Empirical Rist Minimization
머신러닝에서 “learning” 파트는 training data를 기반으로 파라미터를 추정하는 것으로 요약할 수 있습니다.
8.2장에서는 predicator가 함수인 경우에 대해 살펴보고, 8.3장에서는 predicator가 probabilistic models인 경우를 살펴봅니다. 8.2장에서는 support vector machine(12장 참조)의 제안으로 유명해진 empirical risk minimization(ERM)의 아이디어를 설명합니다. 그러나, ERM의 일반적인 원칙은 널리 적용할 수 있으며, probabilistic models를 명시적으로 구성하지 않고도 learning이 무엇인가에 대한 질문에 답을 할 수 있습니다. Main design choices는 아래와 같이 4가지가 있으며, 하위 섹션에서 이에 대해 자세히 다루어보도록 하겠습니다.
- Section 8.2.1 What is the set of functions we allow the predictor to take?
- Section 8.2.2 How do we measure how well the predictor performs on the training data?
- Section 8.2.3 How do we construct predictors from only training data that performs well on unseen test data?
- Section 8.2.4 What is the procedure for searching over the space of models?
Hypothesis Class of Functions
N개의 examples $\boldsymbol{x}_n\in\mathbb{R}^D$ 와 대응되는 scalar labels $y_n\in\mathbb{R}$ 이 주어졌다고 가정해봅시다. 그리고 $(\boldsymbol{x}_1,y_1),\dotsc,(\boldsymbol{x}_N,y_N)$ 쌍을 얻는 supervised learning setting을 고려합니다. 이러한 데이터가 주어졌을 때, $\boldsymbol{\theta}$ 로 매개변수화되는 predictor $f(\cdot,\boldsymbol{\theta}): \mathbb{R}^D\rightarrow\mathbb{R}$ 을 추정하고자 합니다. 우리는 데이터에 잘 맞는(fit) good parameter $\boldsymbol{\theta}^*$ 를 찾기를 원합니다. 즉, 다음의 식을 만족하는 파라미터를 찾기를 원합니다.
\[f(\boldsymbol{x}_n, \boldsymbol{\theta}^*) \approx y_n \quad\text{for all}\quad n=1,\dotsc,N \tag{8.3}\]이 섹션에서, $\hat{y}_n = f(\boldsymbol{x}_n,\boldsymbol{\theta}^*)$ 는 predictor의 output을 표현합니다.
Example 8.1
Empirical risk minimization을 설명하기 위해서 일반적인 least-squares regression 문제를 소개합니다. Regression에 대한 전반적인 내용은 9장에서 다룹니다. Label $y_n$ 이 real-valued 일 때, predictors에 대한 함수 클래스로 affine functions 집합을 많이 선택합니다. 여기서 우리는 추가적인 unit feature $x^{(0)}=1$ 을 $\boldsymbol{x}_n$ 연결하여 $\boldsymbol{x}_n=[1,x_n^{(1)},x_n^{(2)},\dotsc,x_n^{(D)}]^\top$ 으로 좀 더 compact한 표기법을 선택합니다. 이에 따라, 파라미터 벡터는 $\boldsymbol{\theta}=[\theta_0,\theta_1,\theta_2,\dotsc,\theta_D]$ 로 표기하며, 따라서, predictor를 다음과 같이 linear function으로 작성할 수 있습니다.
\[f(\boldsymbol{x}_n,\boldsymbol{\theta}) = \boldsymbol{\theta}^\top\boldsymbol{x}_n \tag{8.4}\]위의 linear function은 아래의 affine model로 동등하게 표현할 수도 있습니다.
\[f(\boldsymbol{x}_n,\boldsymbol{\theta}) = \theta_0 + \sum_{d=1}^D \theta_d x_n^{(d)} \tag{8.5}\]이렇게 정의된 predictor는 single example $\boldsymbol{x}_n$ 을 표현하는 features의 벡터를 input으로 받고, 실수(real-valued) output을 생성합니다. 즉, $f:\mathbb{R}^{D+1}\rightarrow\mathbb{R}$ 입니다. 8.1장에서 살펴본 예제 그림은 predictor가 직선이었는데, 이는 우리가 affine function으로 가정했다는 것을 의미합니다.
Linear function 대신 non-linear function을 predictor로 고려할 수도 있습니다. Neural network의 최근 발전으로 복잡한 non-linear function class들을 효율적으로 계산할 수 있습니다.
함수 클래스가 주어지면, 이제 우리는 good predictor를 찾는 것을 원합니다. 다음 섹션에서 empirical risk minimization의 두 번째 요소인 predictor가 training data에 잘 맞는지 측정하는 방법에 대해 살펴보겠습니다.
