Intro
이번 챕터에서는 2,5,6,7장에서 살펴봤던 개념들을 적용하여 linear regression(curve fitting) 문제를 풀어볼 것 입니다. Regression 에서는 input $\boldsymbol{x}\in\mathbb{R}^D$ 를 대응되는 함수 값 $f(\boldsymbol{x})\in\mathbb{R}$ 에 매핑하는 함수 $f$ 를 찾는 것이 목적입니다.
Training inputs $\boldsymbol{x}_n$ 의 집합과 대응되는 noisy observations $y_n = f(\boldsymbol{x}_n) + \epsilon$ 이 주어졌다고 가정해보겠습니다. 여기서 $\epsilon$ 은 i.i.d.인 확률 변수이며 measurement/observation noise를 설명하고 잠재적으로 모델링되지 않은 프로세스 입니다. 이번 챕터에서는 이를 zero-mean Gaussian noise라고 가정합니다. 우리가 해야될 것은 training data를 모델링하는 것 뿐만아니라 training data에 속하지 않는 데이터에서도 함수 값을 잘 예측하도록 일반화된 함수를 찾는 것 입니다.
이러한 regression 문제를 아래 Figure 9.1에서 잘 보여주고 있습니다.
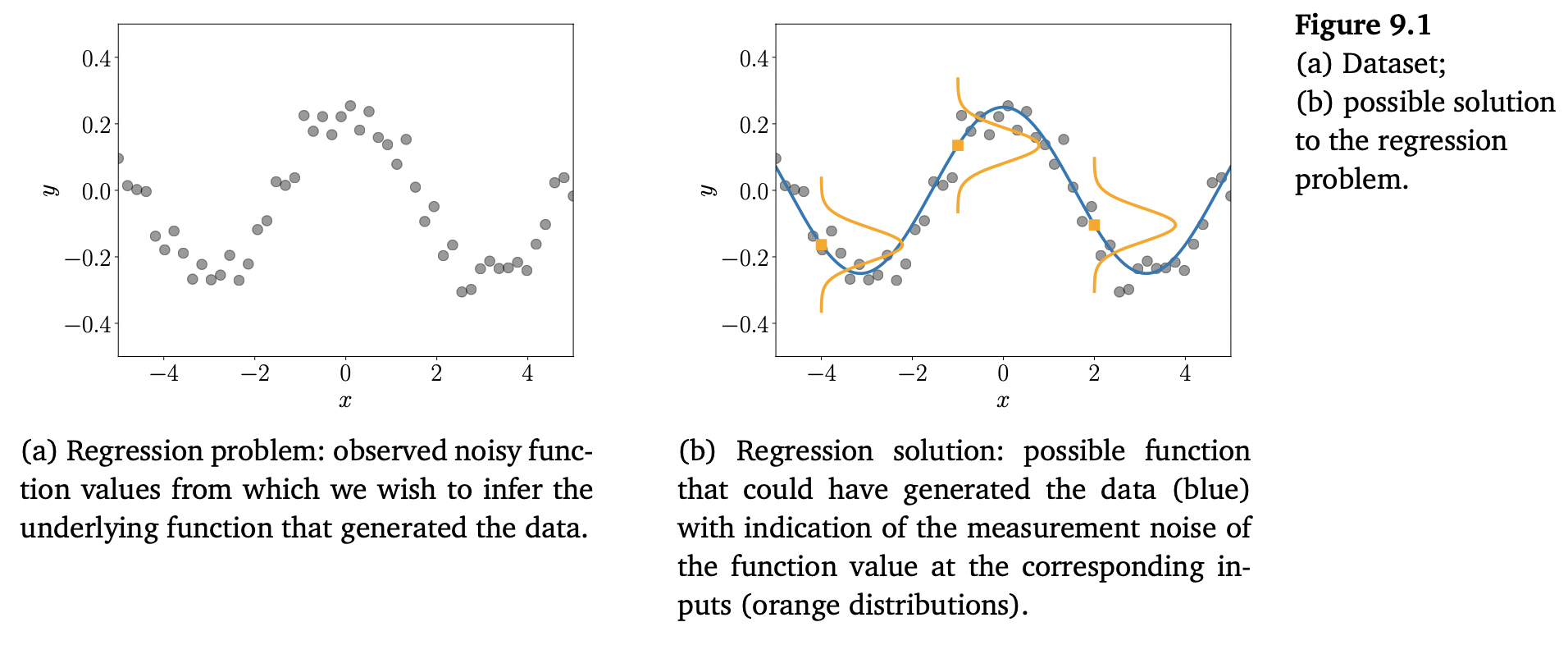
일반적인 regression setting은 Figure 9.1(a) 입니다. 어떤 입력 값 $x_n$ 에 대해, 우리는 (noisy) 함수 값 $y_n = f(x_n) + \epsilon$ 을 관측합니다. 이 작업은 데이터를 생성하고, 새로운 input에서 함수 값을 잘 일반화하는 함수 $f$ 를 추론하는 것입니다. 가능한 solution을 Figure 9.1(b)에서 보여줍니다. 여기서 데이터의 노이즈를 나타내는 세 분포를 함수 값 $f(x)$ 를 중심으로 표현되고 있습니다.
