Intro
머신러닝 알고리즘들은 컴퓨터에서 구현 및 실행되기 때문에 수학 공식들은 numerical optimization methods로 표현됩니다. 7장에서는 머신러닝 모델을 훈련하기 위한 기본적인 수치적 방법들(numerical methods)을 설명합니다. 머신러닝 모델을 학습하는 것은 일반적으로 좋은(good) 파라미터 집합을 찾는 것인데, 여기서 “good”이라는 개념은 목적 함수(objective function)이나 Probabilistic model에 의해 결정됩니다(Probabilistic model은 교재의 2번째 part에서 다룹니다). 목적 함수가 주어졌을 때, 최적화 알고리즘(optimization algorithms)을 사용하여 최고의 값을 찾을 수 있습니다.
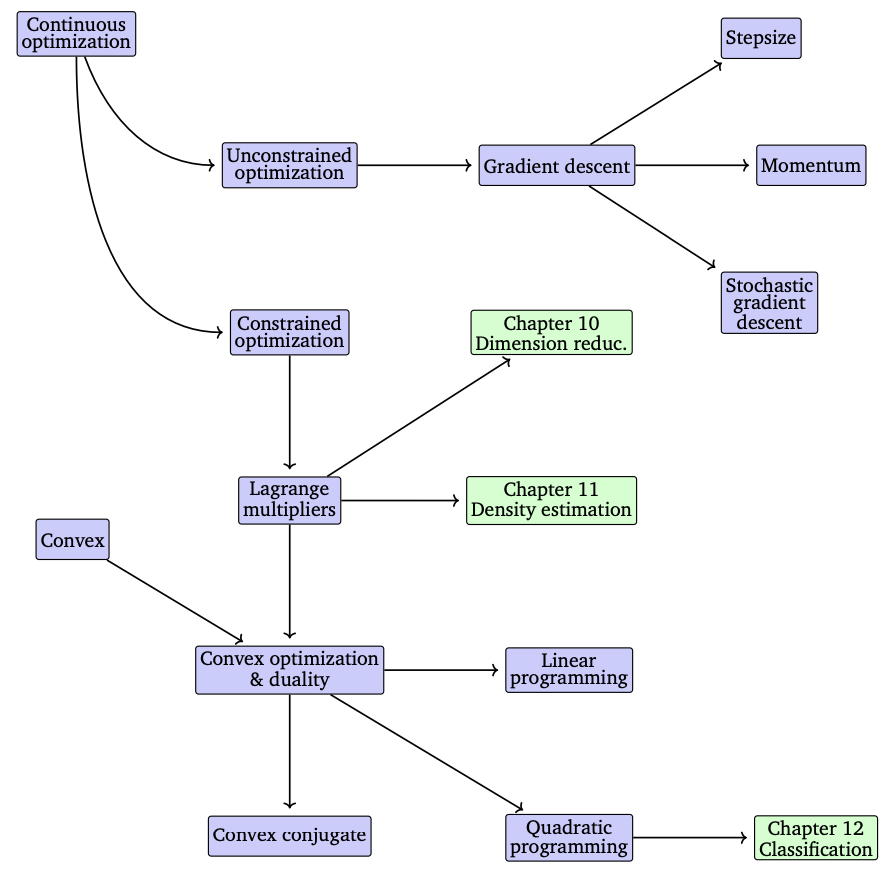
7장에서는 continuous optimization의 두 가지 main branches인 unconstrained optimization과 constranined optimization을 다룹니다 (위 그림 참조). 7장에서는 다루는 모든 목적 함수가 미분이 가능하다고 가정합니다. 따라서, 각 위치에서 gradient를 구할 수 있고, 이는 최적의 값을 찾는데 도움이 됩니다.
관례상, 머신러닝에서 대부분의 목적 함수들은 최소화하도록 되어 있습니다. 즉, 최적의 값이 바로 최솟값입니다. 직관적으로, 최적의 값을 찾는 것은 목적 함수의 valleys를 찾는 것과 같으며, gradient는 우리를 오르막길로 이끌어주는 역할을 합니다. 이러한 아이디어는 (gradient의 반대 방향) 내리막길로 이동하여 가장 깊은 지점을 찾는 것입니다.