Loss Function for Training
특정 example에 대한 label $y_n$ 을 고려해봅시다. 그리고 $\boldsymbol{x}_n$ 을 기반으로 대응되는 예측(prediction) $\hat{y}_n$ 을 고려해봅시다. 데이터에 잘 맞는다는 것을 정의하려면 우리는 ground truth label(정답 label)과 input에 대한 prediction(예측)을 입력으로 받아서 non-negative number(loss라고 칭하는)를 생성하는 loss function $\ell(y_n,\hat{y}_n)$ 을 정의할 필요가 있습니다. 이 함수는 prediction을 ground truth와 비교했을 때 error가 어느정도인지 나타냅니다. Good parameter vector $\boldsymbol{\theta}^*$ 를 찾는다는 우리의 목표는 N개의 training examples 집합에 대한 평균 loss를 최소화하는 것입니다.
머신러닝에서 일반적으로 사용되는 한 가지 가정은 examples 집합 $(\boldsymbol{x}_1,y_1),\dotsc,(\boldsymbol{x}_N,y_N)$ 이 independent and identically distributed (i.i.d.) 라는 것입니다. Independent라는 단어는 두 data points $(\boldsymbol{x}_i,y_i)$ 와 $(\boldsymbol{x}_j,y_j)$ 가 서로 통계적으로 서로 의존하지 않는다는 것을 의미하며, 이는 empirical mean이 모집단 평균(population mean)의 good estimate라는 것을 의미합니다 (6.4.1장 참조). 이는 training data에 대한 loss의 empirical mean을 사용할 수 있다는 것을 의미합니다. 주어진 training data ${(\boldsymbol{x}_1,y_1),\dotsc,(\boldsymbol{x}_N,y_N)}$ 에 대해서, example matrix의 표기법 $\boldsymbol{X} := [\boldsymbol{x}_1,\dotsc,\boldsymbol{x}_N]^\top\in\mathbb{R}^{N\times D}$ 와 label vector 표기법 $\boldsymbol{y} := [y_1,\dotsc,y_N]^\top\in\mathbb{R}^N$ 을 도입하겠습니다. 이러한 matrix notation을 사용하면, average loss는 다음과 같이 주어집니다.
\[\boldsymbol{R}_{emp}(f,\boldsymbol{X},\boldsymbol{y}) = \frac{1}{N}\sum_{n=1}^N\ell(y_n,\hat{y}_n) \tag{8.6}\]여기서 $\hat{y}_n = f(\boldsymbol{x}_n,\boldsymbol{\theta})$ 입니다. (8.6) 식은 empirical risk 라고 불리며, 3개의 인자 predicator $f$, data $\boldsymbol{X},\boldsymbol{y}$ 에 의존합니다. 학습에서 이러한 일반적인 전략을 empirical risk minimization 이라고 부릅니다.
Example 8.2 (Least-Squares Loss)
이전 예제 문제에 이어서 least-squares regression을 살펴보겠습니다. Least-squares regression에서는 training 중 발생하는 error의 cost를 squared loss(제곱 손실) $ell(y_n,\hat{y}_n) = (y_n-\hat{y}_n)^2$ 을 사용하여 측정합니다. 우리는 empirical risk (8.6)을 최소화하고자 하는데, 이 식은 모든 데이터에 대한 평균 손실(average of the losses) 입니다.
\[\min_{\boldsymbol{\theta}\in\mathbb{R}^D}\frac{1}{N}\sum_{n=1}^N(y_n-f(\boldsymbol{x}_n,\boldsymbol{\theta}))^2 \tag{8.7}\]여기서 predictor $\hat{y}_n$ 을 $f(\boldsymbol{x}_n,\boldsymbol{\theta})$ 로 대체했습니다. 이전 예제 문제에서 우리는 linear predicator $f(\boldsymbol{x}_n,\boldsymbol{\theta})=\boldsymbol{\theta}^\top\boldsymbol{x}_n$ 을 선택하였으므로, 다음과 같은 optimization problem을 얻게 됩니다.
\[\min_{\boldsymbol{\theta}\in\mathbb{R}^D}\frac{1}{N}\sum_{i=1}^N(y_n-\boldsymbol{\theta}^\top\boldsymbol{x})^2 \tag{8.8}\]위 식을 matrix form으로 다음과 같이 동등하게 표현할 수 있습니다.
\[\min_{\boldsymbol{\theta}\in\mathbb{R}^D}\frac{1}{N}\|\boldsymbol{y}-\boldsymbol{X\theta}\|^2 \tag{8.9}\]이는 least-squares problem 으로 알려져 있습니다. Normal equations를 풀면 이에 대한 closed-form analytic solution이 존재합니다. 이는 9.2장에서 좀 더 자세히 다룰 예정입니다.
