Problem Formulation
Observation noise가 존재하기 때문에, 우리는 확률적 접근 방식을 선택하고, likelihood function을 사용하여 노이즈를 명시적으로 모델링합니다. 구체적으로, 이번 챕터를 통해 아래의 likehood function을 가진 regression 문제를 고려합니다.
\[p(y|\boldsymbol{x}) = \mathcal{N}(y|f(\boldsymbol{x}),\sigma^2) \tag{9.1}\]여기서 $\boldsymbol{x}\in\mathbb{R}^D$ 는 inputs이고 $y\in\mathbb{R}$ 은 noisy function values (targets) 입니다. (9.1) 식을 가지고 $\boldsymbol{x}$ 와 $y$ 의 functional relationship은 다음과 같이 주어집니다.
\[y = f(\boldsymbol{x}) + \epsilon \tag{9.2}\]여기서 $\epsilon\sim\mathcal{N}(0,\sigma^2)$ 는 independent, identically distributed(i.i.d.) 가우시안 측정 노이즈이며, 평균은 0, 분산은 $\sigma^2$ 입니다. 우리의 목적은 생성된 데이터와 일반화가 잘하는 알지 못하는 함수 $f$ 에 최대한 가까운 함수를 찾는 것입니다.
이 장에서는 parametric model에 초점을 맞춥니다. 즉, 매개변수화된 함수를 선택하고 데이터를 잘 모델링하는 파라미터 $\boldsymbol{\theta}$ 를 찾습니다. 우선 노이즈의 분산 $\sigma^2$ 는 알고 있다고 가정하고, 모델의 파라미터 $\boldsymbol{\theta}$ 를 학습하는 데에만 초점을 맞춥니다. Linear regression에서는 파라미터 $\boldsymbol{\theta}$ 가 모델에서 선형으로 나타난다고 고려합니다. 따라서, linear regression의 예시는 다음과 같습니다.
\[\begin{align*} &p(y|\boldsymbol{x},\boldsymbol{\theta}) = \mathcal{N}(y|\boldsymbol{x}^\top\boldsymbol{\theta},\sigma^2) \tag{9.3} \\ \Longleftrightarrow &y = \boldsymbol{x}^\top\boldsymbol{\theta} + \epsilon, \quad \epsilon\sim\mathcal{N}(0,\sigma^2) \tag{9.4} \end{align*}\]여기서 $\boldsymbol{\theta}\in\mathbb{R}^D$ 는 우리가 찾고자하는 파라미터입니다. (9.4)에서 보여주는 함수 클래스는 원점을 통과하는 직선입니다. (9.4) 식에서 $f(\boldsymbol{x})=\boldsymbol{x}^\top\boldsymbol{\theta}$ 함수로 선택했습니다.
(9.3) 식의 likelihood 는 $\boldsymbol{x}^\top\boldsymbol{\theta}$ 에서 평과되는 $y$ 의 확률 밀도 함수(probability density function) 입니다. 불확실성의 유일한 원인은 observation noise 에서만 발생한다는 것에 유의합니다. 즉, 식 (9.3) 에서 $\boldsymbol{x}$ 와 $\boldsymbol{\theta}$ 는 알고 있다고 가정합니다. 이러한 관측 노이즈가 없다면 $\boldsymbol{x}$ 와 $y$ 의 관계는 deterministic 이며 (9.3)은 Dirac delta 가 됩니다.
Example 9.1
$x$ , $\theta \in\mathbb{R}$ 에 대해 (9.4)의 linear regression model은 직선(linear function)을 나타내며, 파라미터 $\theta$ 는 그 직선의 기울기입니다. 아래에 있는 Figure 9.2(a) 에서 다른 $\theta$ 에 대한 몇 가지 함수들을 보여줍니다.
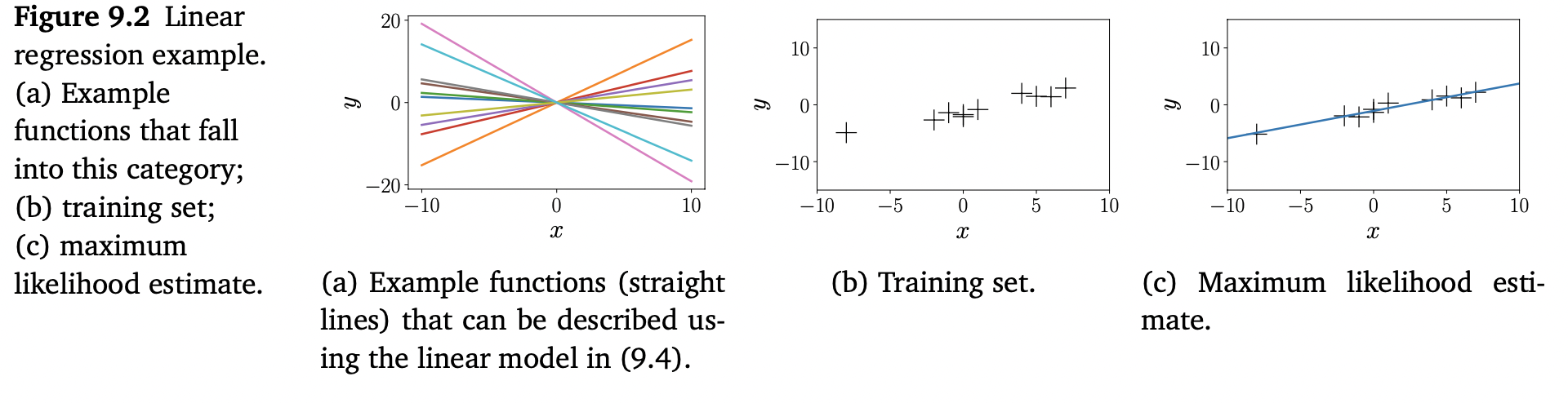
(9.3)~(9.4)의 linear regression model은 파라미터가 linear일 뿐만 아니라 inputs $x$ 도 linear 입니다. Figure 9.2(a)는 이러한 함수들의 예를 보여줍니다. 나중에 nonlinear trasformations $\phi$ 에 대한 $y=\phi^\top(\boldsymbol{x})\boldsymbol{\theta}$ 함수 또한 linear regression model 이라는 것을 볼 것 입니다. 이는 “linear regression” 이 “linear in the parameters” 인 모델을 지칭하기 때문입니다. 즉, linear regression 모델은 input features의 linear combination으로 표현되는 모델입니다. 여기서 “feature”는 inputs $\boldsymbol{x}$ 의 $\phi(\boldsymbol{x})$ 입니다.
다음 장에 이어서 어떻게 good parameters $\boldsymbol{\theta}$ 를 찾는지 자세하게 논의하고, 이 파라미터들이 잘 동작하는지 평가하는 방법에 대해서도 알아보겠습니다.