Gradients of Vector-Valued Functions
5.1장과 5.2장을 통해 실수로 mapping 하는 함수 $f : \mathbb{R}^n \rightarrow \mathbb{R}$ 의 partial derivatives와 gradients에 대해 살펴봤습니다. 이번 장에서는 gradient 개념을 vector-valued function (vector fields) $\boldsymbol{f} : \mathbb{R}^n \rightarrow \mathbb{R}^m$ 으로 일반화해보도록 하겠습니다 ($n\geq1, m>1$).
함수 $\boldsymbol{f} : \mathbb{R}^n\rightarrow\mathbb{R}^m$ 과 vector $\boldsymbol{x} = \lbrack x_1,\dotsc,x_n\rbrack^\top\in\mathbb{R}^n$ 에 대해, 함수값에 대응되는 벡터는 다음과 같이 주어집니다.
\[\boldsymbol{f}(\boldsymbol{x}) = \begin{bmatrix}f_1(\boldsymbol{x}) \\ \vdots \\ f_m(\boldsymbol{x})\end{bmatrix}\in\mathbb{R}^m \tag{5.54}\]이와 같은 방식으로 vector-valued function을 작성하는 것은 함수 $\boldsymbol{f}:\mathbb{R}^n\rightarrow\mathbb{R}^m$ 을 함수들의 벡터 $\lbrack f_1,\dotsc,f_m\rbrack^\top$ 로 볼 수 있으며, $f_i : \mathbb{R}^n\rightarrow \mathbb{R}$ 으로 mapping되는 함수입니다. 모든 $f_i$ 에 대한 differentiation rule은 5.2장에서 논의한 것과 동일합니다.
따라서, $x_i\in\mathbb{R}, i = 1,\dotsc,n$ 에 대한 vector-valued function $\boldsymbol{f}:\mathbb{R}^n\rightarrow\mathbb{R}^m$ 의 partial derivative는 아래의 vector로 주어집니다.
\[\frac{\partial\boldsymbol{f}}{\partial x_i} = \begin{bmatrix}\frac{\partial f_1}{\partial x_i}\\\vdots\\\frac{\partial f_m}{\partial x_i}\end{bmatrix} = \begin{bmatrix}\lim_{h\rightarrow 0} \frac{f_1(x_1,\dotsc,x_{i-1}, x_i+h, x_{i+1},\dotsc,x_n) - f_1(\boldsymbol{x})}{h}\\\vdots\\\lim_{h\rightarrow 0} \frac{f_m(x_1,\dotsc,x_{i-1}, x_i+h, x_{i+1},\dotsc,x_n) - f_m(\boldsymbol{x})}{h}\end{bmatrix} \in \mathbb{R}^m \tag{5.55}\]식 (5.40)으로부터, vector에 대한 $\boldsymbol{f}$ 의 gradient는 partial derivatives의 row vector라는 것을 잘 알고 있습니다. 식 (5.55)에서는 모든 편도함수(partial derivative) $\partial\boldsymbol{f}/\partial x_i$ 는 그 자체로 column vector 입니다. 따라서, $\boldsymbol{x}\in\mathbb{R}^n$ 에 대한 $\boldsymbol{f}:\mathbb{R}^n\rightarrow\mathbb{R}^m$ 의 gradient를 이들의 partial derivative들을 모아서 얻을 수 있습니다.
\[\begin{align*} \frac{\mathrm{d}\boldsymbol{f}(\boldsymbol{x})}{\mathrm{d}\boldsymbol{x}} &= \begin{bmatrix} \boxed{\frac{\partial\boldsymbol{f}(\boldsymbol{x})}{\partial x_1}}&\cdots&\boxed{\frac{\partial \boldsymbol{f}(\boldsymbol{x})}{\partial x_n}}\end{bmatrix} \tag{5.56a} \\ &= \begin{bmatrix}\boxed{\begin{matrix}\frac{\partial f_1(\boldsymbol{x})}{\partial x_1}\\\vdots\\\frac{\partial f_m(\boldsymbol{x})}{\partial x_1}\end{matrix}}&\cdots&\boxed{\begin{matrix}\frac{\partial f_1(\boldsymbol{x})}{\partial x_n}\\\vdots\\\frac{\partial f_m(\boldsymbol{x})}{\partial x_n}\end{matrix}}\end{bmatrix} \in \mathbb{R}^{m\times n} \tag{5.56b} \end{align*}\]Definition 5.6 (Jacobian).
