Backpropagation and Automatic Differentiation
많은 머신러닝 어플리케이션에서는 gradient descent(7.1장)을 수행하여 모델의 파라미터를 학습합니다. 이는 모델의 파라미터에 대해 learning objective의 gradient를 계산할 수 있다는 사실에 기반합니다. 주어진 목적 함수(objective function)에 대해 미적분과 chain rule을 사용하여 모델의 파라미터에 대한 gradient를 얻을 수 있습니다 (5.2장). 또한 5.3장에서는 linear regression model의 파라미터에 대한 squared loss의 gradient를 맛보기로 살펴봤습니다.
다음의 함수를 살펴봅시다.
\[f(x) = \sqrt{x^2 + \exp(x^2)} + \cos(x^2 + \exp(x^2)) \tag{5.109}\]Chain rule을 적용하면 아래와 같이 gradient를 계산할 수 있습니다.
\[\begin{align*} \frac{\mathrm{d}f}{\mathrm{d}x} &= \frac{2x+2x\exp(x^2)}{2\sqrt{x^2+\exp(x^2)}} - \sin(x^2 + \exp(x^2))(2x+2x\exp(x^2)) \\ &= 2x\left(\frac{1}{2\sqrt{x^2+\exp(x^2)}}-\sin(x^2 + \exp(x^2))\right)(1+\exp(x^2)) \\ \quad \tag{5.110} \end{align*}\]하지만, 이렇게 명시적인 방법으로 gradient를 계산하는 것은 비효율적입니다. 실제로, 주의깊게 설계하지 않으면 함수를 계산하는 것보다 gradient를 계산하는데 훨씬 더 많은 cost가 소모되어 불필요한 overhead가 발생합니다.
Deep Neural Network를 학습하기 위해, backpropagation 알고리즘은 모델의 파라미터에 대한 error function의 gradient를 계산하는데 아주 효율적인 방법입니다.
backpropagation과 chain rule에 대한 조금 더 자세한 내용은 link를 참조하시길 바랍니다 (교재에서 링크된 페이지).
Gradients in a Deep Network
Deep Learning에서는 chain rule이 많이 사용되는데, 딥러닝에서는 함수값(funciton value) $\boldsymbol{y}$ 는 아래와 같이 많은 단계의 함수들의 합성으로 계산됩니다.
\[\boldsymbol{y} = (f_K\circ f_{K-1}\circ\cdots\circ f_1)(\boldsymbol{x}) = f_K(f_{K-1}(\cdots(f_1(\boldsymbol{x}))\cdots)) \tag{5.111}\]여기서 $\boldsymbol{x}$ 는 input(e.g., images), $\boldsymbol{y}$ 는 observations(e.g., class labels) 입니다. 그리고 모든 함수들 $f_i$ ($i=1,\dotsc,K$) 들은 자신만의 파라미터들을 갖습니다.
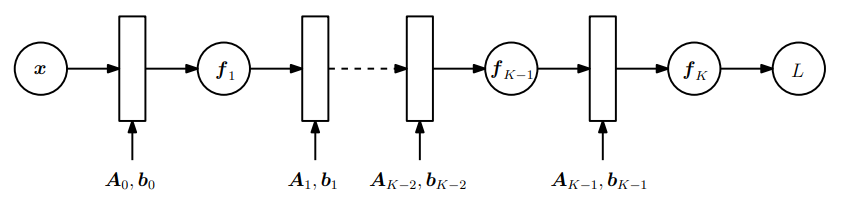
다중 레이어(multiple layers)로 구성된 신경망(neural networks)에서 i번째 레이어는 $f_i(\boldsymbol{x}_{i-1}) = \sigma(\boldsymbol{A}_{i-1}\boldsymbol{x}_{i-1} + \boldsymbol{b}_{i-1})$ 를 가지고 있습니다. 여기서 $\boldsymbol{x}_{i-1}$ 은 i-1 번째 레이어의 output이고, $\sigma$ 는 logistic sigmoid $\frac{1}{1+e^{-x}}, \tanh$ 또는 rectified linear unit(ReLU) 와 같은 activation function 입니다.
이 모델을 학습하려면, 모델의 모든 파라미터 $\boldsymbol{A}_j, \boldsymbol{b}_j$ ($j=1,\dotsc,K$) 에 대한 loss function $L$ 의 gradient가 필요합니다. 또한, 각 레이어의 input에 대한 $L$ 의 gradient를 계산해야 합니다.