우리는 tarining data에서만 잘 동작하는 predictor에는 관심이 없으며, unseen test data에서도 잘 동작하는 predictor를 찾고자 합니다. 보다 공식적으로, 우리는 expected risk 를 최소화하는 predictor $f$ (with parameters fixed)를 찾는 것에 관심이 있습니다.
\[\boldsymbol{R}_{\text{true}}(f) = \mathbb{E}_{\boldsymbol{x},y}[\ell(y,f(\boldsymbol{x}))] \tag{8.10}\]위 식에서 $y$ 는 label 이고 $f(\boldsymbol{x})$ 는 example $\boldsymbol{x}$ 에 기반한 prediction(예측) 입니다. $\boldsymbol{R}_{\text{true}}(f)$ 표기는 무한한 양의 데이터에 액세스할 수 있는 경우 이것이 true risk라는 것을 나타냅니다. 기댓값(expectation)은 가능한 모든 data 및 labels 집합에 대한 것입니다. 여기에는 expected risk를 최소화하고자 하는 우리의 바람에서 발생하는 두 가지 practical questions이 있는데, 이에 대해서는 다음의 두 섹션에서 다룹니다.
- How should we change out training procedure to generalize well?
- How do we estimate expected risk from (finite) data?
Regularization to Reduce Overfitting
이번에는 empirical risk minimization의 일반화(generalization)에 대한 내용에 대해 살펴보겠습니다 (expected risk를 대략적으로 최소화할 수 있도록). 머신러닝 predicator를 학습하는 것의 목적이 unseen data에서도 잘 동작해야 한다라는 것을 떠올려 봅시다. 즉, predicator가 일반화되어야 합니다. 이는 전체 dataset의 일부분을 사용하여 unseen data로 시뮬레이션할 수 있습니다. 이러한 데이터 집합을 test set 이라고 합니다. 충분히 많은 predicator $f$ 의 함수 클래스가 주어졌다면, 우리는 기본적으로 training data를 기억하여 0의 empirical risk를 얻도록 할 수 있습니다. 이는 training data에 대해서 loss를 최소화하는 데는 효과적일 수 있으나 predictor가 unseen data에 일반화될 것이라고는 기대하지 않습니다. 실제로 유한한 데이터 집합이 있을 때, 이를 training set과 test set으로 나눕니다. Training set은 모델을 학습(fit)할 때 사용되고, (학습하는 동안 머신러닝 알고리즘이 보지 못한) test set은 generalization performance를 평가할 때 사용됩니다.
사용자가 test set을 학습에 사용하지 않는 것이 중요합니다. 아래에서는 아래첨자 $_{\text{train}}$ 과 $_{\text{test}}$ 를 사용하여 각각 training 및 test sets을 나타냅니다. 8.2.4장에서 expected risk를 평가하기 위해 유한한 dataset을 사용하는 아이디어를 다시 한 번 살펴봅니다.
Empirical risk minimization은 overfitting (과적합)으로 이어질 수 있습니다. 즉, predictor가 training data에만 너무 잘 맞고, 새로운 데이터에는 일반화되지 않습니다. Training data의 average loss는 매우 작지만, test set에 대한 average loss는 매우 큰 이러한 일반적인 현상은 데이터는 적고 hypothesis class가 복잡한 경우에 발생하는 경향이 있습니다.
파라미터가 고정된 특정 predictor $f$ 에 대해, overfitting 현상은 training data로부터의 risk estimate $\boldsymbol{R}_{\text{emp}}(f, \boldsymbol{X}_{\text{train}}, \boldsymbol{y}_{\text{train}})$ 이 expected risk $\boldsymbol{R}_{\text{true}}(f)$ 를 과소평가할 때 발생합니다. 우리는 test set에서의 empirical risk $\boldsymbol{R}_{\text{emp}}(f, \boldsymbol{X}_{\text{test}}, \boldsymbol{y}_{\text{test}})$ 를 사용하여 expected risk $\boldsymbol{R}_{\text{true}}(f)$ 를 추정하기 때문에, 만약 test risk가 training risk보다 훨씬 더 크다면, 이는 과적합(overfitting)이라는 것을 나타냅니다. 과적합의 개념은 8.3.3장에서 다시 한 번 살펴볼 예정입니다.
