Summary Statistics and Independence
종종 확률 변수의 집합을 요약하고, 확률 변수 쌍을 비교하는데 관심이 있을 수 있습니다. 확률 변수의 통계량(statistics)은 그 확률 변수의 deterministic function 입니다. 분포의 통계량에 대한 요약은 어떻게 확률 변수가 동작하는지에 대한 유용한 관점을 제공하고, 이름에서 알 수 있듯 분포를 요약하고 특성화하는 수(numbers)를 제공합니다.
먼저 잘 알고 있는 평균(mean)과 분산(variance)에 대해 살펴봅니다. 그런 다음 한 쌍의 확률 변수를 비교하는 두 가지 방법에 대해 살펴볼텐데, 하나는 두 확률 변수가 독립인지 확인하는 방법, 다른 하나는 두 확률 변수 간의 내적(inner product)를 계산하는 방법입니다.
Means and Covariances
Mean과 (co)variance는 확률 분포의 특성(expected value and spread)를 묘사하는데 유용합니다. 6.6장에서는 exponential family라고 불리는 유용한 분포들을 살펴볼텐데 여기서 확률 변수의 통계량은 모든 가능한 정보들을 포착합니다.
Expected value(기댓값)은 머신러닝의 핵심이며, 확률 자체의 근본적인 개념이 기댓값으로부터 파생될 수 있습니다.
Definition 6.3 (Expected Value)
Univariate continuous random variable $X\sim p(x)$ 의 함수 $g : \mathbb{R}\rightarrow\mathbb{R}$ 의 expected value 는 아래의 식으로 주어집니다.
\[\mathbb{E}_x\lbrack g(x)\rbrack = \int_{\mathcal{X}} g(x)p(x)\mathrm{d}x \tag{6.28}\]이에 대응되는 discrete random variable $X\sim p(x)$ 의 기댓값은 다음과 같습니다.
\[\mathbb{E}_X\lbrack g(x)\rbrack = \sum_{x\in\mathcal{X}}g(x)p(x) \tag{6.29}\]여기서 $\mathcal{X}$ 는 확률 변수 $X$ 의 가능한 결과(target space)들의 집합입니다.
6장에서 discrete random variables는 수치적인 결과(numerical outcomes)로 간주합니다. 이는 함수 $g$ 가 입력으로 real numbers(실수)를 취한다는 것을 의미합니다.
Definition 6.4 (Mean)
State $x\in\mathbb{R}^D$ 를 갖는 확률 변수 $X$ 의 mean(평균)은 average 이고, 다음과 같이 정의됩니다.
\[\mathbb{R}_X\lbrack\boldsymbol{x}\rbrack = \begin{bmatrix}\mathbb{R}_{X_1}[x_1]\\\vdots\\\mathbb{E}_{X_D}[x_D]\end{bmatrix}\in\mathbb{R}^D \tag{6.31}\]이때, $\mathbb{E}_{X_d}[x_d]$ 는 아래와 같습니다.
\[\mathbb{E}_{X_d}[x_d] := \left\{\begin{align*}\int_{\mathcal{X}} x_d p(x_d)\mathrm{d}x_d \quad&\text{if }X\text{ is a continuous random variable}\\\sum_{x_i\in\mathcal{X}}x_i p(x_d=x_i) \quad&\text{if }X\text{ is a discrete random variable}\end{align*}\right. \tag{6.32}\]$d=1,\dotsc,D$ 인 아래 첨자 $d$ 는 대응하는 $\boldsymbol{x}$ 의 차원입니다. 적분과 합은 확률 변수 $X$ 의 target space의 states $\mathcal{X}$ 에 대해 수행됩니다.
1차원에서는 median(중간값)과 mode(최빈값) 이라는 “평균(average)”에 대한 두 가지의 다른 개념이 있습니다. Median 은 값이 정렬되어 있을 때의 중간(middle)값을 의미합니다. 즉, 값들 중 50%는 median보다 크고, 나머지 50%는 median보다 작습니다. 연속적인 값에 대해서는 CDF에서 0.5인 값으로 일반화할 수 있습니다. 비대칭이거나 long tail을 가지는 분포의 경우, median은 평균(mean)값 보다는 직관에 더 가까운 값의 추정치를 제공합니다. 또한, mean보다 이상치(outlier)에 더 견고하다고 할 수 있습니다.
