Data, Models, and Learning
두 번째 파트를 시작하기 전에 머신러닝 알고리즘이 해결하고자하는 문제에 대해 살펴 볼 필요가 있습니다. 1장에서 언급한 것과 같이 머신러닝 시스템에는 data, model, learning의 세 가지의 주요 구성요소가 존재합니다. 머신러닝에서 주요 질문은 ‘좋은 모델(good model)이란 무엇을 의미하는가?’ 입니다. 모델(model)이라는 단어는 많은 의미가 담겨있을 수 있는데, 이 장에서 여러 번 모델의 의미에 대해서 살펴보겠습니다. 또한, ‘좋은(good)’ 이라는 단어에서도 객관적으로 정의하는 방법이 명확하지 않습니다.
머신러닝의 기본적인 원칙 중 하나는 좋은 모델은 접하지 않았던 데이터(unseen data)에서도 잘 동작해야 한다는 것입니다. 이를 위해서는 정확도(accuracy)나 GT(ground truth)로부터의 distance 등과 같은 몇 가지 성능 메트릭(metrics)를 정의하고 이러한 메트릭에서 좋은 성능을 보일 수 있는 방법을 찾아야 합니다. 8장에서는 머신러닝 모델에 대해 이야기하기 위해서 일반적으로 사용되는 수학 및 통계 언어의 몇 가지 필요한 부분들을 살펴봅니다. 그리고 이를 통해, 접하기 못한 데이터에 대해서도 잘 동작하도록 모델을 학습하는 best practices를 간략히 살펴보겠습니다.
1장에서 언급했듯이, ‘machine learning algorithm’에는 training과 prediction의 두 가지 다른 의미가 있습니다. 8장에서는 이러한 의미와 다양한 모델 중에서 선택하는 아이디어에 대해서 살펴봅니다. 8.2장에서는 framework of empirical risk minimization에 대해서 살펴보고, 8.3장에서는 maximum likelihood 원칙, 8.4장에서는 probabilistic models에 대해 살펴봅니다. 8.5장에서는 probabilistic models를 지정하기 위한 graphical language를 간략히 살펴보고, 마지막으로 8.6장에서는 모델 선택에 대해 논의합니다.
8.1장의 나머지 부분에서는 data, models, learning에 대해서 자세히 살펴보도록 하겠습니다.
Data as Vectors
우리는 데이터가 컴퓨터로 읽을 수 있고, 적절히 숫자 형태로 표현될 수 있다고 가정합니다. 데이터는 아래와 같이 표 형태로 간주됩니다. 여기서 표의 각 행은 특정 인스턴스 또는 example을 표현하고, 각 열은 특정 feature를 표현합니다.
최근 몇 년 동안, 머신러닝은 genomic sequences, 텍스트, 웹페이지의 이미지, 소셜 미디어의 graph 등 숫자 형태로 명확히 표현되지 않는 타입의 데이터에 적용되었습니다. 여기서 good features의 중요하고 어려운 측면에 대해서는 논의하지 않았습니다. 이러한 측면의 대부분은 domain 전문 지식에 의존하며 세심한 엔지니어링을 필요로 합니다. 그리고 최근에는 데이터 사이언스(data science) 범주에 포함되었습니다.
표 형식의 데이터가 있다고 하더라도, 숫자로 표현하기 위해서는 아직 몇 가지 선택들이 남아 있습니다. 예를 들어, 위의 표의 성별을 나타내는 열에서 남성을 ‘0’, 여성을 ‘1’로 표현하도록 변환할 수 있습니다. 아니면, ‘-1’과 ‘+1’로 성별을 표현할 수도 있습니다. 게다가, 이러한 변환을 구축할 때는 대학 학위의 진행 과정(bachelor - master - PhD)이나 우편번호가 실제 지역을 인코딩한다는 것과 같이 domain knowledge를 사용하는 것도 중요합니다.
위의 표를 숫자 형태로 변환한 표는 아래와 같습니다.

여기서 각 우편번호는 위도와 경도, 두 가지 숫자로 표현되었습니다. 잠재적으로 머신러닝 알고리즘으로 직접 읽을 수 있는 숫자 데이터라도 단위(units), 스케일(scaling), 제약 조건(constraints)에 대해서 신중하게 고려해야 합니다. 추가적인 정보가 없다면, empirical mean이 0, empirical variance가 1이 되도록 dataset의 모든 열들을 shift/scale 해야 합니다.