만약 input $\boldsymbol{x}$ 와 observation $\boldsymbol{y}$ 가 주어지고 네트워크 구조가 다음과 같이 정의되었을 때 (Figure 5.8 참조),
\[\begin{align*} \boldsymbol{f}_0 &:= \boldsymbol{x} \tag{5.112} \\ \boldsymbol{f}_i &:= \sigma_i(\boldsymbol{A}_{i-1}\boldsymbol{f}_{i-1} + \boldsymbol{b}_{i-1}), \quad i = 1,\dotsc,K \tag{5.113} \end{align*}\]아래의 squared loss를 최소화하는 모델의 파라미터 $\boldsymbol{A}_j, \boldsymbol{b}_j \;(j = 0,\dotsc,K-1)$ 찾는 것이 목표입니다.
\[L(\boldsymbol{\theta}) = \|\boldsymbol{y}-\boldsymbol{f}_K(\boldsymbol{\theta},\boldsymbol{x})\|^2 \tag{5.114}\]위 식에서 파라미터 집합(parameter sets) $\boldsymbol{\theta} = \lbrace\boldsymbol{A}_0,\boldsymbol{b}_0,\dotsc,\boldsymbol{A}_{K-1},\boldsymbol{b}_{K-1}\rbrace$ 입니다.
Parameter set $\boldsymbol{\theta}$ 에 대한 gradients를 계산하려면 각 레이어 $j=0,\dotsc,K-1$ 의 파라미터 $\boldsymbol{\theta}_j=\lbrace\boldsymbol{A}_j,\boldsymbol{b}_j\rbrace$ 에 대한 $L$ 의 partial derivatives를 먼저 계산해야 합니다. Chain rule에 의해 다음과 같이 partial derivatives를 계산할 수 있습니다.
\[\begin{align*} \frac{\partial L}{\partial\boldsymbol{\theta}_{K-1}} &= \frac{\partial L}{\partial\boldsymbol{f}_{K}}\color{blue}{\frac{\partial\boldsymbol{f}_{K}}{\partial\boldsymbol{\theta}_{K-1}}} \tag{5.115} \\ \frac{\partial L}{\partial\boldsymbol{\theta}_{K-2}} &= \frac{\partial L}{\partial\boldsymbol{f}_K}\boxed{\color{orange}{\frac{\partial\boldsymbol{f}_K}{\partial\boldsymbol{f}_{K-1}}}\color{blue}{\frac{\partial\boldsymbol{f}_{K-1}}{\partial\boldsymbol{\theta}_{K-2}}}} \tag{5.116} \\ \frac{\partial L}{\partial\boldsymbol{\theta}_{K-3}} &= \frac{\partial L}{\partial\boldsymbol{f}_K} {\color{orange}\frac{\partial\boldsymbol{f}_{K}}{\partial\boldsymbol{f}_{K-1}}} \boxed{\color{orange}{\frac{\partial\boldsymbol{f}_{K-1}}{\partial\boldsymbol{f}_{K-2}}} \color{blue}{\frac{\partial\boldsymbol{f}_{K-2}}{\partial\boldsymbol{f}_{K-3}}}} \tag{5.117} \\ \frac{\partial L}{\partial\boldsymbol{\theta}_i} &= \frac{\partial L}{\partial\boldsymbol{f}_K} {\color{orange}\frac{\partial\boldsymbol{f}_K}{\partial\boldsymbol{f}_{K-1}}\cdots} \boxed{\color{orange}{\frac{\partial\boldsymbol{f}_{i+2}}{\partial\boldsymbol{f}_{i+1}}} \color{blue}{\frac{\partial\boldsymbol{f}_{i+1}}{\partial\boldsymbol{\theta}_i}}} \tag{5.118} \end{align*}\]위 식에서 주황색으로 표시된 term은 각 레이어에서 input에 대한 output의 partial derivatives이고, 파란색으로 표시된 term은 각 레이어의 파라미터에 대한 output의 partial derivatives 입니다. 이미 partial derivatives $\partial L/\partial\boldsymbol{\theta}_{i+1}$ 을 계산했다고 가정한다면, 대부분의 계산들은 $\partial L/\partial\boldsymbol{\theta}_{i}$ 를 계산할 때 재사용될 수 있습니다. 각 단계에서 추가적으로 계산해야되는 항은 위 식에서 박스로 표시했습니다.
아래 그림은 gradient가 네트워크를 통해 backward로 전달되는 것을 시각화하고 있습니다.

Automatic Differentiation
Backpropagation은 수치해석에서 automatic differentiation 이라고 불리는 일반적인 기법의 특수한 케이스라는 것이 밝혀졌습니다. 여기서 automatic differentiation(자동 미분)은 intermediate variables를 가지고 chain rule을 적용하여 함수의 정확한 gradient를 수치적으로 평가하는 일련의 기법이라고 생각할 수 있습니다. Automatic differentiation은 기본 산술 연산(addition/multiplication)과 기본 함수($\sin,\cos,\exp,\log$)를 적용합니다. 이러한 연산에 chain rule을 적용하여 꽤 복잡한 함수의 gradient를 자동으로 계산할 수 있습니다. Automatic differentiation은 일반적인 컴퓨터 프로그램에 적용되고, forward와 backward mode가 있습니다.