Mode는 가장 자주 나타나는 값을 의미합니다. 이산 확률 변수에서 mode는 가장 많이 나타난 $x$ 의 값으로 정의됩니다. 연속 확률 변수의 경우, mode는 밀도 함수 $p(\boldsymbol{x})$ 의 peak로 정의됩니다. 특정 밀도 $p(\boldsymbol{x})$ 는 하나 이상일 수 있으며, 고차원의 분포에서는 아주 많을 수도 있습니다. 따라서, 분포에서 모든 mode를 찾는 것은 계산적으로 어려울 수 있습니다.
Example 6.4
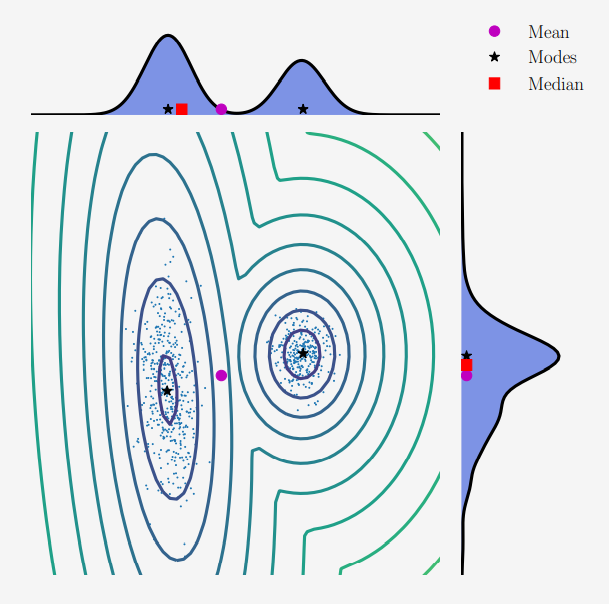
위의 그림에서 묘사하고 있는 2차원 분포를 살펴보겠습니다.
\[p(x) = 0.4\mathcal{N}\left( \boldsymbol{x}\left|\begin{bmatrix}10\\2\end{bmatrix}, \begin{bmatrix}1&0\\0&1\end{bmatrix}\right.\right) + 0.6\mathcal{N}\left( \boldsymbol{x}\left|\begin{bmatrix}0\\0\end{bmatrix}, \begin{bmatrix}8.4&2.0\\2.0&1.7\end{bmatrix}\right.\right) \tag{6.33}\]위 분포에서는 6.5장에서 살펴볼 Gaussian distribution $\mathcal{N}(\mu,\sigma^2)$ 를 사용했습니다. 그림에서는 각 차원에 대응되는 marginal distribution을 보여주고 있으며, marginal distribution 중 한 분포는 bimodal(has two modes) 이고, 다른 분포는 unimodal(has one mode) 입니다. Horizontal bimodal univariate distribution은 mean과 median이 서로 다를 수 있다는 것을 보여줍니다. 2차원의 median을 각 차원의 median들의 concatenation으로 정의하고 싶을 수 있는데, 2차원 points의 정렬을 정의할 수 없기 때문에 어렵습니다.
공분산(covariance)는 두 개의 확률 변수가 서로 얼마나 의존적인지에 대한 개념을 직관적으로 나타낼 수 있습니다.
Definition 6.5 (Covariance (Univariate))
두 단일(univariate) 확률 변수 $X, Y\in\mathbb{R}$ 의 covariance(공분산) 은 각각의 편차(deviations)의 곱으로 주어지며, 다음과 같습니다.
\[\text{Cov}_{X,Y}\lbrack x,y\rbrack := \mathbb{E}_{X,Y}\lbrack (x-\mathbb{E}_X[x])(y-\mathbb{E}_Y[y]) \rbrack \tag{6.35}\]
Expectation의 linearity를 사용하면 Definition 6.5의 표현식은 아래와 같이 정리할 수 있습니다.
\[\text{Cov}[x, y] = \mathbb{E}[xy] - \mathbb{E}[x]\mathbb{E}[y] \tag{6.36}\]한 변수의 공분산 $\text{Cov}[x,x]$ 는 variance(분산) 이라고 하며 $\mathbb{V}[x]$ 라고 표기합니다. 분산의 제곱근은 standard deviation(표준 편차)라고 부르며, 보통 $\sigma(x)$ 로 표기합니다.
