Model Selection
머신러닝에서는 보통 모델의 성능에 결정적으로 영향을 끼칠 수 있는 고수준의 모델링 결정을 필요로 합니다. 우리가 수행하는 이 선택(e.g., the functional form of the likelihood)은 모델의 free parameters의 수나 타입에 영향을 미치므로 모델의 유연성과 표현성에 영향을 주게 됩니다. 더 복잡한 모델은 더 많은 datasets을 설명하는데 사용될 수 있다는 점에서 더 유연합니다. 예를 들어 1차 다항식(line $y=a_0+a_1x$) 은 input $x$ 와 관측값 $y$ 간의 선형 관계만 묘사하는데 사용될 수 있습니다. 2차 다항식은 input과 observationa 간의 2차 관계를 추가로 설명할 수 있습니다.
매우 유연한 모델이 더 많은 것들을 표현하므로 단순한 모델보다 일반적으로 더 선호된다고 생각할 수 있습니다. 일반적인 문제는 학습할 때, 오직 training set만을 사용하여 모델의 성능을 평가하거나 파라미터를 학습할 수 있다는 것입니다. 그러나 training set의 성능은 우리가 실제로 관심이 있는 부분이 아닙니다. 8.3장에서 MLE(maximum likelihood estimation)이 과적합(overfitting)을 유발할 수 있다는 것을 확인했습니다. 이상적으로 우리의 모델은 test set 에서도 잘 동작해야 합니다. 그러므로, 우리는 이전에 관측하지 못한 데이터들에 대해서 모델이 어떻게 일반화 하는지 평가하는 몇 가지 메커니즘이 필요합니다. 모델 선택(model selection)은 정확히 이 문제와 관련이 있습니다.
Nested Cross-Validation
이미 8.2.4장에서 모델 선택에 사용할 수 있는 접근 방식인 cross-validation(교차 검증)에 대해 살펴봤습니다. 교차 검증은 dataset을 training sets와 validation sets으로 반복적으로 분할하면서 generalization error를 추정합니다. 이러한 교차 검증의 아이디어를 한 번 더 적용할 수 있습니다. 즉, 각 분할에 대해, 교차 검증의 다른 라운드를 수행할 수 있습니다. 이는 보통 nested cross-validation 이라고 부르며, 아래 그림에서 잘 보여주고 있습니다.
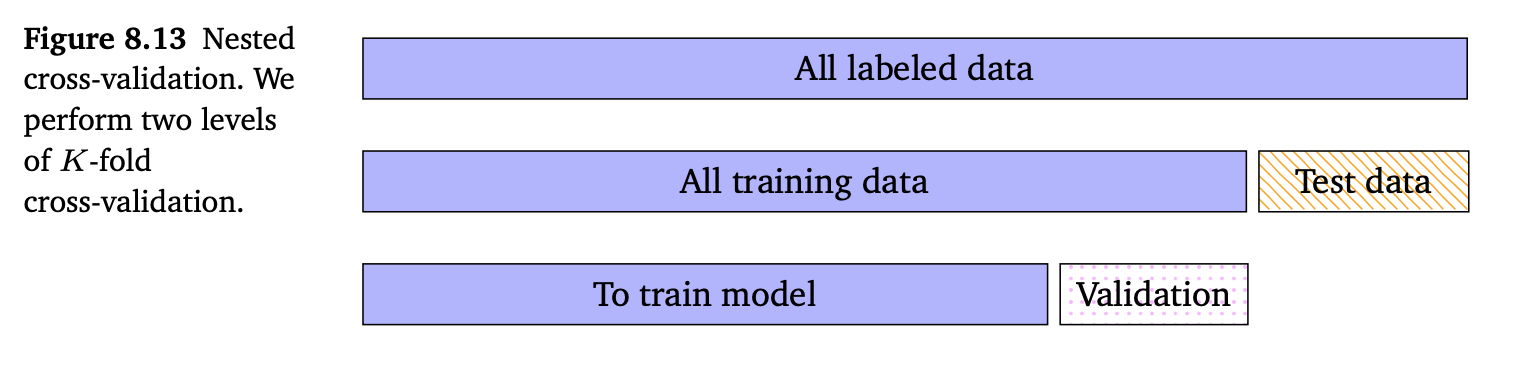
Inner level은 선택된 특정 모델의 성능을 추정하거나 내부 validation set에 대해 하이퍼파라미터의 성능을 추정하는데 사용됩니다. Outer level에서는 선택한 최상의 모델에 대한 generalization 성능을 추정하는데 사용됩니다. 내부 루프에서는 다양한 모델과 하이퍼파라미터에 대해 테스트할 수 있습니다. 두 level을 구분하기 위해서 generalization 성능을 추정하는데 사용되는 데이터 집합을 test set 이라고 부르고, 최상의 모델을 선택하는데 사용되는 데이터 집합을 validation set 이라고 부릅니다. Inner 루프는 validation set에 대한 empirical error를 사용하여 근사하는 방식으로 주어진 모델에 대한 generalization error의 기댓값을 추정합니다. 즉, 다음의 식과 같습니다.