\[\begin{align*} \boldsymbol{J} &= \nabla_{\boldsymbol{x}}\boldsymbol{f} = \frac{\mathrm{d}\boldsymbol{f}(\boldsymbol{x})}{\mathrm{d}\boldsymbol{x}} = \begin{bmatrix}\frac{\partial \boldsymbol{f}(\boldsymbol{x})}{\partial x_1}&\cdots&\frac{\partial\boldsymbol{f}(\boldsymbol{x})}{\partial x_n}\end{bmatrix} \tag{5.57} \\ &= \begin{bmatrix}\frac{\partial f_1(\boldsymbol{x})}{\partial x_1}&\cdots&\frac{f_1(\boldsymbol{x})}{\partial x_n}\\\vdots&&\vdots\\\frac{\partial f_m(\boldsymbol{x})}{\partial x_1}&\cdot&\frac{\partial f_m(\boldsymbol{x})}{\partial x_n}\end{bmatrix} \tag{5.58} \\ \boldsymbol{x} &= \begin{bmatrix}x_1\\\vdots\\x_n\end{bmatrix}, \quad J(i, j) = \frac{\partial f_i}{\partial x_j} \tag{5.59} \end{align*}\]
Vector-valued function $\boldsymbol{f}:\mathbb{R}^n\rightarrow\mathbb{R}^m$ 의 모든 1차 편도함수(first-order partial derivatives)의 collection을 Jacobian이라고 부릅니다. Jacobian $\boldsymbol{J}$ 는 $m\times n$ 행렬이며, 다음과 같이 정의됩니다.Vector $\boldsymbol{x}\in\mathbb{R}^n$ 을 스칼라로 mapping하는 함수 $f:\mathbb{R}^n\rightarrow\mathbb{R}^1$ 은 식 (5.58)의 special case이며, row vector (행렬의 차원이 $1\times n$)를 가지는 Jacobian 입니다 (5.2장 (5.40) 참조).
6.7장의 the change-of-variable method for probability distributions에서 Jacobian이 어떻게 사용되는지 살펴 볼 예정입니다.
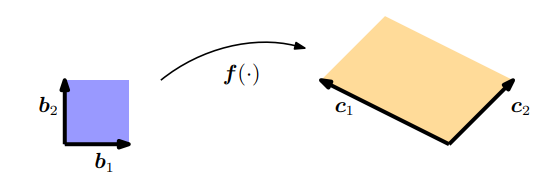
4.1장에서 우리는 determinant가 평행사변형(parallelogram)의 넓이를 계산하는데 사용될 수 있다는 것을 확인했습니다. 만약 두 벡터 $\boldsymbol{b}_1 = \lbrack1, 0\rbrack^\top$ , $\boldsymbol{b}_2 = \lbrack0,1\rbrack^\top$ 가 주어졌을 때, 즉, unit square의 변으로 주어졌을 때, 이 unit square의 넓이는 다음과 같습니다 (Figure 5.5의 왼쪽 사각형).
\[\left| \det\left(\begin{bmatrix}1&0\\0&1\end{bmatrix}\right) \right| = 1 \tag{5.60}\]만약 두 변이 $\boldsymbol{c}_1 =\lbrack-2,1\rbrack^\top, \boldsymbol{c}_2=\lbrack1,1\rbrack^\top$ 으로 주어진 평행사변형이 있으면(Figure 5.5의 오른쪽 사각형), 이 평행사변형의 넓이는 determinant의 절댓값이 됩니다.
\[\left| \det\left(\begin{bmatrix}-2&1\\1&1\end{bmatrix}\right) \right| = |-3| = 3 \tag{5.61}\]따라서, 평행사변형의 넓이는 정확히 unit square의 3배입니다.