이 책에서는 전문가가 이미 데이터를 적절하게 변환했다고 가정합니다. 즉, 각 입력 $x_n$ 은 features, attributes, or covariates라고 부르는 $D$ 차원 실수 벡터입니다. 새롭게 변환된 표에서는 원본 표의 name column이 삭제되었는데, 삭제된 주요 이유는 이는 식별자(이름)가 학습에 도움이 된다고 생각되지 않고 개인정보를 보호하기 위해 익명화할 수 있기 때문입니다.
책의 두 번째 파트에서는 $N$ 을 사용하여 dataset에서 examples의 수를 나타냅니다. 그리고 소문자 $n=1,\dotsc,N$ 으로 example들을 인덱싱합니다. Table 8.2와 같이 수치 데이터 집합이 벡터들의 배열로 주어졌다고 가정합니다. 각 행은 각각의 특정 $\boldsymbol{x}_n$ 이며, 머신러닝에서는 보통 examples 또는 data point 라고 지칭합니다. 아래 첨자 $n$ 은 dataset에서 총 N개의 examples 중 n번째 example을 의미합니다. 각 열은 한 example의 관심있는 특정 feature을 나타내며, feature들은 $d=1,\dotsc,D$ 로 인덱싱합니다. 데이터가 벡터로 표현된다는 것을 상기시켜보면, 각 example (each data point)은 D-dimensional 벡터라는 것을 알 수 있습니다. 테이블의 방향은 database에 의해 결정되지만, 일부 머신러닝 알고리즘에서는 examples를 열 벡터로 나타내는 것이 더 편리합니다.
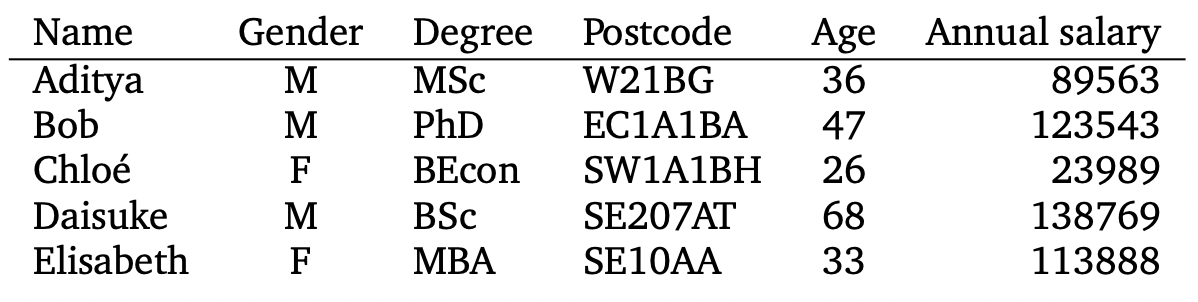
Table 8.2의 데이터를 기반으로 나이(age)로부터 연봉을 예측하는 문제를 고려해보겠습니다. 이러한 문제를 supervised learning problem이라고 부르며, 여기서 각 example $\boldsymbol{x}_n$ 과 관련된 연봉을 label $y_n$ 로 표기합니다. Label $y_n$ 은 target, response variable, annotation 등 다양한 이름을 가지고 있습니다. Dataset은 ${(\boldsymbol{x}_1,y_1), \dotsc, (\boldsymbol{x}_n, y_n), \dotsc, (\boldsymbol{x}_N, y_N)}$ 과 같이 example-label 쌍의 집합으로 작성됩니다. 테이블의 examples ${\boldsymbol{x}_1,\dotsc,\boldsymbol{x}_N}$ 는 보통 연결(concatenated)되며, $\boldsymbol{X}\in\mathbb{R}^{N\times D}$ 로 작성됩니다. 아래 그림 Figure 8.1은 Table 8.2의 오른쪽 두 개의 열로 구성된 dataset을 보여주고 있으며, 여기서 $x$ = age, $y$ = salary 입니다.