Regression은 머신러닝에서 근본적인 문제이며 다양한 연구 분야와 응용 분야에서 적용됩니다. 해당 분야에는 시계열 분석(e.g., system identification), control and robotics(e.g., 강화학습, forward/inverse model learning), 최적화(e.g., line searches, global optimization), 딥러닝 분야(e.g., computer games, speech-to-text translation, image recognition, automatic video annotation)가 있습니다. 또한, regression은 분류(classification) 알고리즘의 핵심이기도 합니다.
Regression function을 찾으려면 아래의 내용들을 포함하는 다양한 문제를 해결해야 합니다.
-
Choice of the model (type) and the parametrization of the regression functions.
주어진 dataset에서, 어떤 함수 클래스(e.g., polynomials) 가 데이터를 모델링하는데 좋은 후보군일까요? 그리고 어떤 특정 파라미터화(e.g., degree of the polynomial)을 선택해야 할까요? 8.6장에서 다루었던 model selection을 통해 다양한 모델을 비교하고 해당하는 training data를 가장 합리적으로 잘 설명하는 간단한 모델을 찾을 수 있습니다.
-
Finding good parameters.
Regression function의 모델을 선택한 후, good model parameters를 어떻게 찾을 수 있을까요? 여기서 우리는 다양한 loss/objective functions와 이 loss를 최소화할 수 있는 최적화 알고리즘들을 살펴봐야 합니다.
-
Overfitting and model selection.
과적합은 regression function이 training data에 ‘너무 잘’ 적합하여, 새로운 데이터에 일반화되지 않는 문제입니다. 과적합을 일반적으로 모델(or its parametrization)이 너무 유연하고 표현력이 좋아서 발생합니다 (8.6장 참조). 여기서 근본적인 원인을 살펴보고 linear regression 측면에서 과적합을 완화하는 방법에 대해 논의할 예정입니다.
-
Relationship between loss functions and parameter priors.
Loss functions (optimization objectives)는 보통 확률 모델에 의해 결정되고 유도됩니다. 이러한 losses를 유도하는 Loss functions와 기본 prior assumptions 간의 connection을 살펴보도록 하겠습니다.
-
Uncertainty modeling.
실제 세팅에서, 모델 클래스와 대응되는 파라미터를 선택하기 위해서 유한하고 잠재적으로 많은 양의 (training) data에만 액세스할 수 있습니다. 이 유한한 training data가 가능한 모든 시나리오를 커버하지 않는다는 점을 감안할 때, 모델 예측의 신뢰도를 측정하기 위해서 테스트할 때 나머지 매개변수의 불확실성을 설명할 수 있습니다. Training set이 작으면 작을수록 이러한 불확실성 모델링은 중요합니다. 불확실성이 일관적인 모델은 모델 예측에 있어서 신뢰 범위(confidence bounds)를 제공합니다.
이번 장을 통해서 파트1에서 사용하던 수학적 도구들을 사용하여 linear regression 문제를 해결해보려고 합니다. 그리고 최적의 모델의 파라미터를 찾기 위해 maximum likelihood(ML)와 maximum a posteriori(MAP) 추정에 대해서도 논의합니다. 이 장의 끝에서는 Bayesian linear regression에 대해서 논의합니다. 이를 통해 모델 파라미터에 대해 더 높은 수준의 추론을 가능하게 하므로, MLE 또는 MAP 에서 발생하는 문제 중 일부를 해결할 수 있습니다.