여기서 unit square를 다른 square로 변환하는 mapping을 찾음으로서 scaling factor를 찾을 수 있습니다. 선형대수학의 term에서, $(\boldsymbol{b}_1, \boldsymbol{b}_2)$ 에서 $(\boldsymbol{c}_1, \boldsymbol{c}_2)$ 로의 variable transformation은 효과적으로 수행할 수 있습니다. 이 경우 mapping은 linear하며, 이 mapping의 determinant의 절댓값은 scaling factor가 됩니다.
이번 장에서는 이러한 mapping을 찾는 두 가지 접근 방법을 살펴볼 예정입니다. 첫 번째 방법은 2장에서 설명한 내용들을 토대로 찾으려는 mapping이 linear하다는 성질을 활용합니다. 두 번째 방법은 이번 장에서 살펴본 partial derivatives를 활용합니다.
- Approach 1
선형대수학 관점에서 $\lbrace\boldsymbol{b}_1, \boldsymbol{b}_2\rbrace$ 와 $\lbrace\boldsymbol{c}_1, \boldsymbol{c}_2\rbrace$ 를 $\mathbb{R}^2$ 의 bases로 생각할 수 있습니다 (2.6.1장 참고). 여기서 우리가 해야할 것은 $(\boldsymbol{b}_1,\boldsymbol{b}_2)$ 에서 $(\boldsymbol{c}_1,\boldsymbol{c}_2)$ 로의 basis change 이고, 이러한 basis change를 수행하는 transformation matrix를 찾아야 합니다. 2.7.2장의 내용을 토대로, 우리는 $\boldsymbol{Jb}_1 = \boldsymbol{c}_1, \boldsymbol{Jb}_2 = \boldsymbol{c}_2$ 를 만족시키는 basis change matrix를 찾을 수 있습니다.
\[\boldsymbol{J} = \begin{bmatrix}-2&1\\1&1\end{bmatrix} \tag{5.62}\]우리가 찾는 scaling factor인 $\boldsymbol{J}$ 의 determinant의 절댓값은 $|\det(\boldsymbol{J})| = 3$ 으로 주어집니다. 즉, $(\boldsymbol{c}_1,\boldsymbol{c}_2)$ 에 의해 span되는 사각형의 넓이는 $(\boldsymbol{b}_1,\boldsymbol{b}_2)$ 에 의해 span되는 사각형 넓이의 3배 입니다.
- Approach 2
선형대수학 관점의 접근방법은 linear transformation에서 동작합니다. 만약 nonlinear transformation이라면 partial derivative를 사용하는 보다 general한 접근 방법을 사용해야 합니다.
Variable transformation을 수행하는 함수 $\boldsymbol{f}:\mathbb{R}^2\rightarrow\mathbb{R}^2$ 를 고려해보도록 하겠습니다. 이 예제에서 $\boldsymbol{f}$ 는 $(\boldsymbol{b}_1,\boldsymbol{b}_2)$ 에 대한 벡터 $\boldsymbol{x}\in\mathbb{R}^2$ 의 coordinate representation을 $(\boldsymbol{c}_1,\boldsymbol{c}_2)$ 에 대한 coordinate representation $\boldsymbol{y}\in\mathbb{R}^2$ 로 매핑합니다. 여기서 우리는 $\boldsymbol{f}$ 에 의해 변환될 때, 면적(또는 부피)이 어떻게 변하는지 계산하기 위한 mapping을 찾고자 합니다. 이를 위해서 우리는 $\boldsymbol{x}$ 를 약간 변경했을 때 $\boldsymbol{f}(\boldsymbol{x})$ 가 어떻게 변하는지 찾아야 합니다. 이는 Jacobian matrix $\frac{\mathrm{d}\boldsymbol{f}}{\mathrm{d}\boldsymbol{x}}\in\mathbb{R}^{2\times 2}$ 로 알아낼 수 있습니다. 우리는 각 좌표의 변환을 다음과 같이 작성할 수 있기 때문에
\[\begin{align*} y_1 &= -2x_1 + x_2 \tag{5.63} \\ y_2 &= x_1 + x_2 \tag{5.64} \end{align*}\]편도함수(partial derivatives)를 통해 $\boldsymbol{x}$ 와 $\boldsymbol{y}$ 의 함수 관계를 얻을 수 있습니다.
