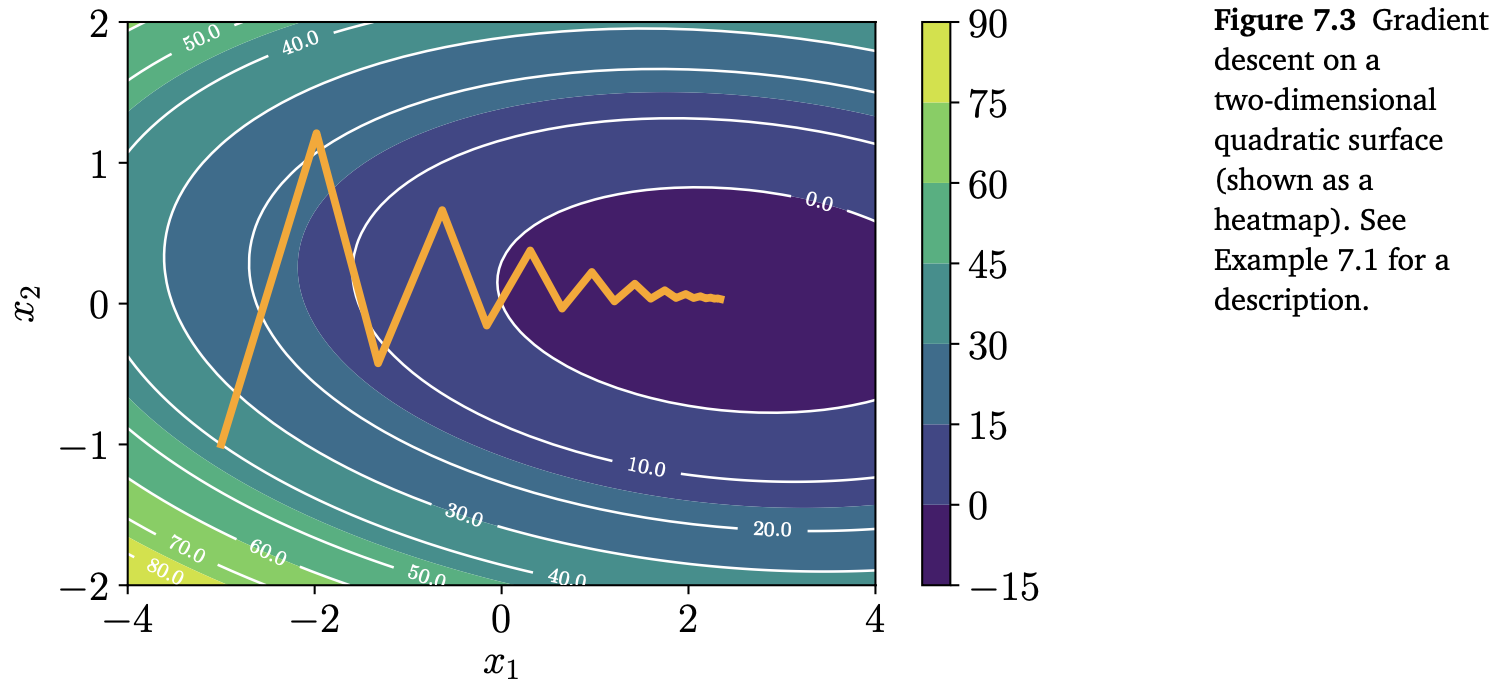
\[f\left(\begin{bmatrix}x_1\\x_2\end{bmatrix}\right) = \frac{1}{2}\begin{bmatrix}x_1\\x_2\end{bmatrix}^\top\begin{bmatrix}2&1\\1&20\end{bmatrix}\begin{bmatrix}x_1\\x_2\end{bmatrix} - \begin{bmatrix}5\\3\end{bmatrix}^\top\begin{bmatrix}x_1\\x_2\end{bmatrix} \tag{7.7}\] \[\nabla f\left(\begin{bmatrix}x_1\\x_2\end{bmatrix}\right) = \begin{bmatrix}x_1\\x_2\end{bmatrix}^\top\begin{bmatrix}2&1\\1&20\end{bmatrix} - \begin{bmatrix}5\\3\end{bmatrix}^\top \tag{7.8}\]초기 위치(initial location) $\boldsymbol{x}_0 = [-3, -1]^\top$ 에서 시작해서, (7.6) 식을 반복하면 minimum value로 수렴하는 sequence of estimates를 얻을 수 있습니다 (아래의 Figure 7.3 참조).