이제 책의 첫 번째 파트에서 살펴본 수학적 개념들을 사용하여 위에서 살펴본 것과 같은 머신러닝 문제를 공식화합니다. 데이터를 벡터 $\boldsymbol{x}_n$ 으로 표현하면 2장에서 살펴본 선형대수(linear algebra) 개념을 사용할 수 있습니다. 많은 머신러닝 알고리즘에서는 추가적으로 두 벡터를 비교할 수 있어야 합니다. 9장과 12장에서 살펴볼텐데, 두 example 간의 similarity나 distance를 계산하여 유사한 features를 가진 examples가 유사한 label을 갖는다는 것을 공식화할 수 있습니다. 두 벡터의 비교는 3장에서 설명한 geometry를 구성하고, 7장의 최적화 기법을 사용하여 resulting learning problem을 최적화할 수 있어야 합니다.
데이터를 벡터로 표현하기 때문에, 데이터를 조작하여 잠재적으로 더 좋은 표현(better representations)을 찾을 수 있습니다. Good representations를 찾는 두 가지 방법을 논의하는데, 한 가지 방법은 original feature vector의 lower-demensional approximations를 찾는 것이고, 다른 하나는 original feature vector의 non-linear higher-dimensional combinations를 사용하는 것입니다. 10장에서는 principal components를 찾아 original data space의 low-dimensional approximation을 찾는 예제를 살펴봅니다. Principal components를 찾는 것은 4장의 eigenvalue와 singular value decomposition과 깊게 연관됩니다.
고차원 표현(high-dimensional representation)의 경우, higher-dimensional representation $\phi(\boldsymbol{x}_n)$ 을 사용하여 inputs $\boldsymbol{x}_n$ 을 표현할 수 있는 explicit feature map $\phi(\cdot)$ 을 볼 수 있습니다. Higher-dimensional representations의 main motivation은 original features의 non-linear combinations로 새로운 features를 구축할 수 있다는 것입니다. 이를 통해서 문제를 더 쉽게 만들 수 있습니다. 9.2장에서 이러한 feature map에 대해서 논의하고, 12.4장에서 어떻게 feature map이 kernel을 유도하는지 봅니다. 최근 몇 년 동안 딥러닝 methods는 데이터 자체를 사용하여 good features를 학습할 가능성을 보여주었고, computer vision, speech recognition, natural language processing과 같은 분야에서 매우 성공적이었습니다.
Models as Functions
적절한 vector representation의 데이터가 있으면, predicator 라고 하는 예측 함수를 구성하는 작업을 수행할 수 있습니다. 1장에서는 아직 모델에 대한 정확한 언어를 가지고 있지 않았습니다. 지금부터는 이 책의 첫 번째 파트에서 살펴본 개념들을 사용하여 ‘model’이 무엇을 의미하는지 이야기할 수 있습니다. 이 책에서는 두 가지 접근 방식을 제시하는데, 하나는 a predicator as a function이고, 다른 하나는 a predicator as a probabilistic model 입니다. 먼저 전자에 대해서 살펴보고, 그 다음 섹션에서 후자에 대해 살펴보겠습니다.
Predictor는 특정 input example(여기서는 a vector of features)이 주어졌을 때, output을 생성하는 함수입니다. 지금부터 output은 single number라고 가정합니다. 즉, output은 real-valued scalar output 입니다. 이는 아래와 같이 작성될 수 있습니다.