공분산의 개념을 multivariate 확률 변수로 확장하면 다음과 같습니다.
Definition 6.6 (Covariance (Multivariate))
각각 $\boldsymbol{x}\in\mathbb{R}^D$ , $\boldsymbol{y}\in\mathbb{R}^E$ 라는 states를 가진 두 확률 변수 $X, Y$ 가 있을 때, $X$ 와 $Y$ 간의 covariance 는 아래와 같이 정의됩니다.
\[\text{Cov}[\boldsymbol{x},\boldsymbol{y}] = \mathbb{E}[\boldsymbol{xy}^\top] - \mathbb{E}[\boldsymbol{x}]\mathbb{E}[\boldsymbol{y}]^\top = \text{Cov}[\boldsymbol{y},\boldsymbol{x}]^\top \in \mathbb{R}^{D\times E} \tag{6.37}\]
Definition 6.6의 두 인수에 동일한 multivariate random variable을 적용할 수도 있습니다. Multivariate random variable에서 분산(variance)은 확률 변수의 개별 차원 간의 관계를 나타냅니다.
Definition 6.7 (Variance)
States $\boldsymbol{x}\in\mathbb{R}^D$ 를 가지고 mean vector가 $\boldsymbol{\mu}\in\mathbb{R}^D$인 확률 변수 $X$ 의 variance 는 다음과 같이 정의됩니다.
\[\begin{align*} \mathbb{V}_X[\boldsymbol{x}] &= \text{Cov}[\boldsymbol{x},\boldsymbol{x}] \tag{6.38a} \\ &= \mathbb{E}_X[(\boldsymbol{x}-\boldsymbol{\mu})(\boldsymbol{x}-\boldsymbol{\mu})^\top] = \mathbb{E}_X[\boldsymbol{xx}^\top] - \mathbb{E}_X[\boldsymbol{x}]\mathbb{E}_X[\boldsymbol{x}]^\top \tag{6.38b} \\ &= \begin{bmatrix} \text{Cov}[x_1,x_1] & \text{Cov}[x_1,x_2] & \cdots & \text{Cov}[x_1, x_D] \\ \text{Cov}[x_2, x_1] & \text{Cov}[x_2,x_2] & \cdots & \text{Cov}[x_2,x_D] \\ \vdots & \vdots & \ddots & \vdots \\ \text{Cov}[x_D, x_1] & \cdots & \cdots & \text{Cov}[x_D, x_D] \end{bmatrix} \tag{6.38c} \end{align*}\]
(6.38c) 식에서 $D\times D$ 행렬은 multivariate random variable $X$ 의 covariance matrix(공분산 행렬) 이라고 불립니다. 공분산 행렬은 symmetric, positivie semidefinite 이며, 데이터의 spread를 보여줍니다. 공분산 행렬의 대각 요소에서는 아래 marginal 의 분산을 포함합니다.
\[p(x_i) = \int p(x_1, \dotsc, x_D)\mathrm{d}x_{\backslash i} \tag{6.39}\]여기서 “$\backslash i$” 는 $i$ 를 제외한 모든 변수를 나타냅니다. 비대각 요소들은 cross-covariance $\text{Cov}[x_i,x_j]$ for $i,j=1,\dotsc,D, i\neq j$ 입니다.
서로 다른 확률 변수 쌍의 공분산을 비교할 때, 각 확률 변수의 분산이 공분산의 값에 영향을 미칩니다. 공분산의 정규화된 버전을 correlation 이라고 합니다.
Definition 6.8 (Correlation)
두 확률 변수 $X, Y$ 간의 correlation(상관계수) 은 아래와 같이 주어집니다.
\[\text{corr}[x, y] = \frac{\text{Cov}[x, y]}{\sqrt{\mathbb{V}[x]\mathbb{V}[y]}} \in [-1, 1] \tag{6.40}\]
Correlation matrix는 표준화된 확률 변수 $\frac{x}{\sigma(x)}$ 의 공분산 행렬입니다. 즉, 각 확률 변수는 correlation matrix에서 표준 편차로 나뉘게 됩니다.