\[\mathbb{E}_{\mathcal{V}}[\bold{R}(\mathcal{V}|M)] \approx \frac{1}{K}\sum_{k=1}^K\bold{R}(\mathcal{V}^{(k)}|M) \tag{8.39}\]위 식에서 $\bold{R}(\mathcal{V}|M)$ 은 모델 $M$ 에서 validation set $\mathcal{V}$ 에 대한 empirical risk(e.g., root mean square error) 입니다.
모든 모델에 대해 이 절차를 반복하고 가장 성능이 좋은 모델을 선택합니다. 교차 검증은 expected generalization error를 제공할 뿐만 아니라, standard error, 평균 추정치가 얼마나 불확실한지에 대한 추정 등의 high-order statistics 도 얻을 수 있습니다. 모델이 선택되면 test sets에 대해 최종 성능을 평가할 수 있습니다.
Bayesian Model Selection
모델 선택에는 여러가지 접근 방식이 있으며, 그 중 일부분을 이번 섹션에서 다루도록 합니다. 일반적으로 이러한 접근 방법들은 모두 모델의 복잡성과 데이터의 적합성 사이를 절충하려고 합니다. 단순한 모델이 복잡한 모델보다 과적합될 확률이 적다고 가정하므로, 모델 선택의 목적은 데이터를 잘 설명하는 가장 간단한 메돌을 찾는 것입니다. 이 개념은 Occam’s razor 라고 알려져있습니다.
모델의 우선순위를 더 단순한 모델로 고려할 수 있습니다. 하지만 이렇게 할 필요는 없습니다. Bayesian probability를 적용하면 “automatic Occam’s Razor”이 정량적으로 구현됩니다. 아래 Figure 8.14는 복잡하고 매우 표현력이 높은 모델이 주어진 datasets $\mathcal{D}$ 를 모델링하는데 가능성이 낮다고 판단될 수 있는 직관을 제공합니다.
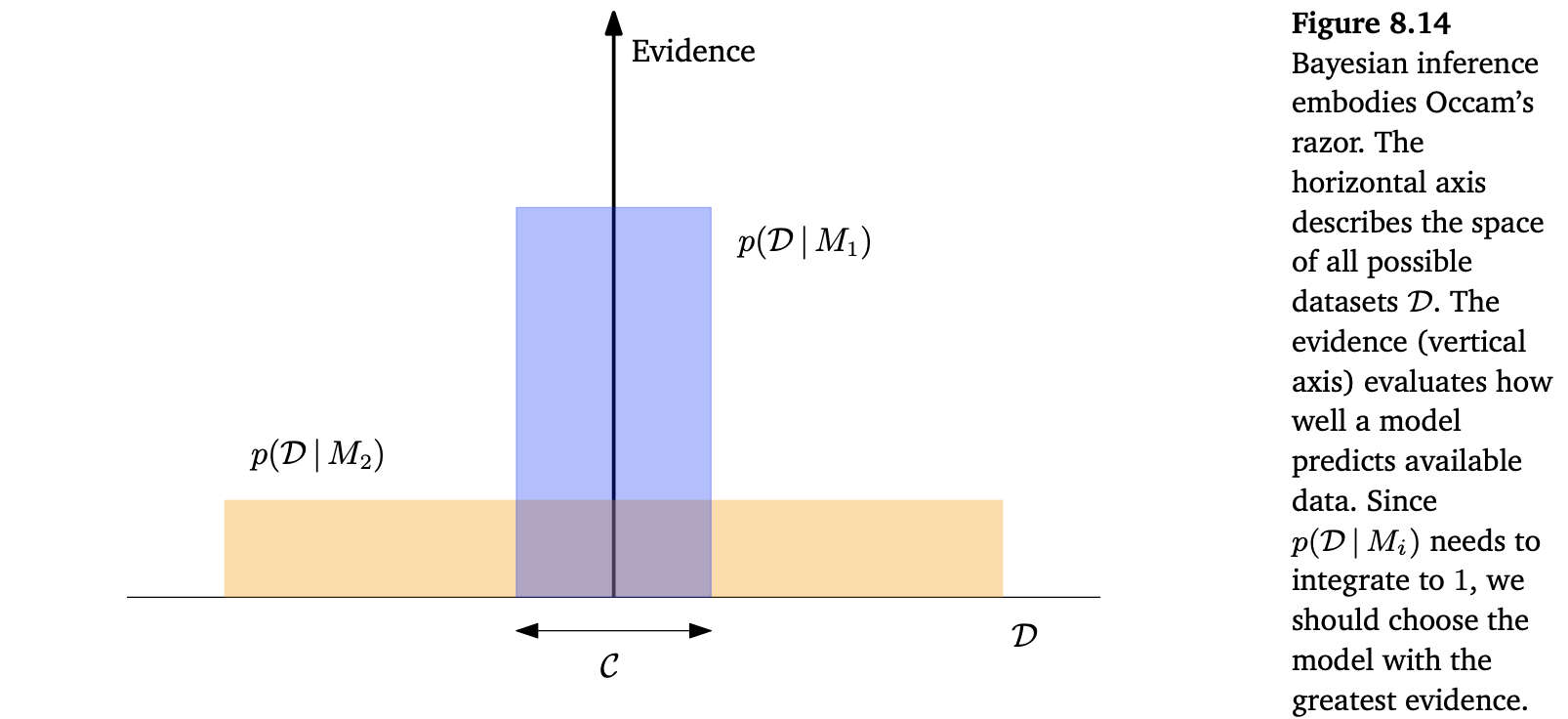
가능한 모든 dataset $\mathcal{D}$ 의 공간을 표현하는 가로 축을 생각해봅시다. 데이터 $\mathcal{D}$ 가 주어졌을 때 모델 $M_i$ 의 사후 확률(posterior probability) $p(M_i|\mathcal{D})$ 에 관심이 있다면, 베이즈 정리(Bayes’ theorem)을 사용할 수 있습니다. 