위 그림에서 (7.6)의 gradient descent를 수행하여, $\boldsymbol{x}_0$ 에서 북동쪽 방향으로 $\boldsymbol{x}_1=[-1.98,1.21]^\top$ 에 이어지는 것을 볼 수 있습니다. Gradient descent를 반복수행하면서 $\boldsymbol{x}_2=[-1.32,-0.42]^\top$ 등을 얻을 수 있습니다.
Step-size
Step-size는 learning rate라고도 부릅니다.
Gradient descent에서 good step-size를 선택하는 것이 중요합니다. 만약 step-size가 너무 작다면, gradient descent는 매우 느리게 수렴하게 됩니다. 반대로 step-size가 너무 크다면, gradient descent는 overshoot되거나, 수렴하지 못하거나, 심지어 발산하기도 합니다. 7.1.2장에서는 모멘텀(momentum)에 대해서 논의합니다. 모멘텀은 gradient descent의 불규칙한 동작을 부드럽게 해주며 진동하는 것을 감쇠시켜주는 방법입니다.
Adaptive gradient descent는 함수의 local properties에 따라 각 iteration에서 step-size를 rescale합니다. 여기에는 두 가지 간단한 heuristics 가 있습니다.
- Gradient step 이후 함수 값이 증가하면 step-size가 너무 크다는 것이므로, 이 step을 다시 되돌리고 step-size를 감소시킵니다.
- 함수 값이 감소한다는 것은 step-size가 더 커져도 된다는 것을 의미하므로, step-size를 증가시킵니다.
비록 step을 되돌리는 “undo” step이 리소스를 낭비할 수 있지만, 이러한 heuristic은 monotonic convergence를 보장합니다.
Example 7.2 (Solving a Linear Equation System)
$\boldsymbol{Ax} = b$ 형태의 linear equation의 해를 구할 때, 실제로는 제곱 오차(squared error)를 최소화하는 $\boldsymbol{x}_*$ 를 찾아서 $\boldsymbol{Ax}-\boldsymbol{b} =\boldsymbol{0}$ 의 해를 대략적으로 구합니다. 만약 Euclidean norm을 사용한다면, 제곱 오차 식은 다음과 같습니다.
\[\|\boldsymbol{Ax}-\boldsymbol{b}\|^2 = (\boldsymbol{Ax}-\boldsymbol{b})^\top(\boldsymbol{Ax}-\boldsymbol{b}) \tag{7.9}\]$\boldsymbol{x}$ 에 대한 위 식의 gradient는 다음과 같습니다.
\[\nabla_{\boldsymbol{x}} = 2(\boldsymbol{Ax}-\boldsymbol{b})^\top\boldsymbol{A} \tag{7.10}\]이렇게 구한 gradient를 gradient descent 알고리즘에 바로 사용할 수 있습니다. 그러나, 이러한 특별한 케이스에 대해서는 gradient를 0으로 설정하여 해를 구할 수 있는 anylytic solution이 있으며, 이러한 squared error problem의 해를 구하는 문제는 9장에서 살펴봅니다.
Gradient Descent With Momentum
Figure 7.3에서 설명했듯이, gradient descent의 수렴은 optimization surface의 곡률(curvature)에 따라서 매우 느릴 수 있습니다. 이때 곡률(curvature)은 gradient descent가 계곡의 벽 사이를 뛰어다니며 작은 steps로 optimum에 접근하는 정도입니다. 이러한 수렴을 개선하기 위해 제안된 방법은 gradient descent에 약간의 memory를 제공하는 것입니다.