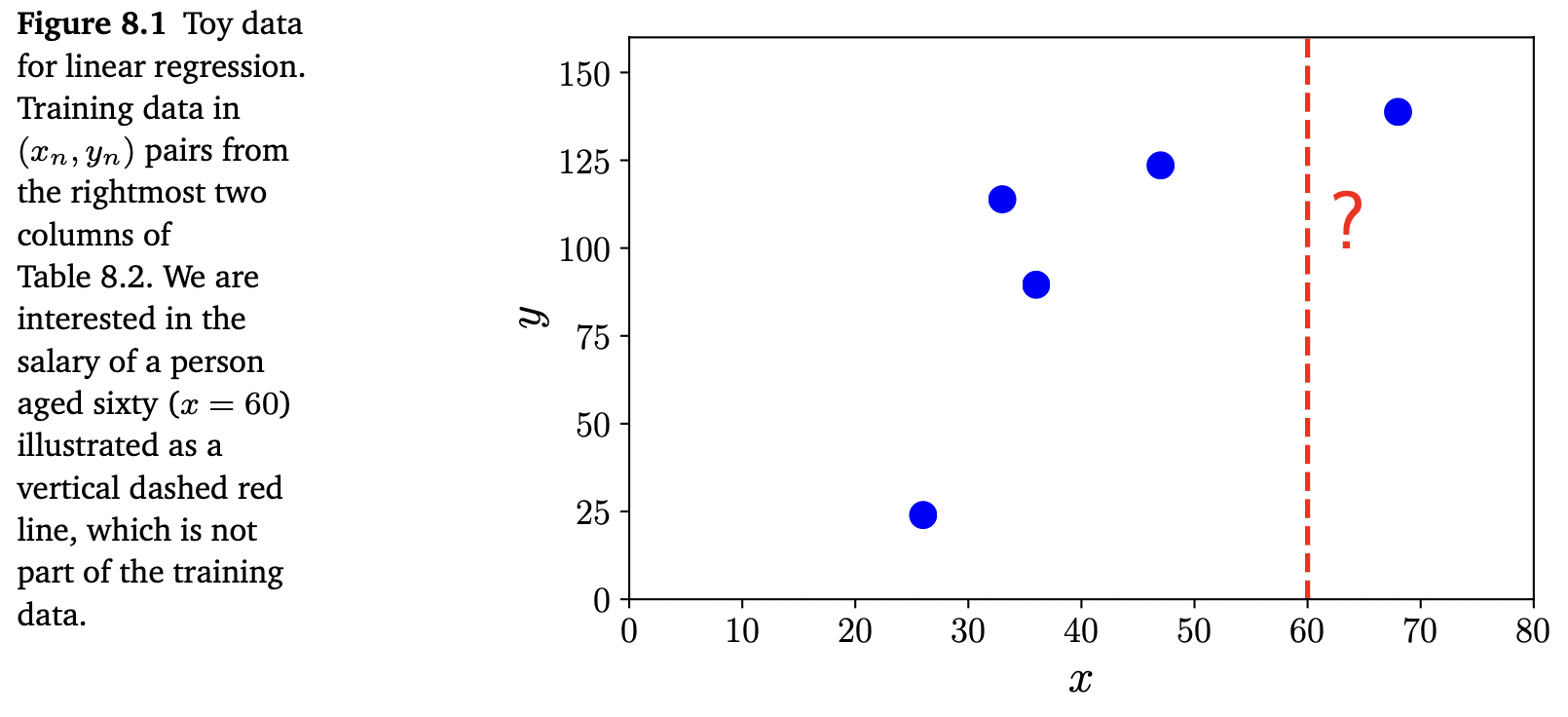
\[f : \mathbb{R}^D \rightarrow \mathbb{R} \tag{8.1}\]위 식에서 input vector $\boldsymbol{x}$ 는 $D$ -차원이며($D$ 개의 features), 함수 $f$ 입력을 적용하여 real number를 리턴하게 됩니다. Figure 8.2는 input values $x$ 에 대한 예측값을 계산하는데 사용할 수 있는 가능한 함수를 보여줍니다.
이 책에서는 functional analysis가 필요한 모든 함수들의 general case를 고려하지는 않습니다. 대신, 아래와 같은 linear functions의 special case를 고려합니다 (for unknown $\boldsymbol{\theta}, \theta_0$ ).
\[f(\boldsymbol{x}) = \boldsymbol{\theta}^\top\boldsymbol{x} + \theta_0 \tag{8.2}\]이러한 제한은 2장과 3장에서의 내용으로 머신러닝의 비확률적(non-probabilistic) 관점에서 predicator의 개념을 설명하는데 충분하다는 것을 의미합니다.