Covariance 및 correlation은 두 확률 변수가 서로 얼마나 관련되어 있는지를 보여줍니다. 이에 대해 아래의 그림을 참조하시길 바랍니다.
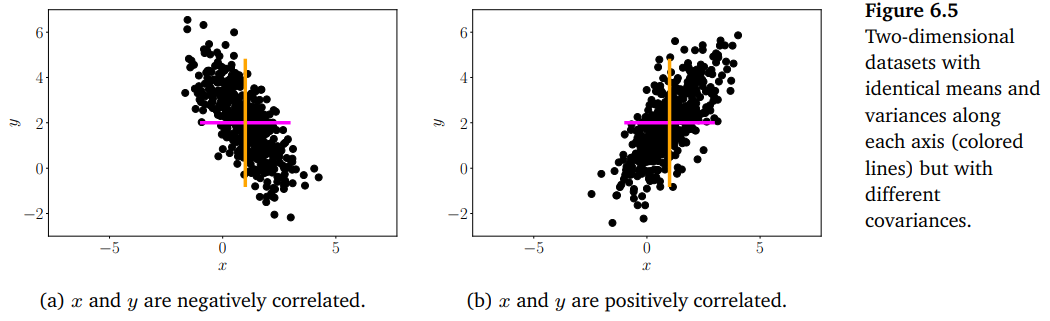
Positive correlation $\text{corr}[x,y]$ 는 $x$ 가 증가할 때, $y$ 또한 증가한다는 것을 의미합니다. Negative correlation은 $x$ 가 증가하면 $y$ 는 감소한다는 것을 의미합니다.
Empirical Means and Covariances
6.4.1장에서 살펴본 정의들은 종종 population mean and covariance(모평균과 모공분산)이라고도 불립니다. 이는 모집단의 실제 통계를 참조하기 때문입니다. 머신러닝에서 우리는 데이터의 emprical observations(경험적 관측)를 통해 학습합니다. 어떤 확률 변수 $X$ 를 고려해봅시다. 여기서 모집단 통계(population statistics)로부터 경험적 통계(empirical statistics)의 실현으로 가기 위한 두 가지 개념적인 단계가 있습니다. 첫째, 유한한 데이터셋(size: N)을 가지고 있다는 사실을 사용하여 유한한 수의 확률 변수들의 함수인 empirical statistic를 구성합니다. 둘째, 데이터를 관측합니다. 즉, 각 확률 변수의 실제 $x_1, \dotsc, x_N$ 을 살펴보고 empirical statistic를 적용합니다.
구체적으로 Definition 6.4장에서 정의한 평균(mean)의 경우, 특정 데이터셋이 주어지면 empirical mean or sample mean으로 불리는 평균의 추정치를 구할 수 있습니다. 이는 empirical covariance도 마찬가지 입니다.
Definition 6.9 (Empirical Mean and Covariance)
Empirical mean vector는 각 변수에 대해 관측치의 산술 평균(arithmetic average)이며, 다음과 같이 정의됩니다.
\[\bar{\boldsymbol{x}} := \frac{1}{N}\sum_{n=1}^N\boldsymbol{x}_n \tag{6.41}\]($\boldsymbol{x}_n \in\mathbb{R}^D$)
Empirical mean과 유사하게, empirical covariance 행렬은 $D\times D$ 이며, 아래와 같이 구할 수 있습니다.
\[\boldsymbol{\Sigma} := \frac{1}{N}\sum_{n=1}^N(\boldsymbol{x}_n-\bar{\boldsymbol{x}})(\boldsymbol{x}_n-\bar{\boldsymbol{x}})^\top \tag{6.42}\]
특정 데이터셋에 대한 통계를 계산하기 위해서, 실제 관측치(observations) $\boldsymbol{x}_1, \dotsc,\boldsymbol{x}_N$ 과 (6.41), (6.42) 식을 사용하면 됩니다. Empirical covariance 행렬은 symmetric, positive semidefinite 합니다.