Gradient descent with momentum은 이전 반복 단계에서 발생한 것을 기억하는 additional term을 도입한 방법입니다. 이렇게 추가된 term은 진동을 감쇠시키고 gradient updates가 부드러워지도록 합니다. 공으로 비유하자면, momentum term은 방향을 바꾸지 않으려는 무거운 공의 특징이라고 생각할 수 있습니다. 이 아이디어는 이동 평균(moving average)를 구현하기 위해서 추가적인 memory를 사용하여 gradient update를 수행합니다. 이 momentum-based method는 각 iteration $i$ 에서 update $\nabla\boldsymbol{x}_i$ 를 기억하고, 다음 iteration step에서 현재 gradient와 과거의 graidnet의 선형 조합으로 next update를 결정합니다.
\[\begin{align*} \boldsymbol{x}_{i+1} &= \boldsymbol{x}_i - \gamma_i((\nabla f)(\boldsymbol{x}_i))^\top + \alpha\nabla\boldsymbol{x}_i \tag{7.11} \\ \nabla\boldsymbol{x}_i &= \boldsymbol{x}_i - \boldsymbol{x}_{i+1} = \alpha\nabla\boldsymbol{x}_{i-1} - \gamma_{i-1}((\nabla f)(\boldsymbol{x}_{i-1}))^\top \tag{7.12} \end{align*}\]이때, $\alpha \in [0,1]$ 입니다.
때때로, 우리는 대략적인 gradient만을 알 수 있습니다. 이러한 경우, momentum term은 gradient의 다양한 noisy estimates를 평균화하기 때문에 유용합니다. Approximate gradient를 얻는 한 가지 유용한 방법은 stochastic approximation을 사용하는 것인데, 바로 아래에서 살펴보도록 하겠습니다.
Stochastic Gradient Descent
Gradient 연산은 시간이 오래 걸립니다. 그러나, 종종 조금 더 “cheap”한 gradient approximation를 찾는 것이 가능합니다. Gradient를 근사하는 것은 실제 gradient와 거의 같은 방향을 가리키는 한 유용하게 사용할 수 있습니다.
Stochastic gradient descent (SGD)는 미분가능한 함수들의 합으로 쓰여진 목적 함수를 최소화하기 위한 gradient descent 방법의 확률적 근사(stochastic approximation) 입니다. ‘Stochastic’이라는 단어는 실제 gradient를 정확히 알지는 못하지만, 대신 gradient에 대한 noisy approximation만 알고 있다는 사실을 의미합니다. Approximate gradients의 확률 분포를 제한함으로써 SGD가 수렴한다는 것을 이론적으로 보장할 수 있습니다.
머신러닝에서 $n = 1,\dotsc,N$ 으로 주어진 data points가 주어졌을 때, 우리는 보통 각 example $n$ 에서 발생한 loss $L_n$ 의 합을 목적 함수로 고려합니다. 수학적으로 표기하면, 목적 함수는 다음과 같습니다.
\[L(\boldsymbol{\theta}) = \sum_{n=1}^N L_n(\boldsymbol{\theta}) \tag{7.13}\]위 식에서 $\boldsymbol{\theta}$ 는 관심있는 파라미터들의 벡터이며, 우리는 $L$ 을 최소화하는 $\boldsymbol{\theta}$ 를 찾는 것이 목적입니다. 이러한 목적 함수의 예로는 9장의 regression에서 사용되는 negative log-likelihood이며, 이는 각각의 examples의 log-likelihoods의 합으로 표현됩니다. 그 표현식은 다음과 같습니다.
\[L(\boldsymbol{\theta}) = -\sum_{n=1}^N \log p(y_n|\boldsymbol{x}_n,\boldsymbol{\theta}) \tag{7.14}\]위 식에서 $\boldsymbol{x}_n$ 은 training inputs 이며, $y_n$ 은 training targets, $\boldsymbol{\theta}$ 는 regression model의 파라미터입니다.