\[\frac{\partial y_1}{\partial x_1} = -2, \quad \frac{\partial y_1}{\partial x_2} = 1, \quad \frac{\partial y_2}{\partial x_1} = 1, \quad \frac{\partial y_2}{\partial x_2} = 1 \tag{5.65}\]그리고 이 결과들을 통해 Jacobian을 다음과 같이 구성할 수 있습니다.
\[\boldsymbol{J} = \begin{bmatrix}\frac{\partial y_1}{\partial x_1}&\frac{\partial y_1}{\partial x_2}\\\frac{\partial y_2}{\partial x_1}&\frac{\partial y_2}{\partial x_2}\end{bmatrix} = \begin{bmatrix}-2&1\\1&1\end{bmatrix} \tag{5.66}\]Jacobian은 우리가 찾고자 하는 coordinate transformation을 나타냅니다. 위 예제처럼 coordinate transformation이 linear하다면 Jacobian은 존재하며, 식 (5.66)은 정확히 식 (5.62)의 basis change matrix와 같습니다.
만약 coordinate transformation이 non-linear하다면, Jacobian은 non-linear transformation을 linear한 것으로 locally하게 근사합니다. Jacobian determinant $|\det(\boldsymbol{J})|$ 는 좌표가 변환될 때, 면적이나 부피가 scaling되는 factor 이며, 위 예제에서는 그 절댓값이 3 이었습니다.
Jacobian determinant와 variable transformations는 6.7장에서 random variables과 probability distribution을 변환할 때와 연관이 있습니다. 이러한 변환은 reparametrization trick (infinite perturbation analysis 라고도 부름)을 사용하여 deep neural network를 학습하는 맥락에서 머신러닝과 관련이 깊습니다.
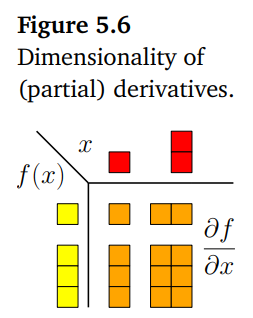
이번 장에서 함수의 derivatives(도함수)에 대해 살펴봤고, 위의 그림은 이러한 도함수의 차원에 대해 간략히 요약하고 있습니다.
함수가 $f : \mathbb{R}\rightarrow\mathbb{R}$ 라면, gradient는 단순히 스칼라 값 입니다(top-left).
$f : \mathbb{R}^{D}\rightarrow\mathbb{R}$ 라면, gradient는 $1\times D$ row vector 입니다 (top-right).
$\boldsymbol{f} : \mathbb{R}\rightarrow\mathbb{R}^{E}$ 라면, gradient는 $E\times 1$ column vector 입니다.
$\boldsymbol{f} : \mathbb{R}^{D} \rightarrow\mathbb{R}^{E}$ 라면, gradient는 $E\times D$ matrix 입니다.
Example 5.9 (Gradient of a Vector-Valued Function)
다음과 같이 주어졌을 때, gradient $\mathrm{d}\boldsymbol{f}/\mathrm{d}\boldsymbol{x}$ 의 gradient를 계산해보도록 하겠습니다.
\[\boldsymbol{f}(\boldsymbol{x}) = \boldsymbol{Ax}, \quad \boldsymbol{f}(\boldsymbol{x}) \in \mathbb{R}^M, \quad \boldsymbol{A}\in\mathbb{R}^{M\times N}, \quad \boldsymbol{x}\in\mathbb{R}^N\]Gradient를 계산하기에 앞서, 먼저 $\mathrm{d}\boldsymbol{f}/\mathrm{d}\boldsymbol{x}$ 의 차원을 결정해야 합니다. $\boldsymbol{f}:\mathbb{R}^N \rightarrow\mathbb{R}^M$ 이므로, gradient의 차원은 $\mathrm{d}\boldsymbol{f}/\mathrm{d}\boldsymbol{x} \in \mathbb{R}^{M\times N}$ 입니다. 이어서 모든 $x_j$ 에 대한 $f$ 의 partial derivatives 를 계산합니다.