Three Expressions for the Variance
단일 확률 변수 $X$ 에 대해 방금 살펴본 empirical formulas를 가지고 분산에 대한 세 가지 표현식을 유도해보도록 하겠습니다. 아래에서 살펴볼 유도는 적분을 처리해야 한다는 점을 제외하고는 모집단 분산(population variance)에서도 동일합니다. 분산의 표준 정의는 확률 변수 $X$ 에서 평균 $\mu$ 를 뺀 편차의 제곱에 대한 기댓값(expectation) 입니다. 즉, 다음과 같습니다.
\[\mathbb{V}_X[x] := \mathbb{E}_X[(x-\mu)^2] \tag{6.43}\](6.43)의 기댓값과 평균(mean) $\mu = \mathbb{E}_X(x)$ 는 (6.32) 식을 이용하여 계산됩니다 (이산/연속 확률 변수에 따라 다름). (6.43) 식으로 표현되는 분산(variance) 새로운 확률 변수 $Z := (X-\mu)^2$ 의 평균(mean) 이 됩니다.
(6.43) 식의 분산을 경험적으로 추정할 때, two-pass 알고리즘을 사용합니다. 먼저 (6.41) 식을 사용하여 평균 $\mu$ 를 계산할 때 데이터를 한 번 pass하고, 이 추정값 $\hat{\mu}$ 를 사용하여 분산(variance)를 계산할 때 데이터를 한 번 더 pass 합니다. 하지만, two-pass는 (6.43) 식의 재정렬하여 one-pass로 해결할 수 있습니다. 식 (6.43)의 공식은 raw-score formula for variance 라 불리는 아래의 식으로 변환될 수 있습니다.
\[\mathbb{V}_X[x] = \mathbb{E}_X[x^2] - (\mathbb{E}_X[x])^2 \tag{6.44}\]위 식은 ‘제곱의 평균 - 평균의 제곱’ 으로 기억하면 됩니다. 계산을 위해서 데이터를 한 번 순회할 때, $x_i$(평균 계산용) 와 $x_i^2$(제곱의 평균 계산용)을 동시에 누적시킵니다. 다만, 이러한 방식으로 구현하면 수치적으로 불안정할 수 있습니다. Raw-score 버전의 분산은 머신러닝에서 유용할 수 있는데, 예를 들어, bias-variance decomposition을 유도할 때 유용합니다.
분산을 표현하는 세 번째 방식은 관측값의 모든 쌍 간의 pairwise differences의 합이라는 것입니다. 확률 변수의 실제 관측값 sample $x_1, \dotsc, x_N$ 이 있고, $x_i$ 와 $x_j$ 간의 squared difference를 계산합니다. 이 식을 확장해보면 $N^2$ 개의 pairwise differences의 합이 관측치의 empirical variance라는 것을 볼 수 있습니다.
\[\frac{1}{N^2}\sum_{i,j=1}^N (x_i - x_j)^2 = 2\left\lbrack \frac{1}{N}\sum_{n=1}^N x_i^2 - \left( \frac{1}{N}\sum_{i=1}^N x_i \right)^2 \right\rbrack \tag{6.45}\]위 식은 raw-score expression인 식 (6.44)의 2배입니다. 이는 pairwise distance($N^2$ 개)의 합을 deviations from mean($N$ 개)의 합으로 표현할 수 있다는 것을 의미합니다. 기하학적으로는 pairwise distance와 포인터 집합의 중심으로부터의 distance가 서로 동등하다는 것을 의미합니다. 계산적인 관점에서는 평균(mean)을 계산하고, 그 다음 분산(variance)를 계산한 뒤, 식 (6.45)의 우항을 얻을 수 있다는 것을 의미합니다.
Sums and Transformations of Random Variables
교재에서 소개하는 분포로 잘 설명할 수 없는 현상을 모델링하고 싶을 수 있습니다. 이런 경우에는 확률 변수를 간단히 조작하여 수행할 수 있습니다.
두 확률 변수 $X, Y$ 가 각각 states $\boldsymbol{x},\boldsymbol{y}\in\mathbb{R}^D$ 를 가질 때, 아래의 식이 만족합니다.