Unconstrained optimization(제약이 없는 최적화)의 경우에는, 방금 설명한 개념만이 필요하지만 몇 가지 design choices가 있으며 이는 7.1장에서 논의할 예정입니다.
Constrained optimization(제약이 있는 최적화)의 경우에는 제약(constraints)을 다루기 위해서 다른 개념을 도입하며 이는 7.2장에서 논의합니다.
또한, 7.3장에서는 global opimum에 도달하는 것에 대해 이야기할 수 있는 특별한 문제(convex optimization problems)를 소개합니다.
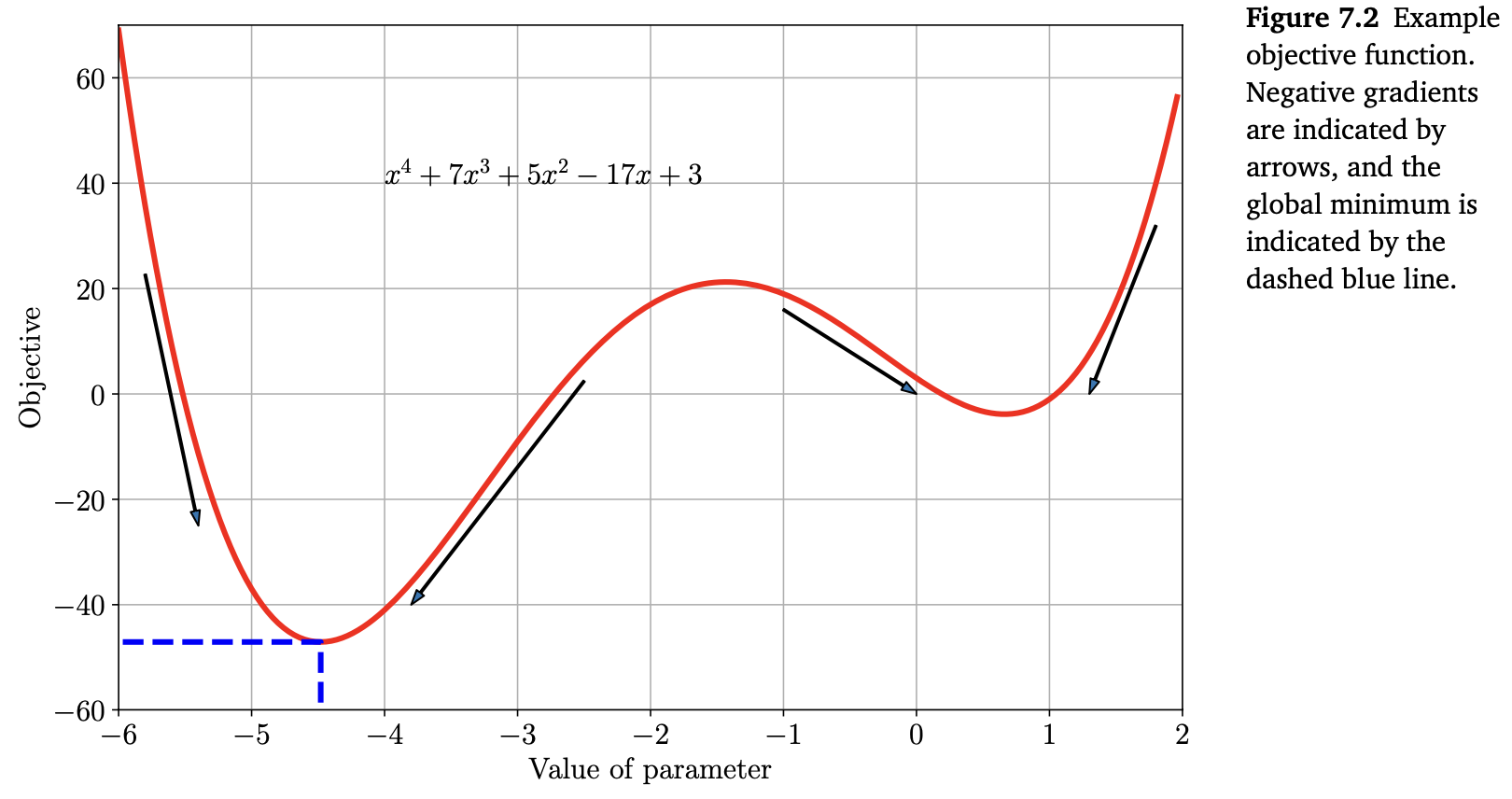
위의 Figure 7.2에 있는 함수를 고려해보겠습니다. 이 함수는 대략 $x=-4.5$ 지점에서 global minimum 을 가지며, 그 값은 약 $-47$ 입니다. 이 함수는 “smooth”하기 때문에 gradients를 사용하여 왼쪽 또는 오른쪽으로 이동하면서 최솟값을 찾을 수 있습니다. 또 다른 local minimum 이 $x = 0.7$ 지점에서 존재하기 때문에, 여기서는 우리가 correct bowl에 있다고 가정합니다.