따라서, optimizer가 지나치게 flexible한 predictor를 반환하기 어렵게 만드는 penalty term을 도입하여 the minimizer of empirical risk에 대한 탐색에 다소 편향시킬 필요가 있습니다. 머신러닝에서 이러한 penaly term을 regularization (정규화)라고 칭합니다. 정규화(regularization)은 empirical risk minimization의 accurate solution과 solution의 complexity 사이에서 타협하는 방법입니다.
Example 8.3 (Regularized Least Squares)
정규화(regularization)은 최적화 문제에서 복잡하거나 극단적인 솔루션을 피하는 접근 방법입니다. 가장 간단한 정규화 전략은 이전 예제에서 살펴봤던 아래의 the least-square problem에
\[\min_{\boldsymbol{\theta}}\frac{1}{N}\|\boldsymbol{y}-\boldsymbol{X\theta}\|^2 \tag{8.11}\]오직 $\boldsymbol{\theta}$ 만 연관된 penalty term을 추가하여 “regularized” problem으로 대체하는 것입니다.
\[\min_{\boldsymbol{\theta}}\frac{1}{N}\|\boldsymbol{y}-\boldsymbol{X\theta}\|^2 + \lambda\|\boldsymbol{\theta}\|^2 \tag{8.12}\]추가된 항 $\|\boldsymbol{\theta}\|^2$ 를 regularizer 라고 부르고, 파라미터 $\lambda$ 를 regularization parameter 라고 부릅니다. Regularization parameter는 training set 에서의 loss를 최소화하는 것과 파라미터 $\boldsymbol{\theta}$ 의 크기를 최소화하는 것을 절충합니다. 과적합에 빠지면, 일반적으로 파라미터 값의 크기가 상대적으로 커지는 경우가 있습니다.
Regularization term은 때때로 penalty term 이라고 불리며, 이는 벡터 $\boldsymbol{\theta}$ 를 원점에 더 가깝게 편향시킵니다. Regularization의 개념은 probabilistic models 에서 파라미터의 prior probability로 나타납니다. 6.6장에서 posterior distribution(사후 분포)가 prior distribution(사전 분포)와 동일한 형태가 되기 위해서는, prior와 likelihood가 conjugate일 필요가 있다고 했습니다. 이 개념은 8.3.2장에서 다시 한 번 살펴봅니다. 또한, 12장에서는 regularizer의 개념이 large margin의 개념과 동일하다는 것을 확인할 예정입니다.
Cross-Validation to Access the Generalization Performance
이전 섹션에서 test data에 predictor를 적용하여 이를 추정함으로써 generalization error를 측정한다고 언급했습니다. 이 data를 validation set 이라고도 부릅니다. Validation set은 따로 보관하고 있는 이용 가능한 training data의 subset 입니다. 이 접근 방식의 실질적인 문제는 데이터의 양은 제한되어 있고, 이상적으로는 모델을 학습하는 데 사용할 수 있는 데이터를 최대한 많이 사용한다는 것입니다. 이를 위해서는 validation set $\mathcal{V}$ 를 작게 유지해야 하는데, 이는 predictive performance의 noisy estimate (with high variance)로 이어집니다. 이러한 모순된 목표(large training set, large validation set)에 대한 한 가지 해결 방법은 cross-validation (교차 검증)을 사용하는 것입니다.
K-fold cross-validation은 데이터를 $K$ 개의 chunks로 분리하여, 이들 중 $K-1$ 개의 chunks는 training set $\mathcal{R}$ 로, 나머지 한 개의 chunk는 validation set $\mathcal{V}$ 로 사용합니다. Cross-validation은 이상적으로 $\mathcal{R}$ 과 $\mathcal{V}$ 에 대한 모든 조합을 반복하는데, 아래의 Figure 8.4에서 이를 보여줍니다.