\[\begin{align*} &\mathbb{E}[\boldsymbol{x}+\boldsymbol{y}] = \mathbb{E}[\boldsymbol{x}] + \mathbb{E}[\boldsymbol{y}] \tag{6.46} \\ &\mathbb{E}[\boldsymbol{x}-\boldsymbol{y}] = \mathbb{E}[\boldsymbol{x}] - \mathbb{E}[\boldsymbol{y}] \tag{6.47} \\ &\mathbb{V}[\boldsymbol{x}+\boldsymbol{y}] = \mathbb{V}[\boldsymbol{x}] + \mathbb{V}[\boldsymbol{y}] + \text{Cov}[\boldsymbol{x},\boldsymbol{y}] + \text{Cov}[\boldsymbol{y},\boldsymbol{x}] \tag{6.48} \\ &\mathbb{V}[\boldsymbol{x}-\boldsymbol{y}] = \mathbb{V}[\boldsymbol{x}] + \mathbb{V}[\boldsymbol{y}] - \text{Cov}[\boldsymbol{x},\boldsymbol{y}] - \text{Cov}[\boldsymbol{y},\boldsymbol{x}] \tag{6.49} \end{align*}\]평균과 분산(or 공분산)은 확률 변수의 affine transformation과 관련하여 몇 가지 유용한 속성들이 있습니다. 평균이 $\boldsymbol{\mu}$ 이고 공분산 행렬이 $\boldsymbol{\Sigma}$ , 그리고 (deterministric) affine transformation이 $\boldsymbol{y} = \boldsymbol{Ax} =\boldsymbol{b}$ 라고 가정해봅시다. 그러면 $\boldsymbol{y}$ 는 그 자체로 확률 변수이며, 평균 벡터와 공분산 행렬은 다음과 같이 주어집니다.
\[\begin{align*} &\mathbb{E}_Y[\boldsymbol{y}] = \mathbb{E}_X[\boldsymbol{Ax}+\boldsymbol{b}] = \boldsymbol{A}\mathbb{E}_X[\boldsymbol{x}] + \boldsymbol{b} = \boldsymbol{A\mu} + \boldsymbol{b} \tag{6.50} \\ &\mathbb{V}_Y[\boldsymbol{y}] = \mathbb{V}_X[\boldsymbol{Ax}+\boldsymbol{b}] = \mathbb{V}_X[\boldsymbol{Ax}] = \boldsymbol{A}\mathbb{V}_X[\boldsymbol{x}]\boldsymbol{A}^\top = \boldsymbol{A\Sigma A}^\top \tag{6.51} \end{align*}\]$\boldsymbol{x}, \boldsymbol{y}$ 의 공분산은 아래와 같습니다.
\[\begin{align*} \text{Cov}[\boldsymbol{x},\boldsymbol{y}] &= \mathbb{E}[\boldsymbol{x}(\boldsymbol{Ax}+\boldsymbol{b})^\top] - \mathbb{E}[\boldsymbol{x}]\mathbb{E}[\boldsymbol{Ax}+\boldsymbol{b}]^\top \tag{6.52a} \\ &= \mathbb{E}[\boldsymbol{x}]\boldsymbol{b}^\top + \mathbb{E}[\boldsymbol{xx}^\top]\boldsymbol{A}^\top -\boldsymbol{\mu b}^\top - \boldsymbol{\mu\mu^\top A^\top} \tag{6.52b} \\ &= \boldsymbol{\mu b}^\top - \boldsymbol{\mu b}^\top + (\mathbb{E}[\boldsymbol{xx}^\top] - \boldsymbol{\mu\mu}^\top)\boldsymbol{A}^\top \tag{6.52c} \\ &\overset{(6.38b)}{=} \boldsymbol{\Sigma A}^\top \tag{6.52d} \end{align*}\]여기서 $\boldsymbol{\Sigma} = \mathbb{E}[\boldsymbol{xx}^\top] - \boldsymbol{\mu\mu}^\top$ 은 $X$ 의 공분산(covariance) 입니다.
Statistical Independence
Definition 6.10 (Independece). 만약 아래의 식이 성립한다면 (if and only if),
\[p(\boldsymbol{x},\boldsymbol{y}) = p(\boldsymbol{x})p(\boldsymbol{y}) \tag{6.53}\]두 확률 변수 $X, Y$ 는 statistically independent 라고 합니다.
직관적으로, 만약 $\boldsymbol{y}$ 의 값(알려진 경우)이 $\boldsymbol{x}$ 에 대한 추가 정보와 관련이 없는 경우(반대의 경우도 동일), 두 확률 변수는 서로 독립적입니다. 만약 $X, Y$ 가 (statistically) independent 하다면, 아래의 식들이 성립합니다.