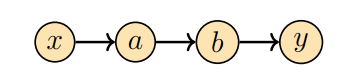
위 그림은 input $x$ 로부터 output $y$ 로의 data flow를 표현하는 간단한 그래프를 보여줍니다. 이 flow는 intermediate variables $a, b$ 를 통해 진행됩니다. 여기서 도함수 $\mathrm{d}y/\mathrm{d}x$ 를 구하려면 chain rule을 적용하여 다음과 같이 계산할 수 있습니다.
\[\frac{\mathrm{d}y}{\mathrm{d}x} = \frac{\mathrm{d}y}{\mathrm{d}b}\frac{\mathrm{d}b}{\mathrm{d}a}\frac{\mathrm{d}a}{\mathrm{d}x} \tag{5.119}\]Forward mode와 reverse mode는 곱셈의 순서가 다릅니다. 행렬 곱셈의 결합 법칙(associativity)에 의해서 우리는 다음과 같이 두 개의 선택지가 있습니다.
\[\begin{align*} \frac{\mathrm{d}y}{\mathrm{d}x} &= \left(\frac{\mathrm{d}y}{\mathrm{d}b}\frac{\mathrm{d}b}{\mathrm{d}a}\right)\frac{\mathrm{d}a}{\mathrm{d}x} \tag{5.120} \\ \frac{\mathrm{d}y}{\mathrm{d}x} &= \frac{\mathrm{d}y}{\mathrm{d}b}\left(\frac{\mathrm{d}b}{\mathrm{d}a}\frac{\mathrm{d}a}{\mathrm{d}x}\right) \tag{5.121} \end{align*}\](5.120)은 gradient가 그래프의 역방향으로 전파되기 때문에 reverse mode 입니다. 즉, data flow의 반대방향으로 전파됩니다. (5.121)은 gradient flow가 그래프를 따라 왼쪽에서 오른쪽으로 전파되므로 forward mode 라고 합니다.
이어서 automatic differentiation의 reverse mode인 backpropagation에 초첨을 맞추어서 살펴보도록 하겠습니다. 일반적으로 신경망에서는 input 차원이 label의 차원보다 훨씬 높기 때문에 reverse mode에서의 연산 cost는 forward mode보다 작습니다. 예시를 통해서 backpropagation에 대해 살펴보도록 하겠습니다.
Example 5.14
다음의 함수를 살펴봅시다.
\[f(x) = \sqrt{x^2 + \exp(x^2)} + \cos(x^2+\exp(x^2)) \tag{5.122}\]만약 위 함수를 컴퓨터에서 구현한다면, intermediate variables를 사용하여 다음과 같이 몇 가지 연산들을 저장할 것입니다.
\[\begin{align*} a &= x^2 \tag{5.123} \\ b &= \exp(a) \tag{5.124} \\ c &= a+b \tag{5.125} \\ d &= \sqrt{c} \tag{5.126} \\ e &= \cos(c) \tag{5.127} \\ f &= d + e \tag{5.128} \end{align*}\]위와 같이 작성하는 것은 chain rule을 적용하는 것과 같은 과정입니다. 이는 방정식 (5.109)를 정의된 대로 직접 구현하는 것보다 훨씬 더 적은 연산량을 갖습니다. 위 그림은 함수값 $f$ 를 얻기 위해 필요한 data와 computation의 flow를 보여주는 computation graph 입니다.
Intermediate variable은 기본 함수와 기본 연산들로 이루어져 있으므로, 기본 함수의 도함수 정의를 호출하여 해당 연산의 입력에 대한 intermediate variable의 도함수를 계산할 수 있습니다. 그 결과는 다음과 같습니다.
\[\begin{align*} \frac{\partial a}{\partial x} &= 2x \tag{5.129} \\ \frac{\partial b}{\partial a} &= \exp(a) \tag{5.130} \\ \frac{\partial a}{\partial a} &= 1 = \frac{\partial c}{\partial b} \tag{5.131} \\ \frac{\partial d}{\partial c} &= \frac{1}{2\sqrt{c}} \tag{5.132} \\ \frac{\partial e}{\partial c} &= -\sin(c) \tag{5.133} \\ \frac{\partial f}{\partial d} &= 1 = \frac{\partial f}{\partial e} \tag{5.134} \end{align*}\]연산 그래프를 살펴보고, output에서부터 역방향으로 계산하여 $\partial f/\partial x$ 를 아래와 같이 계산할 수 있습니다.