\[f_i(\boldsymbol{x}) = \sum_{j=1}^N A_{ij}x_j \Longrightarrow \frac{\partial f_i}{\partial x_j} = A_{ij} \tag{5.67}\]이렇게 계산한 편도함수들을 Jacobian 행렬로 작성하면 gradient를 다음과 같이 얻을 수 있습니다.
\[\frac{\mathrm{d}\boldsymbol{f}}{\mathrm{d}\boldsymbol{x}} = \begin{bmatrix}\frac{\partial f_1}{\partial x_1}&\cdots&\frac{\partial f_1}{\partial x_N}\\\vdots&&\vdots\\\frac{\partial f_M}{\partial x_1}&\cdots&\frac{\partial f_M}{\partial x_N}\end{bmatrix} = \begin{bmatrix}A_{11}&\cdots&A_{1N}\\\vdots&&\vdots\\A_{M1}&\cdots&A_{MN}\end{bmatrix} = \boldsymbol{A} \in \mathbb{R}^{M\times N} \tag{5.68}\]
Example 5.10 (Chain Rule)
다음과 같이 주어지는 함수 $h : \mathbb{R}\rightarrow\mathbb{R}, h(t) = (f\circ g)(t)$ 에서 $t$ 에 대한 $h$ 의 gradient를 계산해보도록 하겠습니다.
\[\begin{align*} f &: \mathbb{R}^2\rightarrow\mathbb{R} \tag{5.69} \\ g &: \mathbb{R}\rightarrow\mathbb{R}^2 \tag{5.70} \\ f(\boldsymbol{x}) &= \exp(x_1x_2^2) \tag{5.71} \\ \boldsymbol{x} &= \begin{bmatrix}x_1\\x_2\end{bmatrix} = g(t) = \begin{bmatrix}t\cos t\\t\sin t\end{bmatrix} \tag{5.72} \end{align*}\]$f:\mathbb{R}^2\rightarrow\mathbb{R}$ 이고, $g : \mathbb{R}\rightarrow\mathbb{R}^2$ 이므로, 다음과 같이 편도함수의 차원을 결정할 수 있습니다.
\[\frac{\partial f}{\partial \boldsymbol{x}} \in\mathbb{R}^{1\times2}, \quad \frac{\partial g}{\partial t}\in\mathbb{R}^{2\times1} \tag{5.73}\]구하고자 하는 gradient는 다음과 같이 chain rule을 적용하여 계산할 수 있습니다.
\[\begin{align*} \frac{\mathrm{d}h}{\mathrm{d}t} &= {\color{blue}\frac{\partial f}{\partial \boldsymbol{x}}}\color{orange}{\frac{\partial \boldsymbol{x}}{\partial t}} = \color{blue}{\begin{bmatrix}\frac{\partial f}{\partial x_1}&\frac{\partial f}{\partial x_2}\end{bmatrix}}\color{orange}{\begin{bmatrix}\frac{\partial x_1}{\partial t}\\\frac{\partial x_2}{\partial t}\end{bmatrix}} \tag{5.74a} \\ &= \color{blue}{\begin{bmatrix}\exp(x_1x_2^2)x_2^2&2\exp(x_1x_2^2)x_1x_2\end{bmatrix}}\color{orange}{\begin{bmatrix}\cos t - t\sin t\\\sin t + t\cos t\end{bmatrix}} \tag{5.74b} \\ &= \exp(x_1x_2^2)(x_2^2(\cos t - t\sin t) + 2x_1x_2(\sin t + t\cos t)) \tag{5.74c} \end{align*}\]($x_1 = t\cos t, \quad x_2 = t\sin t$)
Example 5.11 (Gradient of a Least-Squares Loss in a Linear Model)
$\boldsymbol{\theta}\in\mathbb{R}^D$ 가 parameter vector, $\boldsymbol{\Phi}\in\mathbb{R}^{N\times D}$ 가 input features, 그리고 $\boldsymbol{y}\in\mathbb{R}^{N}$ 이 대응되는 observations(관측치) 일 때, 다음의 linear model에 대해 살펴보도록 하겠습니다 (9장에서 조금 더 자세히 다룹니다).