- $p(\boldsymbol{y}|\boldsymbol{x}) = p(\boldsymbol{y})$
- $p(\boldsymbol{x}|\boldsymbol{y}) = p(\boldsymbol{x})$
- $\mathbb{V}_{X, Y}[\boldsymbol{x}+\boldsymbol{y}] = \mathbb{V}_X[\boldsymbol{x}] + \mathbb{V}_Y[\boldsymbol{y}]$
- $\text{Cov}_{X, Y}[\boldsymbol{x},\boldsymbol{y}] = \boldsymbol{0}$
마지막 식은 역이 성립하지 않을 수 있습니다. 즉, 두 확률 변수의 공분산이 0이더라도 독립이 아닌 경우도 있습니다. 이를 이해하려면, 공분산이 linear dependence만을 측정한다는 사실을 기억하면 됩니다. 따라서, 비선형적으로 종속된 확률 변수는 공분산이 0일 수 있습니다.
Example 6.5
평균이 0 ($\mathbb{E}[x]=0$) 이고 $\mathbb{E}[x^3] = 0$ 인 확률 변수 $X$ 에 대해, $y = x^2$ 일 때 $X$ 와 $Y$ 의 공분산을 계산하면 다음과 같습니다.
\[\text{Cov} = \mathbb{E}[xy] - \mathbb{E}[x]\mathbb{E}[y] = \mathbb{E}[x^3] = 0 \tag{6.54}\]
머신러닝에서는 종종 독립적이고 동일하게 분포된(i.i.d.) 확률 변수 $X_1,\dotsc,X_N$ 로 모델링할 수 있는 문제를 고려합니다. 둘 이상의 확률 변수에 대해, “independent” 의 의미는 모든 하위 집합들이 독립적이다라는 것입니다. “Identically distributed”는 모든 확률 변수가 동일한 분포를 따른다는 것을 말합니다.
머신러닝에서 중요한 또 다른 개념은 conditional independence 입니다.
Definition 6.11 (Conditional Independence). 만약 $Z$ 가 주어졌을 때, 다음의 식이 성립한다면(if and only if), 두 확률 변수 $X, Y$ 는 conditionally independent 하다고 합니다.
\[p(\boldsymbol{x},\boldsymbol{y}|\boldsymbol{z}) = p(\boldsymbol{x}|\boldsymbol{z})p(\boldsymbol{y}|\boldsymbol{z}) \quad \text{for all } \boldsymbol{z}\in\mathcal{Z} \tag{6.55}\]여기서 $\mathcal{Z}$ 는 확률 변수 $Z$ 의 states 집합 입니다. $X$ 가 $Z$ 에 대한 $Y$ 에 대해 조건부 확률을 $X\bot\!\!\!\bot Y|Z$ 로 표기합니다.
Definition 6.11는 모든 $\boldsymbol{z}$ 의 값에 대해 식 (6.55)의 관계가 true이어야 함을 요구합니다. (6.55) 식은 “$\boldsymbol{z}$ 를 알고 있으면 $\boldsymbol{x}$ 와 $\boldsymbol{y}$ 의 분포가 분해된다” 라고 이해할 수 있습니다.
확률의 product rule (6.22)를 사용하여, (6.55)의 좌항을 다음과 같이 쓸 수 있습니다.
\[p(\boldsymbol{x},\boldsymbol{y}|\boldsymbol{z}) = p(\boldsymbol{x}|\boldsymbol{y},\boldsymbol{z})p(\boldsymbol{y}|\boldsymbol{z}) \tag{6.56}\](6.55)의 우항과 (6.56)에서 $p(\boldsymbol{y}|\boldsymbol{z})$ 가 나타나므로, 다음과 같이 정리할 수 있습니다.
\[p(\boldsymbol{x}|\boldsymbol{y},\boldsymbol{z}) = p(\boldsymbol{x}|\boldsymbol{z}) \tag{6.57}\]식 (6.57)은 conditional independence의 또 다른 정의를 나타냅니다. 이러한 표현은 “$\boldsymbol{z}$ 를 알고 있다고 가정할 때, $\boldsymbol{y}$ 에 대한 정보가 $\boldsymbol{x}$ 의 정보를 변경하지 않는다” 라는 해석을 제공합니다.