Models as Probability Distributions
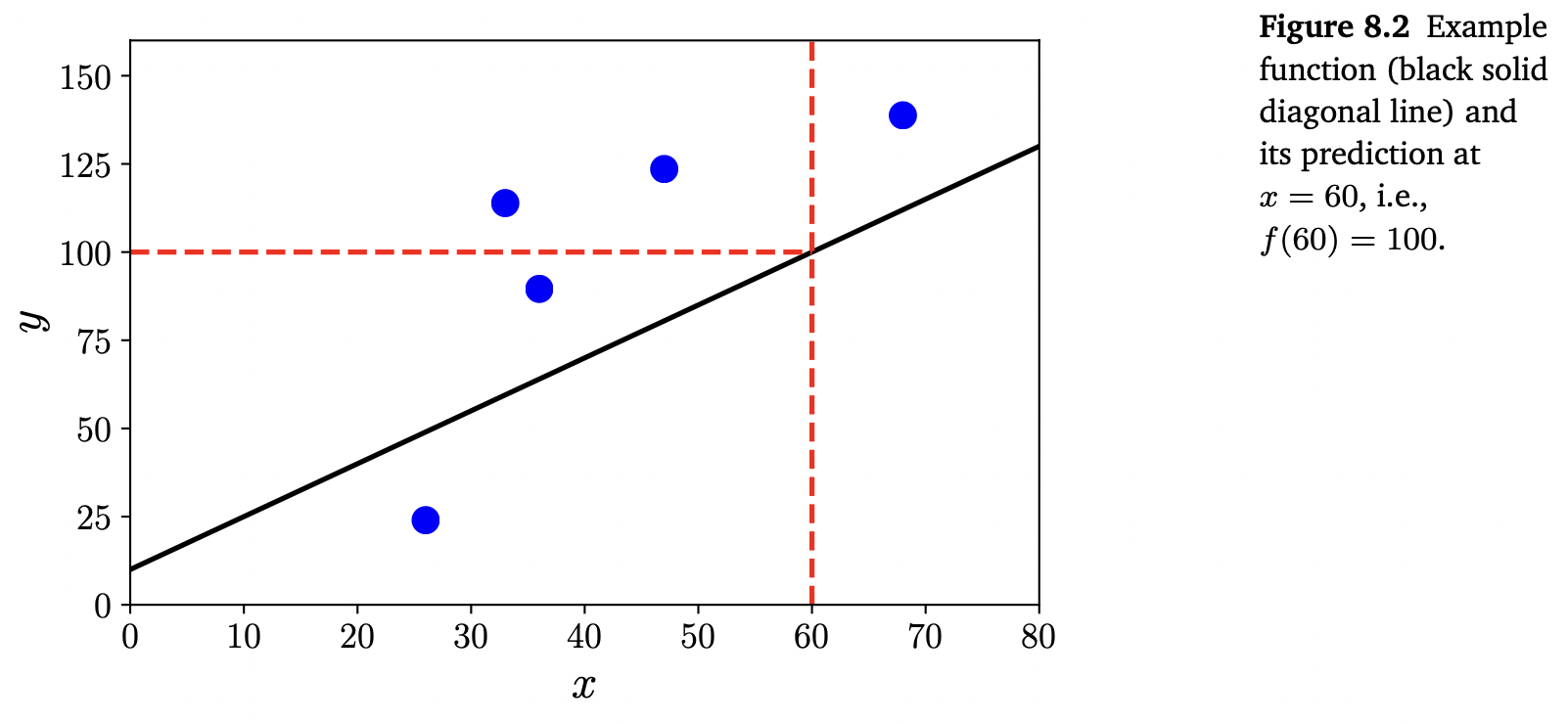
종종 데이터에 노이즈가 포함되어 있다고 간주하고 머신러닝을 적용하여 노이즈로부터 signal을 식별할 수 있기를 희망합니다. 이를 위해서는 노이즈의 영향을 정량화할 수 있는 언어가 필요합니다. 예를 들어, 특정 테스트에서의 data point의 예측값에 대한 신뢰도를 수치화하기 위해서 종종 어떤 종류의 불확실성을 나타내는 predicator를 원할 수 있습니다. 6장에서 살펴봤듯이 확률 이론은 불확실성을 나타내는 언어를 제공합니다. 아래의 Figure 8.3은 함수의 predictive uncertainty를 가우스 분포(gaussian distribution)으로 보여줍니다.
Predicator를 single function으로 간주하는 대신, predicator를 probabilistic model로 간주할 수 있습니다. 즉, 가능한 함수의 분포를 설명하는 모델로 간주할 수 있습니다. 이 책에서는 stochastic processes와 random measures가 필요하지 않은 probabilistic models를 설명하기 위해서 유한한 차원의 파라미터를 가진 분포의 special case로 제한합니다. 이러한 special case에서는 probabilistic models를 multivariate probability로 생각할 수 있습니다.
8.4장에서는 머신러닝 모델을 정의하기 위해 6장에서 논의한 확률 개념을 어떻게 사용하는지 살펴보고, 8.5장에서는 확률 모델을 간결한 방식으로 설명하기 위한 graphical language를 살펴봅니다.