모든 모델에 대해 동일한 사전 확률(uniform prior) $p(M)$ 을 가정하면, 베이즈 정리는 모델들이 얼마나 예측했느냐의 비율에 따라 순위를 매깁니다. 주어진 모델 $M_i$ 에서 데이터의 예측은 $M_i$ 에 대한 evidence 라고 부릅니다. 간단한 모델 $M_1$ 은 작은 수의 datasets만 예측할 수 있고, 이는 $p(\mathcal{D}|M1)$ 으로 보여줍니다. 더 강력한 모델 $M_2$ , 즉, $M_1$ 보다 파라미터가 더 많은 모델은 더 다양한 datasets를 예측할 수 있습니다. 그러나 이는 $M_2$ 가 $M_1$ 처럼 $C$ 영역의 datasets을 예측하지 못한다는 것을 의미합니다. 두 모델에 대해 동일한 사전 확률이 할당되었다고 가정해봅시다. 그런 다음 datasets가 $C$ 영역에 속한다면 덜 강력한 모델인 $M_1$ 이 더 가능성이 있는 모델입니다.
이번 챕터의 앞부분에서 우리는 모델이 데이터를 설명할 수 있어야 한다고 말헀습니다. 즉, 주어진 모델에서 데이터를 생성하는 방법이 있어야 합니다. 또한, 만약 모델이 데이터로부터 적절하게 학습된 경우, 생성된 데이터는 경험적 데이터(empirical data)와 유사해야 합니다. 이를 위해 모델 선택(model selection)을 계층적 추론 문제(hierarchical inference problem)로 표현하는 것이 도움이 됩니다. 이를 통해 모델의 사후 분포를 계산할 수 있습니다.
유한한 수의 모델 $M={M_1,\dotsc,M_k}$ 가 있다고 가정합시다. 여기서 각 모델 $M_k$ 는 파라미터 $\boldsymbol{\theta}_K$ 를 가지고 있습니다. Bayesian model selection 에서, 우리는 모델 집합에 대한 사전 확률 $p(M)$ 을 설정합니다. 이 모델에서 데이터를 생성할 수 있는 대응되는 generative process 는 다음과 같습니다.
\[\begin{align*} M_k &\sim p(M) \tag{8.40} \\ \boldsymbol{\theta}_k &\sim p(\boldsymbol{\theta}|M_k) \tag{8.41} \\ \mathcal{D} &\sim p(\mathcal{D}|\boldsymbol{\theta}_k) \tag{8.42} \end{align*}\]이를 아래 그림에서 설명하고 있습니다.