\[\begin{align*} \frac{\partial f}{\partial c} &= \frac{\partial f}{\partial d}\frac{\partial d}{\partial c} + \frac{\partial f}{\partial e}\frac{\partial e}{\partial c} \tag{5.135} \\ \frac{\partial f}{\partial b} &= \frac{\partial f}{\partial c}\frac{\partial c}{\partial b} \tag{5.136} \\ \frac{\partial f}{\partial a} &= \frac{\partial f}{\partial b}\frac{\partial b}{\partial a} + \frac{\partial f}{\partial c}\frac{\partial c}{\partial a} \tag{5.137} \\ \frac{\partial f}{\partial x} &= \frac{\partial f}{\partial a}\frac{\partial a}{\partial x} \tag{5.138} \end{align*}\]기본 함수들의 도함수 결과를 대입하면 아래의 결과를 얻을 수 있습니다.
\[\begin{align*} \frac{\partial f}{\partial c} &= 1\cdot\frac{1}{2\sqrt{c}} + 1\cdot(-\sin(c)) \tag{5.139} \\ \frac{\partial f}{\partial b} &= \frac{\partial f}{\partial c}\cdot 1 \tag{5.140} \\ \frac{\partial f}{\partial a} &= \frac{\partial f}{\partial b}\exp(a) + \frac{\partial f}{\partial c}\cdot1 \tag{5.141} \\ \frac{\partial f}{\partial x} &= \frac{\partial f}{\partial a}\cdot 2x \tag{5.142} \end{align*}\]각 도함수를 변수로 생각하면, 도함수를 계산하는데 필요한 연산의 복잡도가 함수 그 자체와 유사하다는 것을 확인할 수 있습니다. 이 함수의 도함수의 식 (5.110)이 함수 식 (5.109) 보다 훨씬 더 복잡하기 때문에 위의 방법을 사용하면 더 직관적으로 적은 연산으로 계산할 수 있습니다.
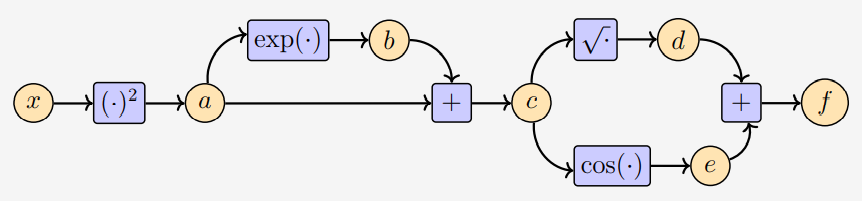
Automatic differentiation은 위에서 살펴본 Example 5.14를 공식화한 것입니다. $x_1, \dotsc, x_d$ 를 함수의 input variables라고 하고, $x_{d+1}, \dotsc, x_{D-1}$ 를 intermediate variables, $x_D$ 를 output variable이라고 두면, computation graph는 다음과 같이 표현됩니다.
\[\text{For } i = d + 1, \dotsc, D : \quad x_i = g_i(x_{P_a(x_i)}) \tag{5.143}\]위 식에서 $g_i(\cdot)$ 은 elementary functions이고 $x_{P_a(x_i)}$ 는 그래프에서 변수 $x_i$ 의 parent nodes 입니다. 이렇게 정의된 함수가 주어졌을 때, chain rule을 사용하여 단계별로 함수의 derivative를 계산할 수 있습니다. $f = x_D$ 라고 정의했으므로 다음이 성립합니다.
\[\frac{\partial f}{\partial x_D} = 1 \tag{5.144}\]그리고 다른 변수들 $x_i$ 에 대해 chain rule을 적용하면,
\[\frac{\partial f}{\partial x_i} = \sum_{x_j:x_i\in P_a(x_j)} \frac{\partial f}{\partial x_j}\frac{\partial x_j}{\partial x_i} = \sum_{x_j:x_i\in P_a(x_j)}\frac{\partial f}{\partial x_j}\frac{\partial g_j}{\partial x_i} \tag{5.145}\]이며, 여기서 $P_a(x_j)$ 는 computation graph에서 $x_j$ 의 parent nodes 집합입니다. 식 (5.143)은 함수의 forward propagation이고, 식 (5.145)는 computation graph를 통한 gradient의 backpropagation 입니다.
Neural network training에서는 label에 대한 prediction의 에러를 역전파합니다.
위에서 살펴본 automatic differentiation은 함수가 computation graph로 표현할 수 있고, elementary functions가 미분가능할 때, 동작합니다. 사실 함수는 수학적인 함수가 아닌 컴퓨터 프로그램일 수 있습니다. 그러나 모든 컴퓨터 프로그램에서 자동 미분이 가능한 것은 아니며, 예를 들면, differential elementary functions을 찾지 못하는 경우가 있습니다. 따라서, for 루프나 if 문과 같이 프로그래밍 구조에서도 많은 주의를 기울여야 합니다.