이전에 소개한 standard gradient descent는 “batch” optimization method 입니다. 즉, 최적화는 모든 training set을 사용하여 아래의 (7.15)에 대응되는 파라미터 벡터를 업데이트합니다.
\[\boldsymbol{\theta}_{i+1} = \boldsymbol{\theta}_i - \gamma_i(\nabla L(\boldsymbol{\theta}_i))^\top = \boldsymbol{\theta}_i - \gamma_i\sum_{n=1}^N(\nabla L_n(\boldsymbol{\theta}_i))^\top \tag{7.15}\]여기서 gradient의 합을 계산하려면 모든 $L_n$ 함수에서 gradient를 구하는 갑비싼 비용이 필요할 수 있습니다. 만약 training set가 거대하거나 간단한 공식이 존재하지 않는다면 gradient의 합을 평가하는 것은 비용이 매우 큽니다.
식 (7.15)에서 $\sum_{n=1}^N(\nabla L_n(\boldsymbol{\theta}_i))$ term을 살펴보겠습니다. 여기서 우리는 $L_n$ 의 더 작은 집합들의 합을 취하여 연산량을 줄일 수 있습니다. 모든 $L_n, n=1,\dotsc,N$ 을 사용하는 batch gradient descent와 대조적으로, mini-batch gradient descent에서는 무작위로 $L_n$ 의 subset을 선택합니다. 극단적으로 gradient를 평가하기 위해서 단 하나의 $L_n$ 을 선택할 수도 있습니다.
데이터의 subset을 취하는 것이 왜 합리적이냐에 대한 핵심은, gradient descent가 수렴하기 위해서는 gradient가 오직 실제 gradient의 unbiased estimate이면 되기 때문입니다. 실제로 $\sum_{n=1}^N(\nabla L_n(\boldsymbol{\theta}_i))$ term은 기댓값(expected value, 6.4.1장)의 경험적 추정치(empirical estimate)입니다. 그러므로, 데이터의 subsample을 사용하는 것과 같이, gradient descent가 수렴은 기댓값의 unbiased empirical estimate로 충분합니다.
왜 approximate gradient를 사용할까요? 주요 이유는 CPU/GPU 메모리의 크기 또는 연산 시간의 제한과 같은 실제 구현에서의 제약 때문입니다. Empirical means를 추정할 때 표본의 크기를 생각했던 것과 같은 방식으로 gradient를 추정하는 데 사용되는 subset의 크기를 생각할 수 있습니다. 큰 mini-batch size는 더 정확한 gradient의 추정을 가능하게 하고, 파라미터 업데이트의 분산(variacne)를 감소시킵니다. 게다가, 큰 mini-batches는 cost와 gradient의 vectorized implementations에서 고도로 최적화된 행렬 연산의 이점을 가집니다. 분산의 감소는 좀 더 안정적인 수렴을 이끌어내지만, 각 gradient 계산 비용은 더 커집니다.
대조적으로, 더 작은 mini-batches는 빠른 추정이 가능합니다. Mini-batch size를 작게 유지하면, gradient estimate의 noise로 인해 bad local optima를 벗어날 수 있습니다. 그렇지 않다면, bad local optima에 갇히게 됩니다.
머신러닝에서 최적화 방법은 training data에 대한 목적 함수를 최소화함으로써 학습하는데 사용되지만, 최종적인 목적은 generalization performance를 향상시키는 것입니다(8장에서 다룸). 머신러닝의 목표는 목적 함수의 최소값을 정확하게 추정하는 것이 아니기 때문에 mini-batch를 사용하는 approximate gradients가 널리 사용되고 있습니다.
SGD는 수 백만의 이미지에 대해서 deep neural network를 학습시키거나, topic models, 강화학습, 또는 large-scale Gaussian process models와 같은 대규모 머신러닝 문제에서 매우 효과적입니다.