우리는 도함수(derivative)를 구한 뒤, 0과 같다고 놓고 이를 풀면 stationay point의 위치를 모두 구할 수 있습니다.
\[l(x) = x^4 + 7x^3 + 5x^2 - 17 + 3 \tag{7.1}\]위 식에 대응되는 gradient는 다음과 같습니다.
\[\frac{\mathrm{d}l(x)}{\mathrm{d}x} = 4x^3 + 21x^2 + 10x - 17 \tag{7.2}\]3차식이므로, 일반적으로 위 식을 0으로 만드는 해는 3개가 존재합니다. 위 식에서는 2개의 minimum과 1개의 maximum($x \approx -1.4$)이 있습니다. Stationary point가 minimum인지 maximum인지 확인하려면, 2차 도함수를 구하고 2차 도함수가 stationary point에서 양수인지 음수인지 확인해야 합니다. 위의 예제에서 2차 도함수는 다음과 같습니다.
\[\frac{\mathrm{d}^2l(x)}{\mathrm{d}x^2} = 12x^2 + 42x + 10 \tag{7.3}\]Figure 7.2에서 봤듯이, $x = -4.5, -1.4, 0.7$ 에서 중간에 있는 지점이 maximum이고, 나머지 두 지점이 minimum이라는 것을 확인할 수 있습니다.
위 예제에서 x값을 계산이 아닌 그래프를 통해서 추정했습니다. 방금 살펴본 예제와 같이 차수가 낮은 다항식에서는 이러한 방법, 즉, analytic solution이 가능합니다. 하지만 일반적으로 analytic solution을 찾을 수 없기 때문에 $x_0 = -6$ 과 같은 초깃값에서 시작하여 negative gradient를 따라가면서 찾아야 합니다.
$x_0 = -6$ 에서의 Negative gradient(음의 기울기)는 오른쪽 방향으로 가야한다는 것을 가리키지만, 얼마만큼 가야하는 지(called the step-size)를 나타내지는 않습니다. 게다가, 만약 오른쪽에서 시작했다면(e.g., $x_0=0$) negative gradient는 wrong minimum으로 가도록 만듭니다. Figure 7.2는 $x>-1$ 일 때, negative gradient가 그림의 오른쪽에 있는 minimum(더 큰 objective value)으로 향하도록 한다는 것을 보여줍니다.
7.3장에서는 convex function이라고 부르는 함수들에 대해 배울텐데, 이러한 함수들은 최적화 알고리즘의 starting point에 대해 종속되지 않습니다. 모든 Convex function에서 모든 local minimum들은 global minimum입니다. 많은 머신러닝의 최적화 함수들은 convex하도록 설계되었으며, 12장에서 이러한 예제들을 살펴봅니다.
방금까지 살펴본 내용들은 gradient, descent direction(하강 방향), optimal values들을 시각화할 수 있는 1차원 함수에 대해서 살펴봤습니다. 7장의 나머지 부분에서는 동일한 아이디어를 더 높은 차원으로 확장합니다. 1차원에서만 시각화할 수 있고, 몇몇 개념들은 고차원에서 일반화되지 않기 때문에 주의를 기울여야 합니다.