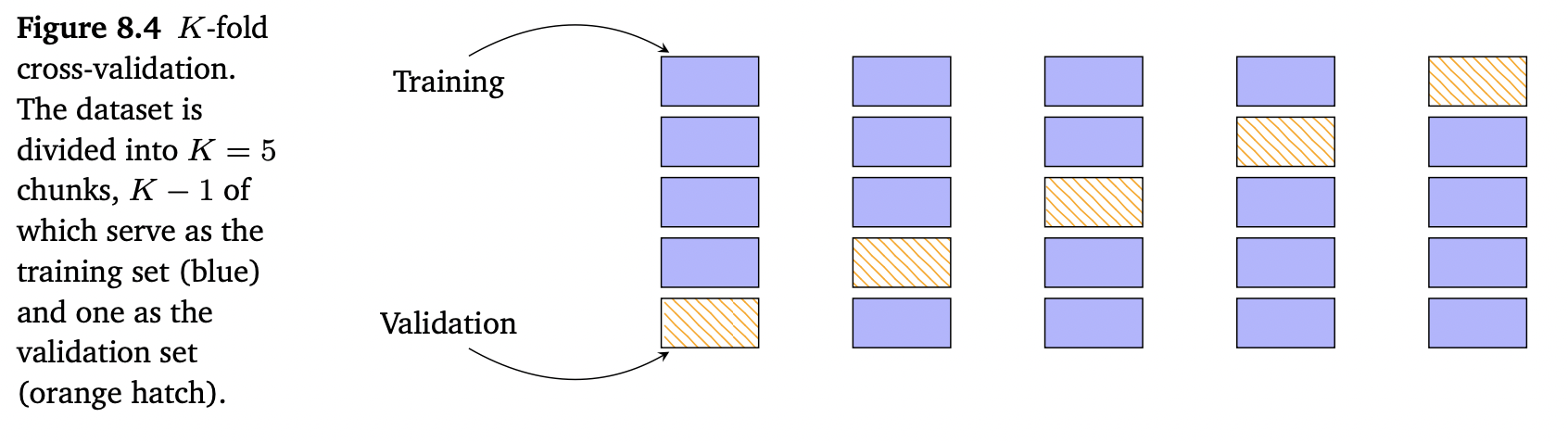
이 방법으로 모든 chunks는 한 번씩 validation set이 되고, K번 실행한 모델의 성능은 평균화됩니다.
우리는 dataset을 두 개의 sets $\mathcal{D}=\mathcal{R}\cup\mathcal{V}$ 로 나누었는데, 두 집합은 서로 겹치지 않습니다($\mathcal{R}\cap\mathcal{V}=\emptyset$). 학습 후, validation set $\mathcal{V}$ 에 대해 predictor $f$ 의 성능을 평가합니다. 예를 들면, validation set에서 학습된 모델의 root mean square error(RMSE)를 계산합니다. 보다 정확하게는, 각 파티션 $k$ 에 대해 training data $\mathcal{R}^{(k)}$ 는 predictor $f^{(k)}$ 를 생성하고, 이는 validation set $\mathcal{V}^{(k)}$ 에 적용되어 empirical risk $R(f^{(k)},\mathcal{V}^{(k)})$ 를 계산합니다. 이 과정을 validation과 training set의 모든 가능한 파티셔닝에 반복하고 predictor의 평균 generalization error를 계산합니다. Cross-validation은 expected generalization error를 다음과 같이 근사합니다.
\[\mathbb{E}_\mathcal{V}[R(f,\mathcal{V})] \approx \frac{1}{K}\sum_{k=1}^K R(f^{(k)},\mathcal{V}^{(k)}) \tag{8.13}\]위 식에서 $R(f^{(k)},\mathcal{V}^{(k)})$ 는 validation set $\mathcal{V}^{(k)}$ 에서 predictor $f^{(k)}$ 에 대한 risk(e.g. RMSE) 입니다.
$K$-fold cross-validation의 잠재적인 단점은 model을 K번 학습하기 때문에 연산량이 많아진다는 것입니다. 실제로는 파라미터만 보는 것만으로 충분하지 않을 수 있습니다. 예를 들어, 모델의 직접적인 파라미터가 아닐 수 있는 여러 complexity 파라미터(e.g. multiple regularization parameters)를 탐색해야 할 수 있습니다. 이러한 하이퍼파라미터(hyperparameters)에 따라 모델의 quality를 평가하면 학습 실행이 기하급수적으로 증가할 수 있습니다. 이런 경우에는 8.6.1장에서 설명하는 nested cross-validation을 사용할 수 있습니다.
하지만, cross-validation은 embarrassingly parallel problem 입니다. 즉, 문제를 parallel tasks로 분할하여 매우 적은 effort만 필요할 수 있습니다. 충분한 컴퓨팅 리소스가 주어졌다면(e.g., cloud computing, server farms), cross-validation은 더이상 single performance assessment보다 오래 걸리지 않습니다.
8.2장에서는 empirical risk minimization이 다음의 개념을 기반으로 한다는 것을 봤습니다.
- the hypothesis class of functions
- the loss function and regularization
8.3장에서는 probability distribution을 사용하여 loss function과 regularization을 대체하면 어떠한 영향을 미치는지 살펴보도록 하겠습니다.