Inner Products of Random Variables
3.2장에서 살펴본 inner product의 정의를 떠올려봅시다. 확률 변수들 간의 inner product 또한 정의할 수 있는데, 이번 섹션에서 이에 대해서 살펴보도록 하겠습니다. 만약 두 개의 uncorrelated(상관하지 않는) 확률 변수 $X,Y$ 가 있으면, 다음의 식이 성립합니다.
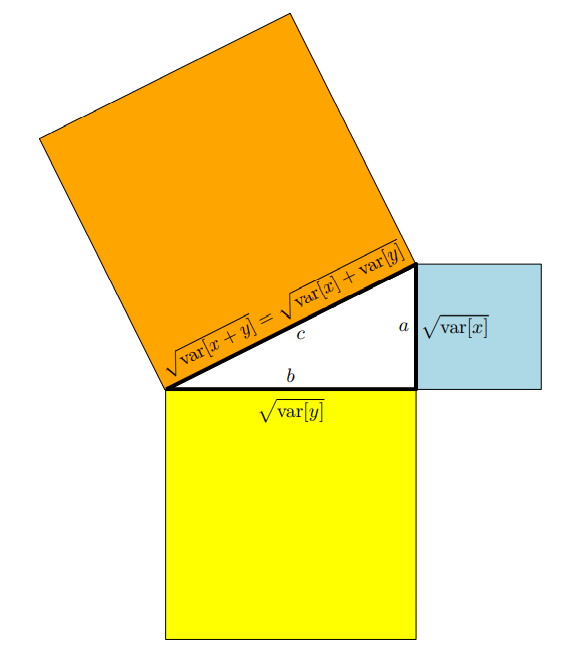
\[\mathbb{V}[x+y] = \mathbb{V}[x]+\mathbb{V}[y]\tag{6.58}\]분산(variance)은 제곱항으로 측정되므로, 위 식은 마치 피타고라스 정리($c^2=a^2+b^2$)처럼 보입니다.
이어서, (6.58)에서 보여주는 uncorrelated random variables의 분산 관계를 기하학적으로 해석해보도록 하겠습니다.
확률 변수는 vector space에서의 벡터로 간주될 수 있습니다. 그리고 확률 변수의 기하학적 속성을 정의하기 위해 inner product를 정의할 수 있습니다. 만약 평균이 0인 확률 변수 $X, Y$ 에 대해 아래와 같이 inner product를 정의한다면,
\[\langle X,Y\rangle := \text{Cov}[x, y] \tag{6.59}\]우리는 inner product를 얻을 수 있습니다. 두 argument에서 공분산은 symmetric, positive definite, linear 하다는 것을 알 수 있습니다. 확률 변수의 길이(length)는 아래와 같습니다.
\[\|X\| = \sqrt{\text{Cov}[x,x]} = \sqrt{\mathbb{V}[x]} = \sigma[x] \tag{6.60}\]즉, 확률 변수의 길이는 표준 편차(standard deviation) 입니다. 확률 변수의 길이가 더 길수록, 불확실성은 커집니다. 그리고 길이가 0인 확률 변수는 deterministic 하다는 것을 의미합니다.
만약 두 확률 변수 $X,Y$ 간의 각도 $\theta$ 를 찾는다면, 다음의 식을 통해서 얻을 수 있습니다.
\[\cos\theta = \frac{\langle X,Y\rangle}{\|X\|\|Y\|} = \frac{\text{Cov}[x,y]}{\sqrt{\mathbb{V}[x]\mathbb{V}[y]}} \tag{6.61}\]위 식은 두 확률 변수 간의 correlation (definition 6.8) 입니다. 이는 correlation을 기하학적으로 두 확률 변수 간의 각도의 cosine으로 생각할 수 있다는 것을 의미합니다. 이미 우리는 Definition 3.7로부터 $X\bot Y \Longleftrightarrow \langle X,Y\rangle = 0$ 이라는 것을 알고 있습니다. 확률의 경우, 이는 $\text{Cov}[x,y]=0$ 일 때, $X, Y$ 가 서로 orthgonal 하다는 것을 의미합니다. 즉, 두 확률 변수가 서로 uncorrelated 하다는 것을 의미합니다. 아래 그림에서 이를 잘 설명해주고 있습니다.