\[\boldsymbol{y} = \boldsymbol{\Phi\theta} \tag{5.75}\]여기서 다음의 함수들을 정의합니다.
\[\begin{align*} L(\boldsymbol{e}) &:= \|\boldsymbol{e}\|^2 \tag{5.76} \\ \boldsymbol{e}(\boldsymbol{\theta}) &:= \boldsymbol{y} - \boldsymbol{\Phi\theta} \tag{5.77} \end{align*}\]이때, $\frac{\partial L}{\partial\boldsymbol{\theta}}$ 를 찾는데, 이를 위해서 chain rule을 사용합니다. 여기서 $L$ 을 least-squares loss function이라고 부릅니다.
미분을 하기 전에, 먼저 gradient의 차원을 결정합니다.
\[\frac{\partial L}{\partial \boldsymbol{\theta}} \in \mathbb{R}^{1\times D} \tag{5.78}\]Chain rule을 적용하면, gradient를 다음과 같이 표현할 수 있습니다.
\[\frac{\partial L}{\partial\boldsymbol{\theta}} = \color{blue}{\frac{\partial L}{\partial\boldsymbol{\boldsymbol{e}}}}\color{orange}{\frac{\partial \boldsymbol{e}}{\partial\boldsymbol{\theta}}} \tag{5.79}\]여기서 d번째 element는 다음과 같이 주어집니다.
\[\frac{\partial L}{\partial\boldsymbol{\theta}}\lbrack1, d\rbrack = \sum_{n=1}^N \frac{\partial L}{\partial\boldsymbol{e}}\lbrack n\rbrack\frac{\partial\boldsymbol{e}}{\partial\boldsymbol{\theta}}\lbrack n,d\rbrack \tag{5.80}\]$\|\boldsymbol{e}\|^2 = \boldsymbol{e}^\top\boldsymbol{e}$ 이므로,
\[{\color{blue}\frac{\partial L}{\partial\boldsymbol{e}} = 2\boldsymbol{e}^\top} \in \mathbb{R}^{1\times N} \tag{5.81}\]이고, 다음의 결과도 얻을 수 있습니다.
\[{\color{orange}\frac{\partial\boldsymbol{e}}{\partial\boldsymbol{\theta}} = -\boldsymbol{\Phi}} \in\mathbb{R}^{N\times D} \tag{5.82}\]따라서, 구하고자 하는 gradient는 다음과 같이 계산됩니다.
\[\frac{\partial L}{\partial\boldsymbol{\theta}} = {\color{orange}-}{\color{blue}2\boldsymbol{e}^\top}{\color{orange}\boldsymbol{\Phi}} \overset{(5.77)}{=} {\color{orange}-}\underbrace{ {\color{blue}2(\boldsymbol{y}^\top - \boldsymbol{\theta}^\top\boldsymbol{\Phi}^\top)}}_{1\times N}\underbrace{ {\color{orange}\boldsymbol{\Phi}}}_{N\times D} \in \mathbb{R}^{1\times D} \tag{5.83}\]Remark. Chain rule을 사용하지 않고도 다음의 식으로 동일한 결과를 바로 얻을 수 있습니다.
\[L_2(\boldsymbol{\theta}) := \|\boldsymbol{y}-\boldsymbol{\Phi\theta}\|^2 = (\boldsymbol{y}-\boldsymbol{\Phi\theta})^\top(\boldsymbol{y}-\boldsymbol{\Phi\theta}) \tag{5.84}\]다만, 이러한 접근 방식은 $L_2$ 와 같이 간단한 함수에서는 효과적이지만, deep function compositions에서는 실용성이 없습니다.