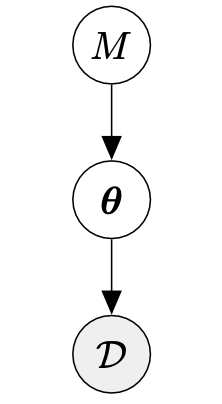
Training set $\mathcal{D}$ 가 주어지면, 베이즈 정리를 적용하고 모델에 대한 사후 분포를 다음과 같이 계산합니다.
\[p(M_k|\mathcal{D}) \propto p(M_k)p(\mathcal{D}|M_k) \tag{8.43}\]이 사후 확률은 더 이상 모델의 파라미터 $\boldsymbol{\theta}_k$ 에 의존하지 않는다는 것에 주목합니다. 이는 다음의 식의 적분으로 계산되기 때문입니다.
\[p(\mathcal{D}|M_k) = \int p(\mathcal{D}|\boldsymbol{\theta}_k)p(\boldsymbol{\theta}_k|M_k)\mathrm{d}\boldsymbol{\theta}_k \tag{8.44}\]위 식에서 $p(\boldsymbol{\theta}_k|M_k)$ 는 모델 $M_k$ 의 파라미터 $\boldsymbol{\theta}_k$ 에 대한 사전 확률입니다. 식 (8.44)를 model evidence or marginal likelihood 라고 지칭합니다. (8.43)의 사후 확률로부터, 우리는 MAP 추정을 할 수 있습니다.
\[M^{\ast} = \arg\max_{M_k} p(M_k|\mathcal{D}) \tag{8.45}\]모든 모델이 선택될 확률이 동일한 사전 확률 uniform prior $p(M_k)=\frac{1}{K}$ 에서, 모든 모델에 대한 MAP estimate은 model evidence (8.44)를 최대화하는 모델을 선택하는 것과 같습니다.
Bayes Factors for Model Comparison
주어진 Datasets $\mathcal{D}$ 에서, 두 확률적 모델(probabilistic models) $M_1, M_2$ 를 비교하는 문제를 고려해보겠습니다. 두 사후 확률 $p(M_1|\mathcal{D})$ 와 $p(M_2|\mathcal{D})$ 를 계산하면, 사후 확률의 비를 계산할 수 있습니다.
\[\underbrace{\frac{p(M_1|\mathcal{D})}{p(M_2|\mathcal{D})}}_{\text{posterior odds}} = \frac{\frac{p(\mathcal{D}|M_1)p(M_1)}{p(\mathcal{D})}}{\frac{p(\mathcal{D}|M_2)p(M_2)}{p(\mathcal{D})}} = \underbrace{\frac{p(M_1)}{p(M_2)}}_{\text{prior odds}}\underbrace{\frac{p(\mathcal{D}|M_1)}{p(\mathcal{D}|M_2)}}_{\text{Bayes factor}} \tag{8.46}\]사후 확률의 비를 posterior odds 라고도 부릅니다. (8.46) 식의 우항의 첫 번째 항은 prior odds 이며, 이는 우리의 사전 믿음(prior beliefs)이 $M_2$ 보다 $M_1$ 을 얼마나 선호하는지 측정합니다. Marginal likelihoods(우항의 두 번째 항)은 Bayes factor 라고 하며, $M_2$ 와 비교했을 때 $M_1$ 이 데이터 $\mathcal{D}$ 를 얼마나 잘 예측하는지 측정합니다.
만약 모델에 대해 uniform prior를 선택했다면, (8.46) 식에서의 prior odds 항은 1 입니다. 즉, posterior odds는 marginal likelihoods(Bayes factor)의 ratio 입니다.
\[\frac{p(\mathcal{D}|M_1)}{p(\mathcal{D}|M_2)} \tag{8.47}\]8장에서는 머신러닝의 기본적인 개념에 대해서 살펴봤습니다. 나머지 챕터에서는 8.2, 8.3, 8.4장에서 살펴본 세 가지 학습 유형이 머신러닝의 4가지 기둥(regression, dimensionality reduction, density estimation, classification)에서 어떻게 적용되는지 살펴봅니다.