Learning in Finding Parameters
학습의 목표는 model과 unseen data에서도 resulting predictor가 잘 수행하도록 model에 대응되는 parameters를 찾는 것입니다. 머신러닝 알고리즘을 논의할 때에 개념적으로 세 가지의 구별되는 알고리즘 단계(algorithmic phases)가 있습니다.
- Prediction or inference
- Training or parameter estimation
- Hyperparameter tuning or model selection
Prediction 단계는 unseen test data에 대한 학습된 predictor를 사용할 때 입니다. 다시 말하면, 파라미터와 모델 선택이 이미 fixed 되었고, predictor가 새로운 input data points를 표현하는 새로운 벡터에 적용되는 것입니다. 1장과 이전 섹션에서 언급한 것처럼 predictor가 function인지 probabilistic model인지에 따라 두 가지의 schools of machine learning을 고려합니다. Probabilistic model을 사용할 때는 prediction 단계를 inference라고 부릅니다.
Training or parameter estimation 단계는 training data를 기반으로 predictive model을 조정할 때 입니다. Training data가 주어졌을 때 goodl predictors를 찾고자 하는데, 여기에는 두 가지 주요 전략이 있습니다. 하나는 measure of quality를 기반으로 best predictor를 찾는 것이고, 다른 하나는 Bayesian inference(베이즈 추론)를 사용하는 것입니다. Point estimate를 찾는 것은 두 가지 유형의 predictors에 모두 적용할 수 있지만, Bayesian inference는 probabilistic model에만 적용할 수 있습니다.
Non-probabilistic model의 경우, empirical risk minimization 원칙을 따르며, 이에 대해서는 8.2장에서 살펴볼 예정입니다. Empirical risk minimization은 good parameters를 찾기 위한 optimization problem을 직접적으로 제공합니다. Statistical model에서는 good parameters를 찾기 위해 maximum likelihood 원칙을 사용합니다. Probabilistic model을 사용하여 파라미터의 불확실성을 모델링할 수 있는데, 이는 8.4장에서 자세히 살펴보겠습니다.
Numerical methods를 사용하여 데이터에 잘 맞는(‘fit’) good parameters를 찾습니다. 그리고 대부분의 training methods는 maximum of an objective를 찾는 hill-climbing 방식으로 생각할 수 있습니다. 이를 위해서 5장에서 설명한 gradients와 7장에서 설명한 numerical optimization approaches를 사용합니다.
1장에서 언급했듯이 우리는 미래에 볼 데이터에서도 잘 수행되도록 데이터를 기반으로 모델을 학습하는데 관심이 있습니다. 모델이 training data에만 잘 맞는 것만으로 충분하지 않으며, unseen data에서도 잘 수행되어야 합니다. 8.2.4장에서는 cross-validation(교차 검증)을 사용하여 unseen data에 대한 predictor의 동작을 시뮬레이션합니다. 이번 장에서 살펴보겠지만, unseen data에 잘 수행해야 한다는 목표를 달성하려면 training data에 잘 맞는 것과 현상에 대한 ‘간단한’ explanations를 찾는 것 사이에서 균형을 맞추어야 합니다. 이러한 trade-off는 regularization(정규화, 8.2.3장) 또는 prior(8.3.2장)을 추가하여 얻을 수 있습니다. 철학에서 이것은 induction과 deduction도 아닌 abduction이라고 부릅니다 (abduction은 best explanation을 추론하는 과정입니다).
종종 사용할 components의 수나 고려해야 할 probability distributions의 class와 같은 predictors의 구조에 대해 high-level modeling decision을 해야할 수 있습니다. Components의 수에 대한 선택은 hyperparameter의 한 예이며, 이 선택은 모델의 성능에 상당한 영향을 미칠 수 있습니다. 다른 모델들 중에 선택하는 문제는 model selection이라고 부르며, 이는 8.6장에서 논의합니다. Non-probabilistic models의 경우, model selection은 종종 nested cross-validataion을 사용하여 수행됩니다. 또한, model selection을 사용하여 모델의 hyperparameters를 선택합니다.
이어지는 내용에서는 empirical risk minimization(8.2장), the principle of maximum likelihood(8.3장), probabilistic modeling(8.4장)에 대해 살펴보겠습니다.